组成原理
在计算机科学中,组成原理通常指的是计算机系统的基本组成部分,比如主板 (Motherboard)、中央处理器(CPU)、存储器(内存)、输入/输出设备等,并且涉及到它们之间的连接和交互。本节主要介绍一下PC和手机的组成部件,以及它们的作用。
PC
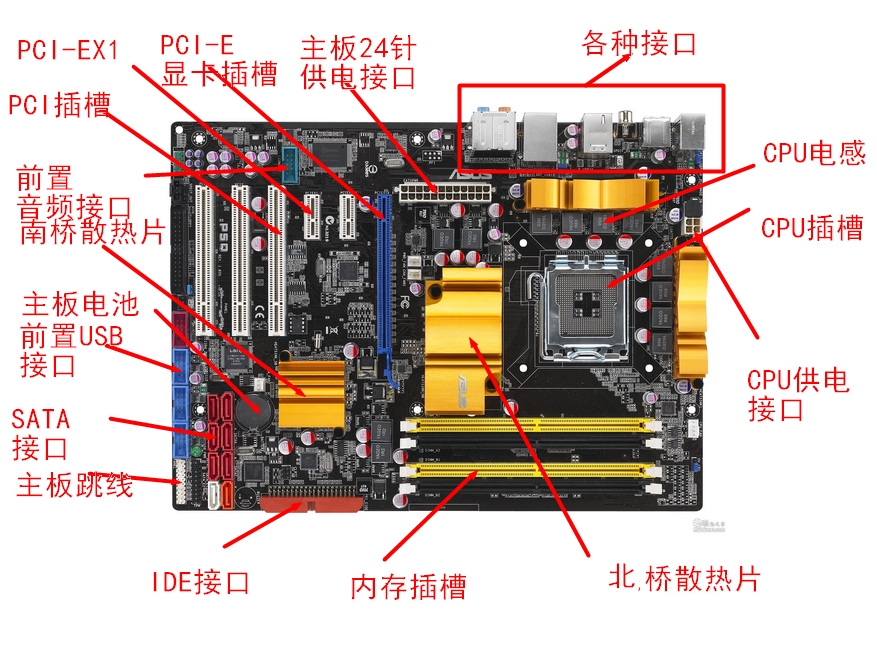
主板 (Motherboard)
主板 (Motherboard)主要由BIOS、总线、扩展插槽、芯片组和I/O端口等组成。
BIOS
BIOS(Basic Input/Output System)是计算机系统中的一个重要组成部分,它是一组固化在计算机主板上的软件程序,负责在计算机启动时初始化硬件设备、进行自检(POST,Power-On Self-Test)、加载操作系统等关键任务。下面是对BIOS的详细介绍:
- 功能:
- 初始化硬件:BIOS负责初始化计算机中的各种硬件设备,包括处理器、内存、硬盘、显卡、键盘、鼠标等。
- 自检(POST):在计算机开机时,BIOS会进行自检,检测系统中各个硬件设备是否正常工作。
- 提供基本输入/输出功能:BIOS提供了基本的输入/输出功能,使得计算机能够与外部设备(如键盘、显示器、存储设备)进行通信。
- 启动操作系统:BIOS负责在计算机启动时加载操作系统的启动程序,将控制权转交给操作系统,使其能够运行。
- 存储位置:
- BIOS通常存储在计算机主板上的闪存芯片中,这种闪存通常被称为“BIOS芯片”或“CMOS芯片”。
- 在一些早期的计算机中,BIOS可能存储在EEPROM(Electrically Erasable Programmable Read-Only Memory)芯片或ROM芯片中。
- 用户界面:
- 传统的BIOS具有文本界面,用户可以通过键盘输入命令来配置和管理BIOS设置。
- 近年来,随着UEFI(Unified Extensible Firmware Interface,统一可扩展固件接口)的普及,许多计算机开始使用UEFI BIOS,它提供了更现代化和图形化的用户界面,使得用户能够更直观地进行设置和配置。
总线
一台电脑由多个电子元器件组成,如CPU,内存,硬盘等,各元器件之间往往需要相互传递数据。 数据传输的公用通道,就是总线。 区分总线承载能力的名词叫带宽,也就是单位时间内能传输的数据量。 常见的总线(通道)有SATA和PCIe。
- SATA总线常见的就是SATA3.0,理论最高速度只有6Gbps,此类接口的固态硬盘理论传输速度为600M/s;
- PCIe总线参见的有PCIe3.0和PCIe4.0,通道数量不同,速度也会不同。以PCIe3.0x4通道总线来说,它的带宽高达32Gbps,此类接口的固态硬盘实际传输速度可以轻松突破1000MB/s,顶级产品甚至可以达到4000MB/s以上; 综上,同为固态硬盘,走的是哪种总线,至关重要。
协议
有了传输的通道, 那么就要定义传输通道将如何传输数据,这种传输数据的规则就叫协议。 目前,硬盘常用的协议,主要有AHCI和NVMe两种。 NVMe与AHCI都是逻辑设备接口的一种标准,不过NVMe相比AHCI在延时性、功耗、IPOS等一些方面性能要强。 不过,并非是说NVMe协议的固态硬盘一定比AHCI协议的速度快,具体的速度还要看走的是哪种总线,以及硬盘本身的性能。
接口
最后,我们来看一下固态硬盘的接口。 上面谈到的总线和协议,都是看不见摸不着的理论,因此,我们需要物理层面的接口,将硬盘与电脑连接起来。 最常见的硬盘接口,主要是SATA接口以及M.2接口。
- SATA接口,主流硬盘接口之一,是Serial ATA的缩写,即串行ATA。它是一种电脑总线,主要功能是用作主板和大量存储设备(如硬盘及光盘驱动器)之间的数据传输。
- M.2接口,又称为NGFF(老名字),是新一代接口标准,拥有比SATA接口更小的尺寸,同时提供更高的传输性能。按金手指的类型,M.2接口又细分为M-Key和B-Key,B&M-Key。
芯片组
在早期的计算机主板中,北桥和南桥是两个独立的芯片,它们分别负责不同的任务。北桥芯片主要负责与处理器、内存和显卡之间的通信,而南桥芯片则负责与硬盘、USB设备和其他低速设备之间的通信。然而,随着技术的发展,现代计算机主板上已经不再使用北桥和南桥这两个独立的芯片了。取而代之的是将它们集成到单一的芯片组中,例如Intel的Z系列芯片组。 这种集成设计使得处理器、内存、显卡、硬盘、USB设备和其他设备之间的通信更加高效和可靠。通过将北桥和南桥的功能集成到单一芯片组中,主板制造商可以更好地控制硬件的兼容性和性能,同时也可以减少主板上的芯片数量,降低成本和功耗。 虽然北桥和南桥的概念已经逐渐被淘汰,但在一些特殊情况下,仍然需要使用到南桥芯片。例如,某些高级的USB设备可能需要直接与南桥芯片通信,因此在一些高端主板上仍然保留了南桥芯片。但是,这些南桥芯片的功能通常已经被大大简化,只负责一些基本的输入/输出任务。 总之,现代计算机主板上已经不再使用北桥和南桥这两个独立的芯片了。取而代之的是将它们集成到单一的芯片组中,这种设计使得硬件的兼容性和性能得到更好的保障,同时也可以降低成本和功耗。
中央处理器 (CPU)
中央处理器(CPU)是计算机系统中最重要的组件之一,其性能和功能直接影响到计算机的运行速度和能力。以下是CPU的主要参数:
- 核心数量(Cores):
- CPU的核心数量指的是处理器内部包含的独立处理单元的数量。每个核心都可以执行独立的指令流,因此核心数量直接影响到CPU的多任务处理能力和并行计算能力。
- 多核处理器可以同时处理多个任务,提高系统的整体性能。
- 线程数量(Threads):
- 线程数量指的是CPU能够同时执行的线程数量。线程是指在操作系统中独立调度和执行的基本执行单元。
- 超线程技术可以使得单个物理核心模拟出多个逻辑核心,从而提高处理器的线程并发能力,增加系统的多任务处理性能。
- 时钟频率(Clock Speed):
- 时钟频率指的是CPU内部时钟的运行速度,通常以赫兹(Hz)为单位表示。时钟频率越高,CPU执行指令的速度就越快。
- 虽然时钟频率是CPU性能的重要指标之一,但不同架构和制造工艺的CPU之间不能直接比较。因此,时钟频率并不是唯一决定性能的因素。
- 缓存大小(Cache Size):
- 缓存是CPU内部用于临时存储数据和指令的高速存储器。它可以加速CPU对常用数据和指令的访问,提高系统的响应速度和整体性能。
- CPU通常包含多级缓存(如L1、L2、L3缓存),缓存大小对CPU的性能和成本都有重要影响。
- 制造工艺(Manufacturing Process):
- 制造工艺指的是CPU芯片的制造工艺技术,包括晶体管的尺寸和布局等。制造工艺的进步可以使得CPU在相同尺寸下集成更多的晶体管,提高性能和能效。
- 常见的制造工艺包括14纳米、10纳米、7纳米等。
- 指令集架构(Instruction Set Architecture,ISA):
- 指令集架构定义了CPU支持的指令集合和指令执行方式。常见的指令集架构包括x86、x86-64(AMD64)、ARM等。
- 指令集架构决定了软件在CPU上的运行兼容性和性能表现。
内存 (RAM)
内存(RAM,Random Access Memory)技术包括多种类型,每种类型都有不同的特点、优势和用途。以下是几种常见的内存技术及其区别:
- DRAM(Dynamic Random Access Memory):
- DRAM是一种动态随机存取存储器,它使用电容来存储数据,并且需要周期性地刷新以保持数据的有效性。
- 主要分为SDRAM(Synchronous DRAM)、DDR(Double Data Rate)、DDR2、DDR3、DDR4和DDR5等几个主要代数。每一代DDR内存都在数据传输速度、功耗和密度等方面有所改进。
- 区别在于每一代DDR内存的频率、带宽和时序参数有所不同,随着代数的增加,内存的性能和功耗都得到了提升。
- SRAM(Static Random Access Memory):
- SRAM是一种静态随机存取存储器,它使用触发器(flip-flops)作为存储单元,相比DRAM,SRAM的访问速度更快,但成本更高。
- SRAM通常用于高性能的缓存和寄存器文件等需要快速访问的应用,如CPU缓存和高性能存储器。
图形处理器 (GPU)
GPU(图形处理器)是一种专门设计用于处理图形和图像相关任务的处理器。它们最初是为了处理计算机图形渲染而设计的,但随着技术的发展,GPU 在其他领域也发挥着越来越重要的作用,如科学计算、深度学习、数据分析等。
GPU主要有以下几个组件:
- 处理器核心:GPU 中包含大量的处理器核心,每个核心都能够执行特定的计算任务。这些核心通常被设计成多线程,并能够同时处理多个数据。
- 内存:GPU 配备自己的内存,用于存储图形数据、纹理和其他计算所需的数据。这些内存通常是高速且具有大容量。
- 显存控制器:负责管理 GPU 内存的访问和分配,以确保高效的数据传输和处理。
- 图形管线:图形管线是 GPU 中用于处理图形渲染任务的主要组件之一。它包括顶点处理、几何处理、光栅化、像素处理等阶段,用于将图形数据转换成最终的图像输出。
- 纹理单元:用于处理纹理映射和纹理滤波等任务的单元,以提高图形渲染的质量和效率。
- 渲染输出单元:负责将处理后的图像数据输出到显示器或存储设备,以供用户观看或后续处理。
存储设备 (Storage)
存储设备是计算机系统中用于存储数据的硬件设备。它们允许用户将数据永久地保存在计算机中,并在需要时进行访问和检索。存储设备通常根据其内部技术、容量、速度和用途等因素进行分类。以下是存储设备的一些常见类型和特点:
主要类型:
- 硬盘驱动器(HDD):
- 使用旋转磁盘和磁头来读写数据。
- 相对较大的存储容量,但读写速度相对较慢。
- 适用于大容量存储和长期存储。
- 固态硬盘(SSD):
- 使用闪存存储器来存储数据,无机械运动部件。
- 读写速度快,响应时间短。
- 耐用性好,不容易受到震动和冲击的影响。
- 适用于需要高速读写和响应的应用,如操作系统和应用程序。
- 光盘驱动器:
- 使用激光技术读写数据,包括 CD、DVD 和 Blu-ray 等。
- 适用于光盘媒体上的数据存储和传输。
- 闪存驱动器(USB 存储设备):
- 使用闪存存储器来存储数据。
- 便携小巧,易于携带和使用。
- 适用于临时数据传输和备份。
- 网络存储(NAS):
- 使用专用存储设备连接到网络,可以通过网络访问存储的数据。
- 可以提供共享文件存储、数据备份、远程访问等功能。
手机
手机相比于电脑,集成度就更高。手机也是通过主板链接各个硬件系统,其他中包括:
- 主板(Motherboard):主板是手机的核心组件,包含处理器(CPU)、内存(RAM)、存储芯片(ROM)、通信芯片、传感器等重要部件。
- 显示屏幕(Display Screen):显示屏通常是手机的最大部分,用于显示图像、文字和视频等内容。它可以是LCD(液晶显示器)、OLED(有机发光二极管)或AMOLED(主动矩阵有机发光二极管)等技术。
- 外壳(Casing):外壳是手机的外部框架,用于保护内部电子元件和提供结构支撑。它通常由塑料、金属或玻璃等材料制成。
- 电池(Battery):电池提供手机所需的电力。它通常是可充电的锂离子电池,尺寸和容量会根据手机型号和设计而有所不同。
- 摄像头(Camera):现代手机通常配备前置摄像头和后置摄像头,用于拍摄照片和视频通话。
- 扬声器和麦克风(Speakers and Microphones):扬声器用于播放音频,麦克风用于接收声音并进行通话或录音。
- 连接器(Connectors):手机通常具有充电端口、耳机插孔、SIM卡插槽和扩展存储卡插槽等连接器,用于连接外部设备和提供扩展功能。
- 天线(Antennas):天线用于接收和发送无线信号,包括Wi-Fi、蓝牙、GPS和移动网络信号等。
主板上核心的就是SOC,全称“System On Chip”,翻译成中文应该叫“片上系统”,通俗来讲,它表示“所有功能集成在一片上”,我们常说的“骁龙855”,“麒麟980”就是SOC。SOC主要包括: 1. 中央处理(CPU),负责执行手机上的各种计算任务。处理器的性能直接影响到手机的运行速度和响应能力。ARM是常见的处理器架构。 2. 图像处理器(GPU),图形处理器负责处理手机上的图形和视觉内容,包括游戏、视频播放和图形用户界面等。它能够加速图形渲染和处理复杂的图形效果。 3. 嵌入式神经网络处理器(NPU),它的全称叫neural-network process units,这个名字听起来很高端,简单来说,它主要负责负责处理涉及神经网络算法和机器学习的海量数据,因为神经网络算法及机器学习需要涉及海量的信息处理,而当下的 CPU / GPU 都无法达到如此高效的处理能力,需要一个独立的处理芯片来做这个事,才有NPU的诞生。现在的“人工智能”AI的概念可以说非常火热,而NPU就是让手机变得更智能,更聪明的必要条件。 4. 图像处理器(ISP),全称Image Signal Processor,不是GPU的“图形处理器”!它负责接收感光原件CMOS的原始数据,对这些数据做出“粗加工”,得到最后我们看到的照片,ISP需要与CMOS匹配。 5. 基带(Baseband), 基带的核心就是调制解调器(Modem),这个调制解调器主要的作用就是负责信号传输,所谓调制,就是把需要传输的信号,通过一定的规则调制到载波上面让后通过无线收发器发送出去的工程,解调就是相反的过程,等于说它把基站的语言“翻译成”手机能懂的,让二者能够“顺畅交流”,我们用户就能接打电话,连接网络了。 6. 协处理器(Coprocessor), 这是一种协助中央处理器完成其无法执行,或执行效率、效果低下的处理工作而开发和应用之处理器。这种中央处理器无法执行的工作有很多,比如设备间的信号传输、接入设备的管理等;而执行效率、效果低下的有图形处理、声频处理等。为了进行这些处理,各种辅助处理器就诞生了。 7. 数字信号处理器(DSP), 它全称叫Digital Signal Processor,它不仅仅应用在手机,在雷达、通信、图像处理、医疗电子、工业机器人等高密集计算领域皆有广泛应用,手机上而言,主要负责语音,包括通话和语音输入,也负责一些图像处理的任务。 8. 内存(Memory),仅提供支持的内存类型,并非代表SOC芯片里也集成了内存。除了内存之外,SOC也能影响所用的闪存类型,比如有的SOC只能用eMMC闪存。 9. 闪存(Flash),仅提供支持的内存类型, 闪存对应的PC的硬盘。
ARM结构
说到移动平台就不得不提ARM,ARM(Advanced RISC Machines)是一家总部位于英国剑桥的半导体和软件设计公司,成立于1990年。ARM 以设计低功耗、高性能的 RISC(Reduced Instruction Set Computing)架构处理器而闻名。该公司的处理器架构被广泛应用于移动设备、智能手机、平板电脑、物联网设备、汽车电子、嵌入式系统以及工业控制等领域。
ARM 公司的一些关键特点和业务范围:
处理器设计:ARM 设计了一系列低功耗、高性能的处理器架构,包括 Cortex-A、Cortex-R 和 Cortex-M 系列,覆盖了从高性能应用到嵌入式系统的广泛范围。 授权模式:ARM的授权方式分为TLA(技术许可协议)和ALA(架构许可协议)两类:TLA是指客户直接购买Arm的IP来用,可以在上面进行部分修改,比如高通的骁龙系列芯片;ALA则允许客户基于Arm架构下的指令集来自行设计IP,开发定制处理器内核,苹果芯片就是典型代表 生态系统:ARM 拥有庞大的合作伙伴和生态系统,包括芯片设计厂商、芯片制造厂商、软件开发者、系统集成商等。这些合作伙伴共同推动了 ARM 技术的发展和应用,并且为客户提供了全方位的技术支持和解决方案。 物联网和智能化:随着物联网和智能化技术的快速发展,ARM 公司致力于为物联网设备、智能家居、智能城市等领域提供先进的处理器架构和解决方案,推动智能化应用的普及和发展。 全球影响力:ARM 的处理器架构已经成为全球最流行的处理器架构之一,几乎所有的智能手机、平板电脑和物联网设备都采用了 ARM 的处理器架构。ARM 公司在全球范围内拥有广泛的客户和市场影响力。
由ARM公司设计出来的芯片架构就是ARM架构也叫做ARM指令集架构,ARM公司将这些设计以知识产权授权的方式给其他芯片厂商或集成商,不同的授权协议具有不同的权限: 1. TLA(技术许可协议), 依据售卖的芯片收费,但ARM好像打算改变了收取设计权利金的依据,将从芯片均价改为设备均价。 2. ALA(架构许可协议), 这种模式的自由度最大,适合那些技术强劲的公司,比较典型的就是苹果公司,他们购买相关指令集后,自己去设计芯片,此外高通,华为也是购买的架构和指令集。
ARM的特点:
- ARM指令都是32位定长的(ARMv7架构及之前版本都是32位,但是ARMv8架构一部份采用了64位指令集,而2022年6月29号发布的ARMv9版本芯片则全面采用64位指令集)
- 寄存器数量丰富(37个寄存器(大多))
- 普通的Load/Store指令
- 多寄存器的Load/Store指令
- 指令的条件执行
- 单时钟周期中的单条指令完成数据移位操作和ALU操作
- 通过变种和协处理器来扩展ARM处理器的功能
- 扩展了16位的Thumb指令来提高代码密度
ARM作为RISC微处理器与CISC微处理器技术对比如下:
上面提到的Cortex-A、Cortex-R, Cortex-M 和ARMv8/9有什么关系?
ARMv8 和 Cortex-A 是 ARM 公司的两个不同概念,但它们之间存在着密切的关系。
- ARMv8:
- ARMv8 是 ARM 公司发布的第八代指令集架构(ISA),它定义了处理器的指令集和执行规范。ARMv8 架构支持 64 位和 32 位的指令集,并引入了许多新的特性和增强功能,如更大的寻址空间、更强的安全性、更高的性能等。ARMv8 架构使得 ARM 处理器能够在 64 位模式下运行操作系统和应用程序,提高了计算能力和系统的扩展性。
- Cortex-A:
- Cortex-A 是 ARM 公司设计的一系列面向高性能应用的处理器核心。这些处理器核心采用了 ARMv8 架构,并且针对不同的应用场景提供了不同的性能和功能。Cortex-A 系列处理器核心通常用于智能手机、平板电脑、服务器等高性能计算设备,以及一些嵌入式系统和物联网设备。
关系: ARMv8 架构定义了处理器的指令集和执行规范,而 Cortex-A 系列处理器核心是基于 ARMv8 架构设计的具体实现。换句话说,Cortex-A 处理器核心是遵循 ARMv8 指令集架构的处理器核心之一。因此,Cortex-A 处理器核心通常被称为 ARMv8 架构的一部分,它们共同构成了 ARM 公司在高性能计算领域的解决方案。
SOC
目前主流的SOC有:高通骁龙(Snapdragon), 苹果A系列,海思麒麟,联发科天玑和三星Exynos(艾克西诺斯)
高通骁龙(Snapdragon)
高通骁龙(Snapdragon)系列是高通公司推出的移动处理器产品线,被广泛用于智能手机、平板电脑、智能穿戴设备、智能家居产品等移动设备和物联网设备中。
高通骁龙系列的一些主要特点和优势:
- 高性能处理器核心:
- 骁龙系列处理器采用了高通自主设计的 Kryo 处理器核心,具有出色的计算性能和能效。这些处理器核心通常根据型号不同分为 Prime 核心、性能核心和节能核心,以平衡性能和功耗。
- 先进的图形处理器:
- 骁龙处理器集成了 Adreno 图形处理器,提供了出色的图形性能和游戏体验。Adreno 图形处理器具有强大的图形渲染能力、支持高帧率游戏和流畅的视频播放等特性。
- 多模式连接技术:
- 高通骁龙处理器集成了先进的多模式连接技术,包括 LTE、5G、Wi-Fi 和蓝牙等多种连接方式,以提供高速、稳定的网络连接和无缝的通信体验。
- 人工智能加速器:
- 最新的骁龙处理器还集成了高通的人工智能引擎(AI Engine),包括神经处理器(NPU)和 DSP(数字信号处理器),用于加速 AI 和机器学习应用,如语音识别、图像处理等。
- 高清摄像和音频技术:
- 高通骁龙处理器支持高清摄像和音频技术,包括多摄像头配置、高分辨率视频录制和播放、立体声音频效果等,提供了优质的多媒体体验。
- 安全和隐私保护:
- 高通骁龙处理器集成了安全硬件模块和安全软件功能,提供了可靠的设备安全性和隐私保护,包括指纹识别、面部识别、硬件加密等功能。
苹果A系列
苹果A系列芯片拥有一系列特性,这些特性使其在性能、能效、图形处理和人工智能方面表现出色。以下是一些主要的苹果 A 系列芯片特性:
- 先进的制程工艺:
- 苹果 A 系列芯片采用先进的制程工艺,如 5 纳米或 7 纳米工艺,这有助于提高芯片的性能和能效,同时减小芯片的尺寸和功耗。
- 多核心 CPU 设计:
- 苹果 A 系列芯片通常采用多核心的 CPU 设计,其中包括高性能核心(大核心)和节能核心(小核心)。这种设计能够在处理不同负载时平衡性能和功耗,提高了整体的能效比。
- 高性能 GPU:
- 苹果 A 系列芯片集成了强大的图形处理器(GPU),提供了出色的图形处理性能。这些 GPU 通常采用多核心设计,并且支持最新的图形技术和特效,如 Metal 图形引擎。苹果之前使用的是Imagination(POWERVR),但是现在苹果也在逐渐自研替代。
- 神经引擎(Neural Engine):
- 苹果 A 系列芯片集成了专门用于人工智能(AI)和机器学习(ML)任务的神经引擎。这些引擎能够加速图像识别、语音识别、自然语言处理等 AI 应用,提供了更快的推理速度和更高的效率。
- 高效的能耗管理:
- 苹果 A 系列芯片采用了先进的能耗管理技术,包括动态调频、异步处理、功耗优化等,以提高芯片在不同负载下的能效比,延长设备的电池续航时间。
- 整合式芯片设计:
- 苹果 A 系列芯片采用了整合式芯片设计,将 CPU、GPU、神经引擎等核心功能集成在一颗芯片上。这种设计能够提高系统的整体性能、减小芯片的尺寸和功耗,并简化设备的硬件布局。
- 定制化软硬件协同设计:
- 苹果 A 系列芯片的设计与苹果自家的操作系统(如 iOS)和应用程序(如 Metal 图形引擎)进行了紧密的协同设计和优化,以提供最佳的性能和用户体验。
海思麒麟(HiSilicon Kirin)
海思麒麟(HiSilicon Kirin)是华为旗下的半导体设计公司海思(HiSilicon)推出的一系列移动处理器(SoC)品牌,主要用于华为和荣耀品牌的智能手机、平板电脑和其他移动设备。
海思麒麟芯片的特点和技术亮点:
- 多核心 CPU 设计:
- 麒麟芯片通常采用多核心的 CPU 设计,包括高性能的大核心和节能的小核心,以平衡性能和功耗。这种设计能够在不同负载下提供更好的性能和能效比。
- 强大的图形处理能力:
- 麒麟芯片集成了强大的图形处理器(ARM Mali GPU),提供了优秀的图形处理能力和游戏性能。这些 GPU 通常支持最新的图形技术和特效,为用户提供更好的视觉体验。
- AI 加速器:
- 麒麟芯片集成了专门的人工智能(AI)加速器,用于加速 AI 和机器学习(ML)任务。这些加速器能够提高图像识别、语音识别、自然语言处理等 AI 应用的性能和效率。
- 多模式连接技术:
- 麒麟芯片集成了先进的多模式连接技术,包括 LTE、5G、Wi-Fi 和蓝牙等多种连接方式,以提供高速、稳定的网络连接和无缝的通信体验。
- 安全和隐私保护:
- 麒麟芯片集成了安全硬件模块和安全软件功能,提供了可靠的设备安全性和隐私保护,包括指纹识别、面部识别、硬件加密等功能。
联发科天玑(MediaTek Dimensity)
联发科天玑(MediaTek Dimensity)是联发科技术公司推出的一系列移动处理器(SoC)品牌,旨在为智能手机和其他移动设备提供高性能、高效能和先进的连接性能。Dimensity 系列处理器以其强大的性能、集成的 5G 连接和 AI 加速等功能而备受关注。
联发科天玑处理器的特点和技术亮点:
- 多核心 CPU 设计:
- Dimensity 系列处理器采用了多核心的 CPU 设计,包括高性能核心和节能核心,以平衡性能和功耗。这种设计能够在处理不同负载时提供更好的性能和能效比。
- 集成 5G 连接:
- Dimensity 系列处理器集成了 5G 调制解调器,支持多模式 5G 连接,包括 SA(独立组网)和 NSA(非独立组网),以及 mmWave 和 Sub-6GHz 频段,为用户提供高速、稳定的网络连接。
- 先进的图形处理能力:
- Dimensity 系列处理器集成了强大的图形处理器(ARM Mali GPU),提供了优秀的图形处理能力和游戏性能。这些 GPU 通常支持最新的图形技术和特效,为用户提供更好的视觉体验。
- 人工智能加速器:
- Dimensity 系列处理器集成了专门的人工智能(AI)加速器,用于加速 AI 和机器学习(ML)任务。这些加速器能够提高图像识别、语音识别、自然语言处理等 AI 应用的性能和效率。
- 多核心 ISP:
- Dimensity 系列处理器集成了多核心的图像信号处理器(ISP),支持多摄像头配置、高分辨率图像和视频录制、实时图像处理等功能,提供了出色的摄像和摄录体验。
- 全球导航卫星系统(GNSS):
- Dimensity 系列处理器支持多种全球导航卫星系统,包括 GPS、GLONASS、Galileo、BeiDou 等,以提供精准的定位和导航服务。
三星Exynos(艾克西诺斯)
三星 Exynos(艾克西诺斯)系列处理器是由三星电子公司设计和生产的一系列移动处理器(SoC),主要用于其旗下的智能手机、平板电脑和其他移动设备。Exynos 系列处理器以其强大的性能、丰富的功能和先进的技术而闻名,是三星智能设备的核心组件之一。
三星 Exynos 系列处理器的特点和技术亮点:
- 多核心 CPU 设计:
- Exynos 系列处理器采用了多核心的 CPU 设计,包括高性能核心和节能核心,以平衡性能和功耗。这种设计能够在处理不同负载时提供更好的性能和能效比。
- 强大的图形处理能力:
- Exynos 系列处理器集成了强大的图形处理器(ARM Mali GPU),提供了优秀的图形处理能力和游戏性能。这些 GPU 通常支持最新的图形技术和特效,为用户提供更好的视觉体验。
- AI 加速器:
- 最新的 Exynos 系列处理器通常集成了专门的人工智能(AI)加速器,用于加速 AI 和机器学习(ML)任务。这些加速器能够提高图像识别、语音识别、自然语言处理等 AI 应用的性能和效率。
图像处理器(GPU)
主流的手机 GPU 包括以下几种:
- Adreno GPU(由高通设计):Adreno GPU 是目前市场上使用最广泛的 GPU 之一,广泛应用于高通 Snapdragon 系列移动处理器中。它具有出色的图形处理能力和游戏性能,在智能手机和平板电脑等移动设备上表现突出。
- Mali GPU(由 ARM 设计):Mali GPU 是 ARM 公司设计的一系列图形处理器,被广泛用于三星 Exynos、联发科 Dimensity 等系列处理器中。Mali GPU 以其良好的能效比和优秀的图形处理性能而闻名。
- Apple GPU 苹果公司在其 A 系列处理器中采用自家设计的 GPU,以提供卓越的图形处理性能和游戏体验。虽然具体的架构和型号没有公开,但苹果 GPU 在性能和能效上表现出色。
- PowerVR GPU(由 Imagination Technologies 设计):PowerVR GPU 曾经被苹果采用在早期的 iPhone 上,目前在一些联发科处理器中仍有使用。它具有出色的图形渲染能力和游戏性能。
嵌入式神经网络处理器(NPU)
什么是 NPU
人工智能加速器 NPU (Neural-network Processing Unit)是一类基于 DSA (Domain Specific Architecture) 领域专用架构技术的专用于人工智能(特别是人工神经网络、机器视觉、机器学习等)硬件加速的微处理器或计算系统。典型的应用包括机器人学、物联网等数据密集型应用或传感器驱动的任务。相比于 CPU、GPU,NPU 在硬件架构设计时便只针对于人工智能设计,举例来说,HUAWEI Kirin DaVinci Core 集成矩阵计算单元(Cube Unit)、向量计算单元(Vector Unit)和标量计算单元(Scalar Unit),可以通过硬件指令在一个周期内完成3D Cube、Vector向量、Scalar标量的计算,相比于通用处理器,其算力与数据吞吐量之比有数百倍提升,同时功耗维持在较低值。
NPU的诞生
长期以来,应用需求一直牵动着嵌入式技术、芯片技术的发展方向。随着深度学习神经网络的兴起,人工智能、大数据时代的来临,CPU 和 GPU 由于其造价高、功耗高、算力低渐渐难以满足端侧应用需要,面对日渐旺盛的需求和广大的预期市场,设计一款专门用于神经网络深度学习的高效智能处理器显得十分必要,因此NPU应运而生。 从技术角度看,基于卷积神经网络的机器学习技术实际上是一类多层大规模人工神经网络。它模仿生物神经网络而构建,由若干人工神经元结点互联而成。神经元之间通过突触两两连接,突触记录了神经元间联系的权值强弱。由于深度学习的基本操作是神经元和突触的处理,神经网络中存储和处理是一体化的,都是通过突触权重来体现,而在冯·诺伊曼结构中,存储和处理是分离的,分别由存储器和运算器来实现,二者之间存在巨大的差异。当用现有的基于冯·诺伊曼结构的经典计算机(如 X86、ARM 通用处理器和英伟达 GPU )运行神经网络应用时,就不可避免地受到存储和处理分离式结构的制约,数据吞吐量限制算力。因此,DSA 架构的专业芯片 NPU 便应运而生。
NPU 的功能
CPU (central processing unit) 是中央处理器。主要包括运算器(ALU)和控制单元(CU),还包括若干寄存器、高速缓存器和它们之间通讯的数据、控制及状态的总线。CPU 作为计算机系统的运算和控制核心,是信息处理、程序运行的最终执行单元。它主要负责多任务管理、调度,具有很强的通用性,是计算机的核心领导部件,其计算能力并不强,更擅长逻辑控制。
GPU(Graphics Processing Unit)是一种图形处理器,它可以弥补 CPU 在计算能力上的天然缺陷。相对于CPU 较少的内核较多的资源而言,它采用数量众多的计算单元和超长的流水线,善于进行大量重复计算,处理图像领域的运算加速。它的基本思想是并行计算即用多个处理器来共同求解同一问题,将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。但是缺陷也很明显,即协调、管理能力弱,无法单独工作,需要 CPU 进行控制调度。虽然 GPU 用于深度学习运算时速度比 CPU 有很大提升,但对于特定应用场景其仍有功耗大,驱动逻辑复杂,性能提升不足等问题。
NPU 与通用处理器设计思路不同。通用处理器考虑到计算的通用性,在提升算力的同时要考虑到数据吞吐量的提升
NPU 针对特定领域设计,无需考虑通用应用对于内存带宽的需求。相较于 CPU 擅长处理任务和发号施令,GPU 擅长进行图像处理、并行计算算,NPU 更擅长处理人工智能任务。NPU 通过突触权重实现存储和计算一体化,从而提高运行效率。NPU 也有不足,如特定的指令集可能只满足部分机器学习的需要,而不支持的指令或多个神经网络的组合计算仍然需要回落 (Fallback) 至通用处理器计算。
NPU 的应用
NPU 目前较多的在端侧应用于 AI 推理计算,在云端也有大量运用于视频编解码运算、自然语言处理、数据分析,部分NPU还能运用于 AI 的训练。
NPU 在端侧的运用 NPU 在端侧的运用较多,如 Apple、MTK、Kirin、清华紫光、瑞芯微等芯片厂商都有在其基于 ARM 架构的 Soc 内集成单独的 NPU 核心,辅助 CPU 完成异构计算;在纯微控制器(MCU)领域,STM32、Arduino、勘智等微控制器也有集成单独的 NPU 核心,方便在微控制器领域集成现代算法。具体的应用有:基于人脸识别的考勤机、基于 DHN(深度哈希网络)的掌纹识别、基于图像分类的自动垃圾分类、自动驾驶汽车、自动跟焦摄像机、监视系统等。其内嵌算法主要以卷积神经网络为主。
NPU 在云端的应用 NPU在云端的应用较少,目前主要以通用 GPU 运算为主,具体来说:百度有用于自然语言处理;华为有用于视频编解码运算;Google 将 TPU 运用于云端训练等。受限于部分 NPU 在架构设计的时候以算力功耗比为第一目标,其指令集较为精简,故用于模型训练较少,可能会遇到不支持的算子等问题。
内存(Memory)
目前手机主力的内存技术LPDDR5X,LPDDR5X是由JEDEC于2021年6月发布,它是一种专用的同步动态随机存取存储器(SDRAM)。与之前的LPDDR5标准相比,LPDDR5X在多个方面实现了改进:
- 在保持1.1V内核电压不变的情况下,速度从6.4Gbps提升到8.5Gbps
- 通过采用接收器均衡和发射器预加重技术,改善了信号完整性
- 全新的自适应刷新管理功能提高了可靠性
- 电池效率提高了多达20%
闪存(Flash)
目前手机系统主流的存储器件有两种,一种是安卓手机使用的UFS,另外一种是苹果用的NVMe。
UFS简介
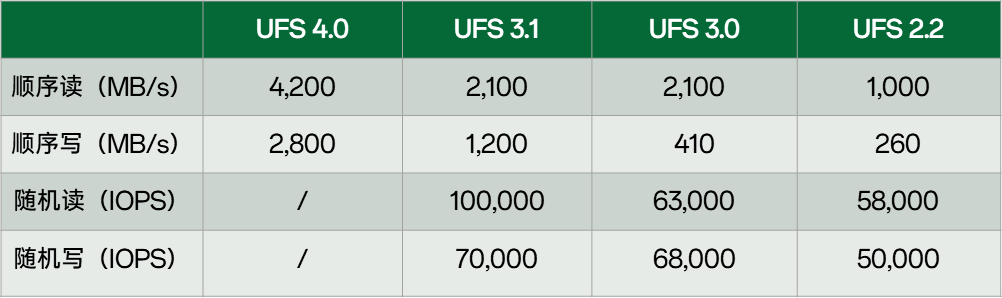
UFS,Universal Flash Storage,通用闪存存储。为什么现在主流使用UFS呢?很简单,就是快。我们看下主流2lan的UFS,其顺序读的数据传输速率可以达到4.2GB/s:
UFS为什么这么快呢,对比手机以前使用的eMMC,有如下优势: - UFS采用差分串行传输,而eMMC采用并行数据传输。并行最大的问题是速度上不去,因为一旦时钟频率提升,干扰就变大,信号完整性无法保证。随着时钟频率越来越高,高速串行传输的优势就很明显了。 - 支持多通道数据传输(目前是两通道),多通道可以让UFS在成本,功耗和性能之间做取舍。 - UFS是全双工工作模式,意味着读写可以并行。而eMMC是半双工,读写是不能同时进行的。 - UFS支持命令队列,可以异步处理命令,而eMMC无命令队列,只能进行同步处理。
综合串行,多通道,全双工和异步的巨大优势,UFS流行也是大势所趋。
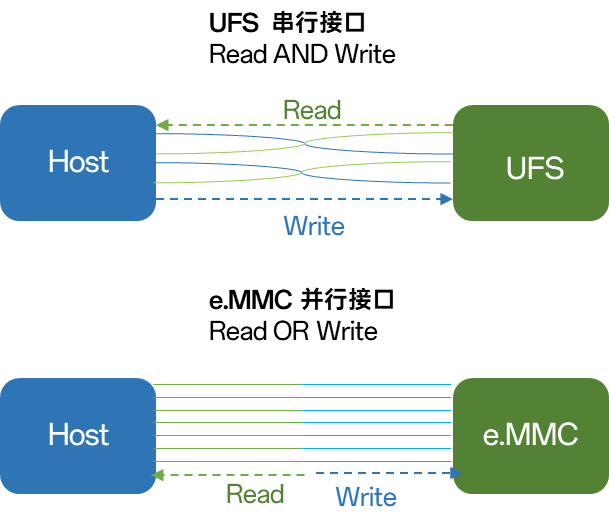
UFS(全双工+串行)vs eMMC(半双工+并行)
NVMe简介
NVMe是专门为高速闪存芯片设计的协议,主要是为企业级和数据中心的PCIe SSD设计的接口标准,来充分发挥闪存的性能。NVMe通讯协议+PCIe总线协议是实现高速SSD性能的基础,为什么这种组合可以充分发挥SSD的性能呢?
在NVMe之前,除了自成体系的SCSI协议(SAS SSD),其它SSD基本用的是AHCI+SATA协议。其实AHCI和SATA是为HDD服务的,而且SATA是由PATA进化而来,也是使用到了我们前面提到的高速串行的全双工传输。奈何SSD具有更低的延迟和更高的性能,SATA已经严重制约了SSD的速度,此时就需要PCIe了。
相比SATA/SAS,我们先看下PCIe到底有多快: 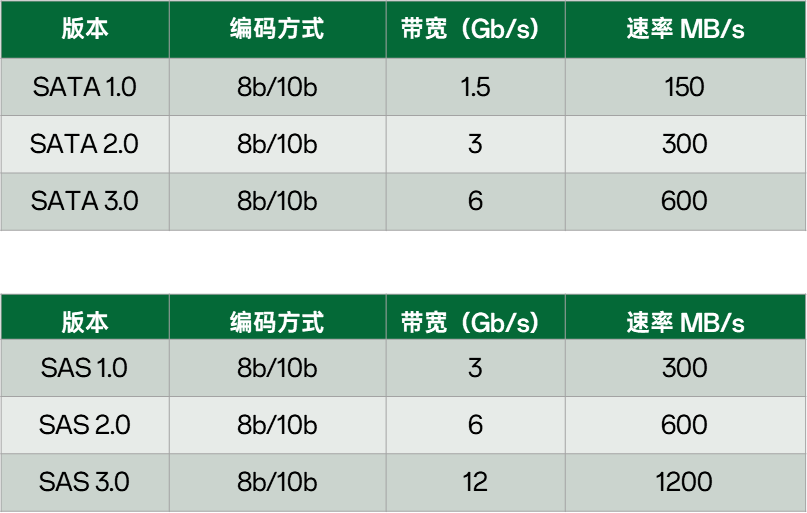
常见的4 lan的PCIe4.0 SSD,传输速度就可达7GB/s 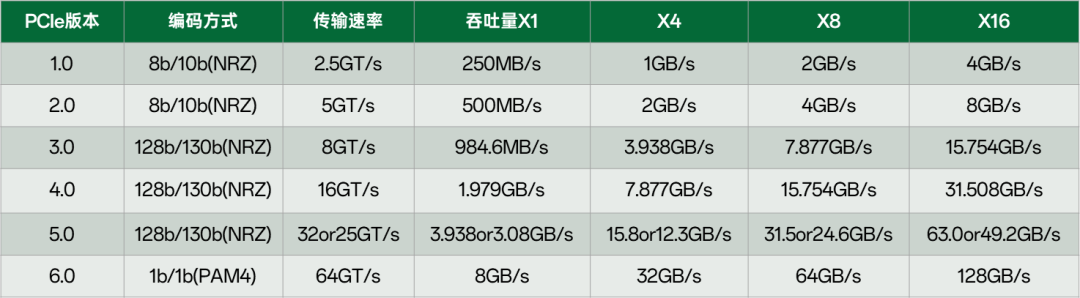
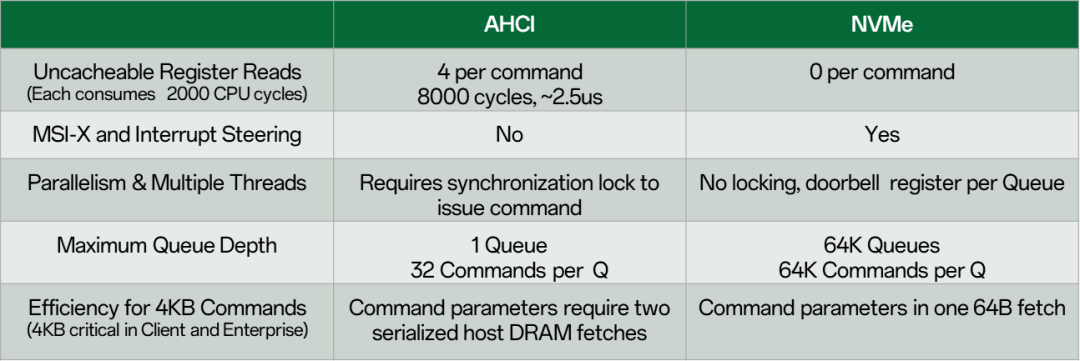
那么,如果把SATA换成PCIe是不是就可以了,有NVMe什么事情呢?这就需要看SATA的难兄难弟AHCI了,如果不用NVMe,老旧的AHCI同样会严重制约SSD性能。下面的对比图可以看到AHCI与NVMe的差距了:
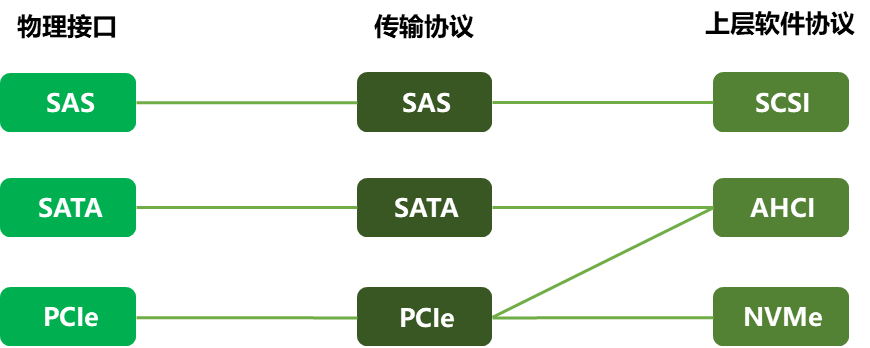
讲到这里,这些协议错综复杂,大家是不是已经云里雾里了。不着急,我们用下面这张图帮助大家理解他们的关系:
参照SAS
SSD的协议栈,我们可以简单明了的看到,SATA和PCIe是物理接口和协议,AHCI和NVMe则是上层软件协议
UFS与NVMe比较
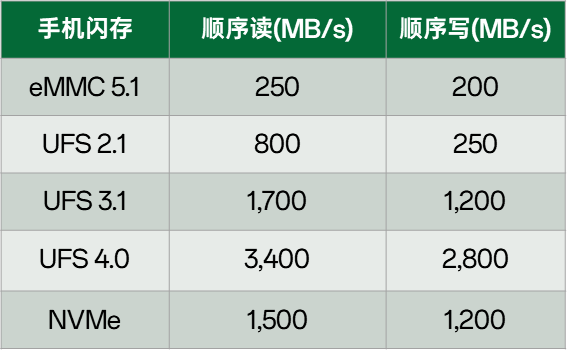
从上面的介绍可以看到,UFS拥有很好的性能,尤其是到了UFS4.0时代,2lan的顺序读可以达到4GB/s。但是,同时我们也可以看到,NVMe作为专为SSD所设计的协议,确实也有着无以伦比的性能,尤其是PCIe6.0,单lan就可以达到恐怖的8GB/s。
那么苹果为什么会采用NVMe而安卓还在继续使用UFS呢?孰优孰劣?从安卓各个厂家的角度来讲,为什么不采用NVMe呢?最关键的一点就是现在UFS的性能已经不比NVMe差了,根据下图,我们以iPhone 14 pro max上的NVMe速率来看,连续读取也只有1500M/s,已经比现在的UFS4.0速度差了很多,这也是安卓厂家能够继续使用UFS的最大驱动力。
所以顺序读写性能:UFS4.0 > NVMe = UFS 3.0 > UFS 2.1 > eMMC 5.1
HelloWorld的执行过程
本节的目的是分析一个程序从代码到最终执行的全部流程,其中涉及到程序的生成,程序的加载,程序的执行和程序的退出流程。经过本节的内容我们将了解的一个程序的完整生命周期。本节的内容都将基于ARMv8a指令架构的Android操作系统进行分析。
程序的生成
一个可执行文件或者库的生成一般会经历以下几个阶段: 1. 编写源码 2. 预处理 3. 编译 4. 链接 5. 生成可执行文件或库
本节将通过一个简单的程序,展示每个阶段的输出。前一个阶段的输出则是下一个阶段的输入。
主流C/C++编译工具集
现在主流的C/C++的编译器有:GCC, Clang/LLVM和MSVC
GCC (GNU Compiler Collection)
概述:
GCC 是一个支持多种编程语言的编译器套件,包括 C, C++, Objective-C, Fortran, Ada, 和 Go。它是开源的,并且在很多操作系统上可用,包括 Linux 和 Windows。
特点:
- 广泛支持多种编程语言。
- 支持多种平台和体系结构。
- 强大的优化功能。
- 支持 C++ 标准(如 C++11, C++14, C++17, C++20)。
Clang/LLVM
概述:
Clang 是 LLVM 项目的一部分,提供了一个类似于 GCC 的前端,但其架构更加模块化,易于扩展和嵌入。
特点:
- 更快的编译速度。
- 更好的错误和警告信息。
- 模块化设计,易于扩展。
- 支持最新的 C++ 标准。
- 提供静态分析工具(如 Clang Static Analyzer)。
Clang 的组成部分
前端: Clang 的前端处理源代码的词法分析和语法分析。它将源代码转换为抽象语法树(AST),然后进行语义分析和优化。
中间表示(IR): Clang 将 AST 转换为 LLVM 中间表示(IR)。LLVM IR 是一种底层的、中间的编程语言,用于在编译过程中进行优化和代码生成。
后端: Clang 使用 LLVM 的后端进行机器代码生成。LLVM 后端支持多种目标架构,如 x86、ARM 和 AArch64(ARM64)。
库和工具: Clang 提供了多个库和工具,包括:
- LibClang:一个 C 接口库,用于访问 Clang 的解析和编译功能。
- Clang Static Analyzer:一个静态分析工具,用于在编译时检测潜在的错误。
- Clang-Tidy:一个基于 Clang 的代码检查工具,用于发现和修复代码中的常见问题。
- Clang-Format:一个代码格式化工具,用于统一代码风格。
MSVC (Microsoft Visual C++)
概述:
MSVC 是微软提供的 C 和 C++ 编译器,主要用于 Windows 平台上的开发。它是 Visual Studio 开发环境的一部分。
特点:
- 与 Windows 操作系统和开发工具高度集成。
- 强大的 IDE 支持(Visual Studio)。
- 支持最新的 C++ 标准。
- 提供调试和分析工具。
Android和iOS都使用LLVM作为默认的编译工具集,所以本文将使用LLVM做为编译工具,并使用Android环境进行测试
源码
这个里我们随便写点c代码,主要看一下: 1. 函数是如何调用的; 2. 栈数据,堆数据和全局数据是如何访问的 3. 顺序,分支和循环代码对应的生成的机器指令生是什么样的;
示例代码(test_func.c):
1 |
|
示例代码(test_main.c):
1 |
|
代码编写完后,我们可以直接使用一下命令生成最终的可执行文件
1
clang -target aarch64-linux-android21 test_func.c test_main.c -o test
为了更进一步的了解整个的生成过程,我们将使用不的参数来生成中间内容。
预处理
使用如下指令可以生成预处理的结果:
1 | clang -target aarch64-linux-android21 -E test_func.c -o test_func.i |
预处理的作用是为了准备源代码以便后续的词法分析(Lexical Analysis)和语法分析(Syntax Analysis)阶段。这些预处理步骤包括:
- 文件包含处理, 将"#include"包含文件插入进来(指插入需要的代码片段,不是整个文件内容贴过来)。
- 宏替换, 处理#define和#undef宏定义。
- 条件编译, 处理 #if、#ifdef、#ifndef、#elif 和 #endif 等预处理指令。
- 注释移除
- 空格处理
- 标识符处理, 处理和标识符相关的预处理指令,如 #pragma 和 #error 等,进行相应的处理或者报错
- 其他预处理指令处理, 处理其他的预处理指令,如 #line、#define、#undef 等,根据其定义执行相应的操作。
预处理结果(部分),如下:
1 | static __inline double strtod_l(const char* __s, char** __end_ptr, locale_t __l) { |
编译
编译的目的是生成一个目标文件,生成目标文件的过程大致是:
- 词法分析(Lexical Analysis):
编译器首先将预处理后的源文件作为输入,进行词法分析。词法分析器会将源文件中的字符序列转换成一个个的词法单元(Token),每个词法单元代表源代码中的一个基本语法结构(如关键字、标识符、运算符等)。
- 语法分析(Syntax Analysis):
词法分析器生成的词法单元序列将被传递给语法分析器。语法分析器根据语法规则检查这些词法单元序列的结构是否符合语言的语法规范。如果源代码符合语法规则,语法分析器将生成一个抽象语法树(Abstract Syntax Tree, AST)。
语义分析(Semantic Analysis):
编译器接着进行语义分析,这一步骤确保程序语义上的正确性。语义分析器会检查类型、作用域、变量声明等语义信息,并生成中间代码或者直接生成汇编代码。
生成中间代码或汇编代码:
在语义分析阶段之后,编译器会根据语义分析得到的信息,生成中间代码或者直接生成目标平台的汇编代码。如果生成中间代码,后续可能会经过优化等步骤。如果直接生成汇编代码,那么此时就得到了汇编代码文件。
使用如下指令生成汇编结果:
1 | clang -target aarch64-linux-android21 -S test_func.i -o test_func.s |
汇编结果(test_func.s):
1 | .text |
优化和目标代码生成(可选步骤):
在一些编译器中,还会有优化器阶段,它会对中间代码或汇编代码进行优化,以提升程序的性能和效率。最终,优化后的中间代码或者汇编代码将会生成目标机器代码。
使用如下指令将生成汇编结果转换为最终的目标文件:
1 | clang -target aarch64-linux-android21 -c test_func.s -o test_func.o |
链接(生成最终可执行文件或库)
使用如下指令将目标文件链接成最终可执行的机器码文件:
1 | clang -target aarch64-linux-android21 test_func.o test_main.o -o test |
目标文件,可执行文件或库格式
可执行文件或库文件格式是指计算机系统中用于存储和加载程序的特定文件格式。不同的操作系统和硬件架构可能支持不同的可执行文件格式。以下是一些常见的可执行文件格式:
Linux 可执行文件格式:
ELF (Executable and Linkable Format):Linux 和许多其他类 Unix 操作系统上的主要可执行文件格式、共享库等。
ELF 文件的基本结构 ELF 文件的基本结构由三个部分组成:
- ELF Header:描述整个文件的组织结构, 包含文件类型、机器架构、入口地址等信息。
- Program Header Table:描述程序的各个段(segment),仅在可执行文件和共享库中存在,描述了程序在内存中的映射,每个条目描述一个段,段包含可执行代码、数据等
- Section Header Table:描述文件的各个节(section),用于链接和调试。
ELF文件我们在Linux内核源码中找到对应的实现,核心的代码如下:
1 | // ELF Header |
我们也可以使用readelf来查看ELF文件的内容:
ELF Header 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian 小端
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0x0
Type: DYN (Shared object file)
Machine: AArch64
Version: 0x1
Entry point address: 0x176C
Start of program headers: 64 (bytes into file) ELF Header后紧接着就是Program Header
Start of section headers: 5608 (bytes into file) Section 开始位置
Flags: 0x0
Size of this header: 64 (bytes) ELF Header的大小
Size of program headers: 56 (bytes) Program Header大小
Number of program headers: 11 Program Header数量
Size of section headers: 64 (bytes) Section Header大小
Number of section headers: 27 Section Header的数量
Section header string table index: 25 Section Header名字在字符串表中的索引位置
There are 27 section headers, starting at offset 0x15e8:
Program Headers 截取片段
1 | There are 11 program headers, starting at offset 64 |
Section Headers 截取片段
1 | There are 27 section headers, starting at offset 0x15e8: |
ELF文件结构图:
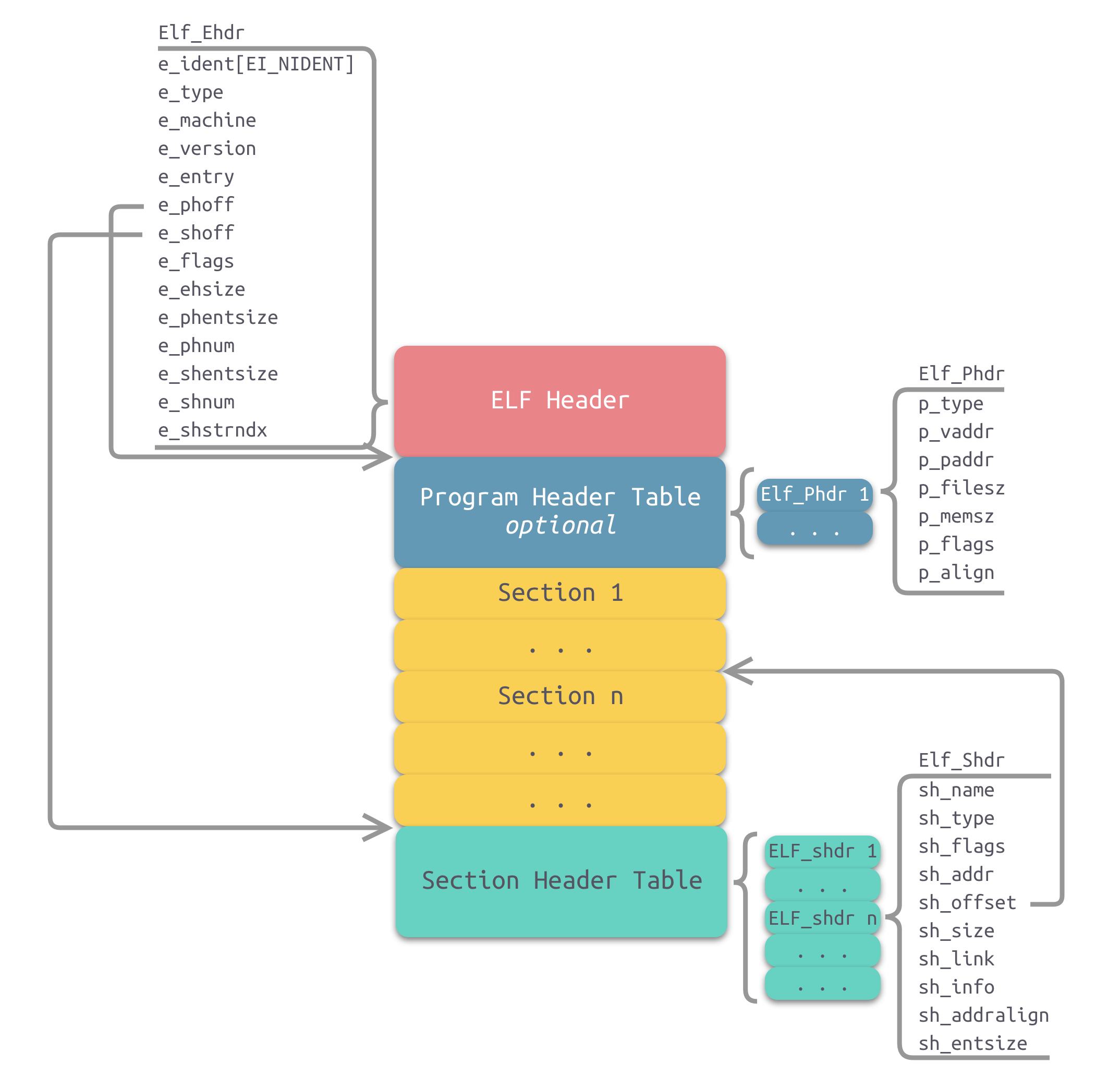
注意:段(Segment)与节(Section)的区别。很多地方对两者有所混淆。段是程序执行的必要组成,当多个目标文件链接成一个可执行文件时,会将相同权限的节合并到一个段中。相比而言,节的粒度更小。
macOS 可执行文件格式:
Mach-O (Mach Object):macOS 和 iOS 系统上的可执行文件格式、共享库等。其格式和ELF原理上都是相通的,不做详细赘述。
Windows 可执行文件格式:
Portable Executable (PE):Windows 系统上最常见的可执行文件格式,包括程序、动态链接库 (DLL) 和驱动程序等。其格式和ELF原理上都是相通的,不做详细赘述。
本节,我们窥探了一下Linux目标文件的格式,下面我们将多个目标文件链接成一个可执行的文件。链接的方式主要有两种:静态链接和动态链接。
静态链接
静态链接的过程大致如下:
- 地址与空间分配(Address and Storage Allocation)
- 符号解析和重定位(Symbol Resolution and Relocation)
地址与空间分配
在ELF文件结构中,我们可以看到,是由各种节(Section)组成的,每个节都会有对应的文件位置,以及分配的虚拟地址空间。合并成一个后我们要就要分配对一个的文件空间和虚拟的地址空间。
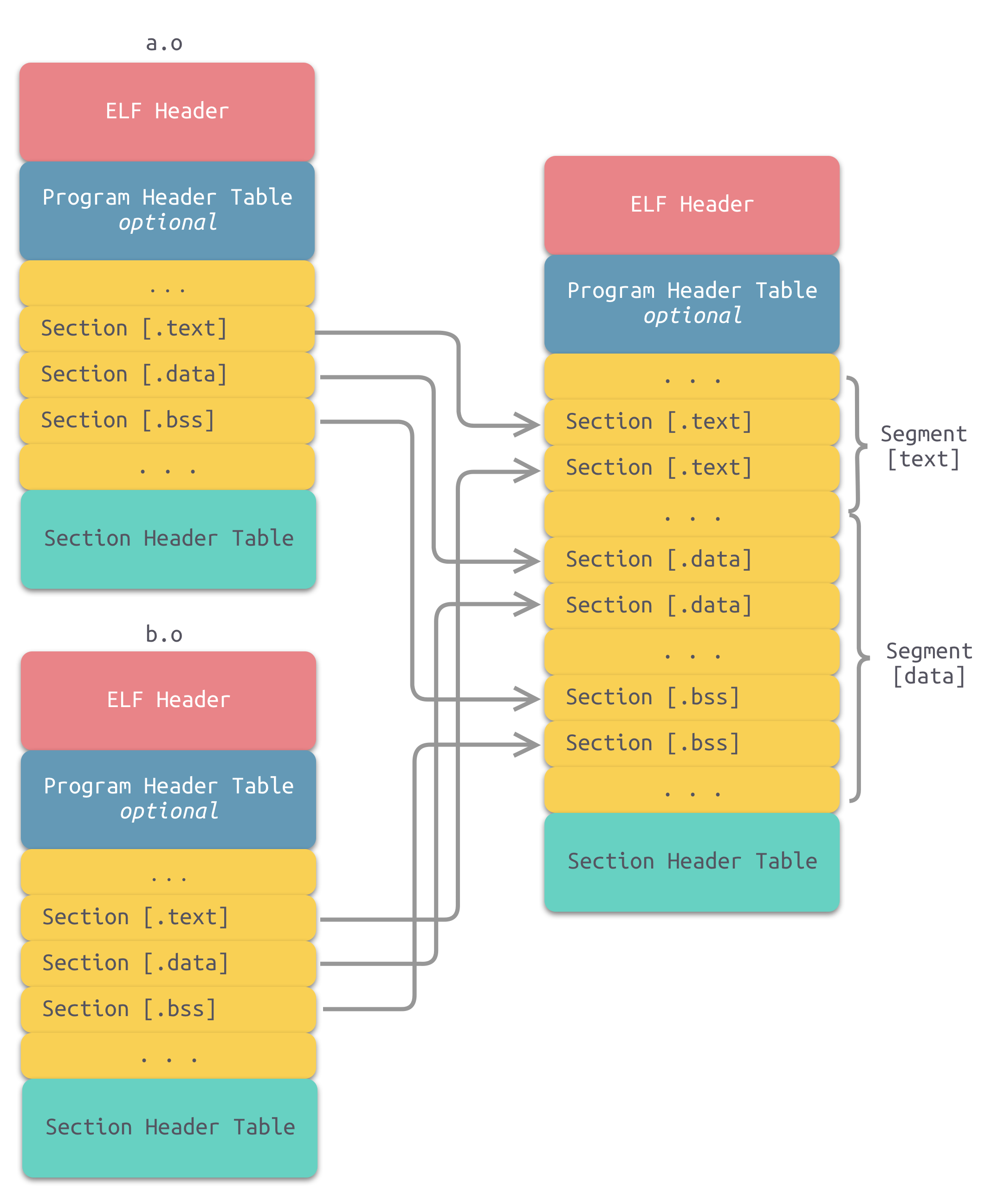
符号解析和重定位
将每个目标文件中的符号(函数,变量等)进行地址调整。那么链接器如何知道哪些指令是要被调整的呢?事实上,我们前面提到的ELF文件中的 重定位表(Relocation Table) 专门用来保存这些与重定位相关的信息。对于可重定位的ELF文件来说,它必须包含重定位表,用来描述如何修改相应的节的内容。对于每个要被重定位的ELF节都有一个对应的重定位表。如果.text节需要被重定位,则会有一个相对应叫.rel.text的节保存了代码节的重定位表;如果.data节需要被重定位,则会有一个相对应的.rel.tdata的节保存了数据节的重定位表。
动态链接
动态链接涉及运行时的链接以及多个文件的装载,必需要有操作系统的支持。因为动态链接的情况下,进程的虚拟地址空间的分布会比静态链接情况下更为复杂,还有一些存储管理、内存共享、进程线程等机制在动态链接下也会有一些微妙的变化。
目前,主流操作系统都支持动态链接。在Linux中,ELF动态链接文件被称为 动态共享对象(DSO,Dynamic Shared Objects),一般以.so为后缀;在Windows中,动态链接文件被称为 动态链接库(Dynamic Linking Library),一般以.dll为后缀。
在Linux中,常用的C语言库的运行库glibc,其动态链接形式的版本保留在 /lib目录下,文件名为 libc.so。整个系统只保留一份C语言动态链接文件libc.so,所有的C语言编写的、动态链接的程序都可以在运行时使用它。当程序被装载时,系统的动态链接器会将程序所需要的所有动态链接库装载到进程的地址空间,并将程序中所有未解析的符号绑定到相应的动态链接库中,并进行重定位。
程序的加载与执行
应用程序从启动到运行的过程涉及多个步骤,包括加载、准备和执行。以下是一个详细的过程描述:
用户请求:
用户通过命令行或图形界面(如双击图标)启动一个应用程序。这一操作向操作系统发出了一个启动应用程序的请求。
操作系统接收请求:
操作系统接收用户的请求,并开始启动应用程序的过程。具体步骤如下:
查找可执行文件:
操作系统在文件系统中查找应用程序的可执行文件。可执行文件通常包含程序的代码和数据。
分配内存:
操作系统为应用程序分配内存空间,包括代码段、数据段、堆、栈等。 代码段存储程序指令,数据段存储全局和静态变量,堆用于动态内存分配,栈用于函数调用和本地变量。
加载可执行文件:
操作系统将应用程序的可执行文件加载到分配的内存空间中。通常使用的是分页或分段机制,逐步将程序代码和数据加载到内存中。
设置进程控制块(PCB):
操作系统创建一个新的进程控制块(Process Control Block,PCB),其中包含关于新进程的信息,如进程ID(PID)、进程状态、寄存器内容、内存指针等。 PCB用于管理进程并在进程切换时保存和恢复进程状态。
初始化进程环境:
操作系统为新进程初始化必要的环境,包括环境变量、文件描述符(如标准输入、输出、错误)等。 设置程序入口点(通常是main函数的地址)和初始堆栈指针。
加载动态链接库:
如果应用程序依赖于动态链接库(DLL或共享库),操作系统会加载这些库到内存中,并将它们链接到应用程序中。这个过程通常由动态链接器(如Linux上的ld.so)完成。
进入就绪队列:
新进程的PCB被加入到就绪队列中,等待调度器将其分配到CPU上执行。
调度程序调度:
操作系统的调度程序(Scheduler)选择一个就绪进程,并将其分配到CPU上执行。选择策略可能是先来先服务(FCFS)、短作业优先(SJF)、时间片轮转(RR)等。
切换到用户态:
调度程序将进程的上下文信息(如寄存器、程序计数器)加载到CPU,并切换到用户态,开始执行应用程序的代码。 进程从操作系统内核态切换到用户态,正式开始执行应用程序。
执行应用程序:
应用程序开始运行,其主函数被调用,并开始执行其中的指令。 在运行过程中,应用程序可能会进行系统调用,以请求操作系统执行特权操作(如文件读写、网络通信等)。
系统调用处理:
当应用程序进行系统调用时,CPU切换到内核态,操作系统处理请求,然后返回用户态继续执行应用程序。 系统调用的处理包括参数验证、权限检查、实际操作执行等。
进程终止:
当应用程序执行完成或者被用户终止时,它会调用系统调用(如exit)通知操作系统。 操作系统释放进程占用的资源(如内存、文件描述符等),更新进程状态,将PCB从进程表中移除。 操作系统可能会通知父进程(如果有),并可能启动清理或回收资源的操作。
分析工具
硬件参数和访问过程
了解硬件的参数和访问过程,有助于我们理解分析工具中的各种参数,以及他们所代表的意义。
闪存
闪存(Flash Memory)是一种非易失性存储器,广泛用于固态硬盘(SSD)、USB闪存驱动器、SD卡和嵌入式系统中。闪存的访问过程包括读、写和擦除操作。
闪存基本结构
1. 控制器:负责管理闪存的读写操作、地址映射、坏块管理等。 2. 存储单元:由NAND或NOR闪存芯片组成,存储实际的数据。 3. 接口:例如eMMC(Embedded MultiMediaCard)或UFS(Universal Flash Storage),负责与处理器通信。
闪存访问过程
读操作
1. 主机命令:
- 手机处理器(主机)发出读命令,指定逻辑块地址(LBA),并通过接口(如eMMC或UFS)发送给闪存控制器。
2. 命令解析:
- 闪存控制器接收并解析读命令和LBA,将逻辑地址(LBA)转换为物理地址(PBA)。
3. 加载数据:
- 闪存控制器从指定的物理地址读取数据,将数据从闪存芯片加载到控制器的内部数据缓冲区。这涉及读取存储单元中的电荷状态并将其转换为数字数据。
4. 错误校验:
- 闪存控制器使用错误纠正码(ECC)对数据进行校验和纠错,确保数据的完整性和正确性。
5.数据传输:
- 数据从闪存控制器的缓冲区通过接口(如eMMC或UFS)传输到主机。
6. 主机接收:
- 主机接收到数据后,直接将其写入到系统内存(RAM)中。这个过程由主机的内存控制器管理,确保数据在内存中的正确存储位置。
写操作
1. 主机命令:
- 主机发出写命令,指定LBA和要写入的数据。
2. 命令解析:
- 闪存控制器解析命令并将LBA转换为PBA。
3. 数据传输:
- 主机通过接口将数据传输到闪存控制器的内部缓冲区。
4. 写入:
- 闪存芯片将缓冲区的数据写入指定的存储单元。
5. 错误校验:
- 使用ECC校验写入的数据。
6. 状态返回:
- 控制器将操作结果返回给主机。
擦除操作
1. 主机命令:
- 主机发出擦除命令,指定要擦除的块。
2. 命令解析:
- 闪存控制器解析命令并将LBA转换为PBA。
3. 擦除操作:
- 闪存芯片将指定块中的所有存储单元设置为初始状态。
4. 确认擦除:
- 控制器确认擦除完成。
5. 状态返回:
- 控制器将操作结果返回给主机。
闪存参数
- 读写速度: 每秒钟读/写的数据量,通常以MB/s或GB/s为单位。
- 读写延迟: 执行读/写操作的时间,通常以毫秒(ms)为单位。
- IOPS(每秒输入输出操作次数): 每秒钟执行的I/O操作次数,用于衡量存储设备的性能。
- 队列深度: 同时处理的I/O操作数量,较高的队列深度可能导致更高的延迟。
- I/O大小: 每个I/O操作的数据量,通常以字节(B)、千字节(KB)或兆字节(MB)为单位。
- 吞吐量: 单位时间内传输的数据量,通常以MB/s或GB/s为单位。
内存
内存结构
在计算机内存(尤其是DRAM,如SDRAM、DDR等)中,内存单元以矩阵的形式组织,每个单元存储一个比特的数据。这些数据单元(存储单元)被组织成一个二维矩阵。每个单元可以通过其行地址和列地址唯一标识。这个结构类似于一个电子表格,每个单元格可以通过其行和列来确定位置。
- 行地址(Row Address):用于选择内存矩阵中的某一行。所有的存储单元都按行组织,因此首先需要选择包含目标单元的行。
- 列地址(Column Address):用于选择特定行中某一列的地址。与行地址一起唯一标识内存单元的位置。
内存访问过程
内存访问是计算机系统中非常基础和关键的操作过程,它涉及多个步骤和多个组件之间的协同工作。以下是详细描述内存访问过程的步骤:
内存访问的详细步骤
1. 生成内存地址:
- CPU生成地址:处理器(CPU)根据当前执行的指令生成一个内存地址。这个地址可能是指令中的直接地址,或者是通过地址计算(如基地址加偏移量)生成的。
- 虚拟地址转换:如果使用虚拟内存,生成的地址是虚拟地址,需要通过地址转换机制转换成物理地址。
2. 地址转换:
- 页表查询:通过页表(Page Table)将虚拟地址转换为物理地址。页表存储在内存中,但为了加速转换过程,常用的页表项会缓存到转换后备缓冲(TLB,Translation Lookaside Buffer)中。
- TLB查找:处理器首先查询TLB。如果找到匹配项,直接使用转换后的物理地址。如果没有找到,则需要访问页表进行转换,并可能更新TLB。
- 页表遍历:如果TLB没有命中,处理器会访问页表(可能涉及多级页表),获取物理地址。
3. 检查缓存:
- 一级缓存(L1 Cache)查找:处理器首先查找L1缓存,如果命中,则从L1缓存中读取或写入数据。
- 二级缓存(L2 Cache)查找:如果L1缓存未命中,继续查找L2缓存。
- 三级缓存(L3 Cache)查找:如果L2缓存未命中,继续查找L3缓存。
- 主内存访问: 如果所有缓存都未命中,则需要访问主内存(DRAM)。
4. 内存控制器操作:
行地址选通(RAS):内存控制器发送行地址并激活行地址选通信号(RAS),选择目标行。
列地址选通(CAS):内存控制器发送列地址并激活列地址选通信号(CAS),选择目标列。
数据准备:内存控制器等待内存阵列准备好数据。
5. 数据传输:
读取数据:如果是读操作,数据从内存传输到内存控制器,然后通过系统总线传输到处理器缓存或寄存器。
写入数据:如果是写操作,数据从处理器传输到内存控制器,然后写入指定的内存单元。
6. 缓存更新:
缓存写入:如果数据被写入缓存,需要相应地更新缓存内容(包括L1、L2、L3缓存)。
缓存一致性:保持缓存一致性(如通过MESI协议)以确保数据的一致性和正确性。
内存刷新(仅DRAM):
周期性刷新:DRAM需要周期性刷新操作以保持数据。刷新操作由内存控制器管理,并在后台进行,不直接影响单次内存访问,但会占用内存带宽。
内存参数
1. 内存延迟(Memory Latency)
- 定义:内存延迟是从处理器发出内存访问请求到第一个字节的数据开始被返回所需要的时间。内存延迟通常用纳秒(ns)来表示。由行地址传输时间, 列地址传输时间, 数据准备时间组成,主要受内存的内部架构和访问机制影响。
- 意义:低内存延迟意味着处理器能够更快地访问内存数据,从而提高运行速度。
2. 内存访问时间(Memory Access Time)
- 定义:内存访问时间是从处理器发出内存访问请求到数据完全被处理器接收的总时间,包括内存延迟和数据传输时间。它通常也是用纳秒(ns)来表示。由内存延迟和数据传输时间组成,除了内存内部架构和访问机制外,还受到数据总线速度、数据块大小和传输方式的影响。
- 意义:较短的内存访问时间提高了处理器的执行效率。
3. 内存循环周期(Memory Cycle Time)
- 定义:从开始一次内存访问(例如一次读取操作)到内存准备好进行下一次(关闭行等)访问的总时间。这个时间包括访问内存单元、传输数据以及内存准备下一个访问所需的恢复时间。由内存访问时间和恢复时间(内存在完成一次访问后,需要一定时间恢复到可以进行下一次访问的状态)组成,
- 意义:较短的内存循环周期使得内存可以更频繁地进行访问操作,提高访问效率。
4. 内存访问频率(Memory Access Frequency)
- 定义:内存访问频率指的是内存可以进行读写操作的频率,通常用MHz或GHz来表示,不同类型的内存具有不同的访问频率。常见的DDR4:频率范围在1600MHz到3200MHz之间。
- 意义:较高的内存访问频率表示内存可以更频繁地进行读写操作,也意味着更高的传输速率和更高的带宽。
5. 内存带宽(Memory Bandwidth)
- 定义:内存带宽是指在一定时间内从内存传输到处理器的数据量,通常以GB/s(每秒千兆字节)为单位。
- 意义:高内存带宽意味着处理器能够更快地读取和写入数据,提高系统整体性能。带宽的计算公式如下: \[{内存带宽(GB/s)}= {数据传输速率(MT/s)}\times {总线宽度(字节)} \times {通道数}\] 例如,对于DDR4-3200内存,假设是单通道64位总线:内存带宽=3200MT/s×8B×1=25.6GB/s
6. 时钟周期(Clock Cycles)
- 定义:内存时钟信号的一个完整周期,从一个上升沿到下一个上升沿,或从一个下降沿到下一个下降沿。在一个时钟周期内,内存会执行部分操作或完成一个完整的操作步骤。
- 意义:较少的时钟周期表示更高效的内存访问。假设一个DDR4内存模块的时钟频率为3200MHz,其对应的时钟周期为: \[时钟周期= \frac{1}{时钟频率}\] \[时钟周期= \frac{1}{3200 \times 10^{6}Hz} ≈ 0.3125 ns\]
这意味着在3200MHz的频率下,每个时钟周期的时间长度约为0.3125纳秒。
7. 数据传输率(Data Transfer Rate) - 定义:内存在一定时间内传输的数据量。它通常以每秒传输的百万次传输(MT/s)表示,并可以进一步换算成带宽(GB/s)。 - 意义:高数据传输率表示更快的数据移动速度,提高系统性能。数据传输率的计算:
8. 内存命中率(Memory Hit Rate)
- 定义:内存命中率是指缓存中的数据被请求到的比例。高命中率意味着大多数内存请求可以在缓存中找到。
- 意义:高内存命中率减少了对主内存的访问次数。
9. 页错误率(Page Fault Rate) - 定义:页错误率是指在虚拟内存系统中,处理器试图访问未加载到物理内存中的页面时发生的错误率。 - 意义:低页错误率意味着较少的磁盘访问。
10. 队列长度(Queue Length) - 定义:内存队列长度指的是在任何给定时间内等待处理的内存请求的数量。这些请求可能是由于处理器需要读取或写入数据到内存而产生的。队列长度是一个重要的性能指标,因为它可以反映系统的负载和效率。 - 意义:较短的队列长度表示更快的请求处理时间。表示内存子系统能够有效地处理内存请求,系统运行更平稳
11. 内存使用率(Memory Utilization) - 定义:内存使用率是指系统总内存的使用情况,通常以百分比表示。 - 意义:高内存使用率可能表示内存压力较大,需优化内存分配和使用策略。
CPU
中央处理器(CPU, Central Processing Unit)是计算机系统的核心组件,负责执行指令和处理数据。它被称为计算机的大脑,因为它执行所有的基本计算任务。
CPU的基本组成部分
1. 运算逻辑单元(ALU, Arithmetic Logic Unit):
- 执行所有的算术和逻辑操作,如加、减、乘、除以及逻辑运算(如与、或、非)。
2. 控制单元(CU, Control Unit):
- 负责从内存中取指令、解释指令并执行。它控制ALU、寄存器和其他组件的操作。
3. 寄存器(Registers):
- CPU内部的高速存储单元,用于暂时存储指令、数据和地址信息。常见寄存器包括程序计数器(PC)、指令寄存器(IR)和累加器(ACC)。
4. 高速缓存(Cache):
- 位于CPU和主存之间的高速存储器,用于存储频繁使用的数据和指令,减少访问主存的时间。
5. 总线接口单元(Bus Interface Unit):
- 负责CPU与其他组件(如内存、输入/输出设备)之间的数据传输。
CPU执行代码过程
CPU执行代码的过程是一个复杂且高度优化的操作,涉及多个阶段和不同的硬件组件。以下是详细的执行过程,分为几个主要步骤:
1. 取指令(Fetch)
过程:从内存中读取下一条指令。
详细说明:
- 程序计数器(Program Counter, PC):指向将要执行的下一条指令的内存地址。
- 取指单元(Fetch Unit):从内存中读取指令,并将其放入指令寄存器(Instruction Register, IR)。
2. 解码(Decode)
过程:将取回的指令翻译成CPU能够理解的控制信号。
详细说明:
- 指令解码器(Instruction Decoder):分析指令的操作码(Opcode)和操作数(Operands)。
- 生成控制信号:根据指令的类型,生成相应的控制信号,以驱动后续的执行单元。
3. 读取操作数(Operand Fetch)
过程:从寄存器或内存中读取指令所需的数据。
详细说明:
- 寄存器读取:如果操作数在寄存器中,直接从寄存器文件中读取。
- 内存读取:如果操作数在内存中,CPU会发出内存读取请求,将数据从内存中加载到寄存器中。
4. 执行(Execute)
过程:根据指令类型,进行相应的计算或操作。
详细说明:
- 算术逻辑单元(ALU, Arithmetic Logic Unit):执行算术和逻辑运算。
- 浮点单元(FPU, Floating Point Unit):执行浮点运算。
- 分支单元(Branch Unit):处理跳转和分支指令。
- 特殊指令:如加载、存储、移位等操作。
5. 访问内存(Memory Access)
过程:对于需要访问内存的指令,执行读写操作。
详细说明:
- 加载指令:将数据从内存加载到寄存器。
- 存储指令:将数据从寄存器存储到内存。
6. 写回(Write Back)
过程:将执行结果写回寄存器或内存。
详细说明:
- 结果写回寄存器:执行结果写回到目标寄存器。
- 结果写回内存:在必要时,将结果写回到内存中。
7. 更新程序计数器(Update PC)
过程:更新程序计数器,以指向下一条指令的地址。
详细说明:
- 顺序执行:PC通常递增以指向下一条顺序指令。
- 跳转和分支:如果是跳转或分支指令,PC会更新为目标地址。
CPU执行指令的具体硬件组件
- 寄存器(Registers):用于存储临时数据和指令。
- 缓存(Cache):加速数据访问,减少对内存的访问延迟。
- 控制单元(Control Unit):生成控制信号,协调各个部分的工作。
- 流水线(Pipeline):分解指令执行过程,允许多个指令同时在不同阶段执行,提高并行度和吞吐量。
- 分支预测(Branch Prediction):预测分支指令的执行路径,减少流水线中断。
流水线执行过程
现代CPU通常采用流水线技术,将指令执行过程分解为多个阶段,允许多个指令同时在不同阶段执行。典型的流水线阶段包括:
- 取指(Fetch)
- 解码(Decode)
- 执行(Execute)
- 访存(Memory Access)
- 写回(Write Back)
超标量和超线程技术
- 超标量(Superscalar):同时执行多条指令,通过多个执行单元实现。
- 超线程(Hyper-Threading):在一个物理核心上同时运行多个线程,提高并行处理能力。
执行流程的优化技术
- 分支预测(Branch Prediction):减少分支指令导致的流水线中断。
- 动态调度(Dynamic Scheduling):根据资源可用性和指令依赖关系,动态调整指令执行顺序。
- 投机执行(Speculative Execution):在确认分支路径前,提前执行可能的指令路径。
CPU参数
1.时钟速度(Clock Speed)
- 定义:CPU的时钟频率,通常以千兆赫兹(GHz)表示。
- 作用:时钟速度直接影响CPU每秒钟可以执行的指令数。更高的时钟速度通常意味着更快的处理速度,但也需要考虑功耗和散热。
2. 指令每周期(IPC, Instructions Per Cycle)
- 定义:CPU每个时钟周期内可以执行的指令数。
- 作用:高IPC表示CPU在相同时钟速度下能够完成更多工作,反映了CPU架构的效率。
3. 核心数量(Number of Cores)
- 定义:CPU内部的独立处理单元数量。
- 作用:多核CPU能够并行处理多个任务,有助于提升多任务处理和多线程应用的性能。
4. 线程数量(Number of Threads)
- 定义:CPU可以同时处理的线程数。
- 作用:支持超线程技术(如Intel的Hyper-Threading)可以进一步提高并行处理能力,尤其是在多线程应用中。
5. 缓存大小(Cache Size)
- 定义:CPU内部的高速缓存容量,包括L1、L2和L3缓存。
- 作用:较大的缓存可以减少内存访问延迟,提高数据访问速度,从而提升整体性能。
6. 内存带宽(Memory Bandwidth)
- 定义:CPU与系统内存之间的数据传输速率,通常以GB/s表示。
- 作用:更高的内存带宽可以加快数据传输,减少内存瓶颈,尤其对数据密集型应用有重要影响。
7. 内存延迟(Memory Latency)
- 定义:CPU从内存请求数据到接收到数据所需的时间。
- 作用:较低的内存延迟可以减少等待时间,提高整体系统响应速度。
8. 分支预测准确率(Branch Prediction Accuracy)
- 定义:CPU预测程序中分支指令(如条件跳转)的准确率。
- 作用:高分支预测准确率可以减少流水线冲刷,提升指令执行效率。
9. 专用加速器(Dedicated Accelerators)
- 定义:CPU中集成的专用硬件单元,如图形处理单元(GPU)、神经处理单元(NPU)等。
- 作用:专用加速器能够显著提升特定任务的性能,如图形渲染、AI计算等。
10. 功耗(Power Consumption)
- 定义:CPU运行时的电能消耗,通常以瓦特(W)为单位。
- 作用:较低的功耗可以延长电池续航时间,减少散热需求,但可能会限制性能。
11. 热设计功耗(TDP, Thermal Design Power)
- 定义:CPU在高负载下的最大功耗,通常以瓦特(W)表示。
- 作用:TDP越高,通常意味着CPU在高负载下可以保持更高的性能,但也需要更好的散热解决方案。
12. 系统总线速度(System Bus Speed)
- 定义:CPU与其他系统组件(如内存、I/O设备)之间的数据传输速率。
- 作用:更高的总线速度可以提高数据传输效率,减少瓶颈。
13. 上下文切换时间(Context Switch Time)
- 定义:CPU在不同任务之间切换时所需的时间。
- 作用:较短的上下文切换时间可以提高多任务处理效率。
14. 平均负载(Average Load)
- 定义:CPU在一定时间内的平均工作负载。
- 作用:平均负载可以反映系统在日常使用中的性能表现,过高的平均负载可能表示系统瓶颈。
15. 使用率(Utilization)
- 定义:CPU在特定时间段内的使用百分比。
- 作用:高使用率通常表示CPU处于高负载状态,但持续的高使用率可能导致过热和性能下降。
16. 吞吐量(Throughput)
- 定义:CPU在单位时间内可以处理的任务或数据量。
- 作用:较高的吞吐量表示CPU能够高效处理大量任务,提高整体系统性能。
17. 延迟(Latency)
- 定义:任务从发出到被处理的时间延迟。
- 作用:较低的延迟表示系统响应速度快,对于实时应用尤为重要。
网络
计算机网络是由多个部分组成的复杂系统,这些部分共同工作以实现数据传输、资源共享和通信功能。
网络组成
1. 网络设备
a. 终端设备
- 计算机:包括桌面计算机、笔记本电脑、服务器等,作为网络中的数据源和数据接收者。
- 移动设备:如智能手机、平板电脑等,可以通过无线连接加入网络。
- 其他设备:如打印机、IP电话、摄像头等,能够通过网络提供各种服务。
b. 中间设备
- 路由器(Router):用于连接不同网络,负责数据包的转发和路由选择。
- 交换机(Switch):在局域网(LAN)中用于连接多个设备,基于MAC地址进行数据帧转发。
- 集线器(Hub):一种早期的网络设备,广播接收到的数据帧到所有端口(已逐步被交换机取代)。
- 网关(Gateway):连接不同网络协议的设备,充当协议转换器。
- 防火墙(Firewall):用于监控和控制进出网络的数据流,提供安全防护。
2. 网络介质
a. 有线介质
- 双绞线(Twisted Pair Cable):常用于以太网连接,有UTP和STP两种类型。
- 同轴电缆(Coaxial Cable):用于有线电视和早期的以太网连接。
- 光纤电缆(Fiber Optic Cable):通过光信号传输数据,具有高带宽和长传输距离。
b. 无线介质
- 无线电波(Radio Waves):用于Wi-Fi、蓝牙等无线通信。
- 微波(Microwaves):用于远程无线通信,如卫星通信。
- 红外线(Infrared):用于短距离无线通信,如遥控器。
3. 网络协议
a. 应用层协议
- HTTP/HTTPS:用于Web服务的超文本传输协议。
- FTP:文件传输协议,用于文件上传和下载。
- SMTP/IMAP/POP3:用于电子邮件传输的协议。
- DNS:域名系统,用于域名解析。
b. 传输层协议
- TCP:传输控制协议,提供可靠的、面向连接的通信。
- UDP:用户数据报协议,提供无连接的、不可靠的通信。
c. 网络层协议
- IP:互联网协议,负责数据包的寻址和路由选择。
- ICMP:互联网控制报文协议,用于诊断网络连接。
d. 数据链路层协议
- 以太网(Ethernet):局域网中常用的链路层协议。
- PPP:点对点协议,用于拨号连接。
4. 网络架构
a. 拓扑结构
- 星型拓扑:所有设备连接到中央交换机或集线器。
- 总线型拓扑:所有设备共享一条通信介质。
- 环型拓扑:设备连接成一个环,数据沿环传输。
- 网状拓扑:设备之间相互连接,提供多条路径。
b. 网络类型
- 局域网(LAN):覆盖小范围区域,如办公室或家庭。
- 广域网(WAN):覆盖大范围区域,如城市或国家。
- 城域网(MAN):覆盖中等范围区域,如城市。
- 个人区域网(PAN):覆盖个人范围,如蓝牙设备之间的连接。
网络通信过程
一个数据包是如何从客户端到达服务器的过程是一个复杂的、多层次的过程,涉及多个网络协议和设备。以下是一个详细的步骤描述:
1. 应用层
客户端生成请求:
- 用户在客户端应用(例如浏览器)中输入一个URL并按下回车键。
- 应用程序生成一个HTTP请求消息,并将其传递到传输层。
2. 传输层
封装为TCP/UDP段:
- 传输层(通常是TCP或UDP协议)接收应用层数据,将其封装成一个TCP段或UDP数据报。
- 如果使用TCP协议:
- TCP段头部包含源端口、目标端口、序列号、确认号、窗口大小等信息。
- TCP连接通过三次握手建立。
- 如果使用UDP协议:
- UDP数据报头部包含源端口、目标端口、长度和校验和等信息。
3. 网络层
封装为IP数据包:
- 网络层(IP协议)接收传输层段或数据报,将其封装成一个IP数据包。
- IP包头包含源IP地址、目标IP地址、TTL(生存时间)等信息。
- 路由选择算法确定数据包的最佳路径。
4. 数据链路层
封装为帧:
- 数据链路层接收IP数据包,将其封装成一个数据帧。
- 帧头部包含源MAC地址、目标MAC地址和帧校验序列(FCS)。
- 数据帧通过物理层传输到下一跳。
5. 物理层
传输数据:
- 物理层将数据帧转换为电信号或光信号,通过传输介质(如以太网、光纤或无线电波)发送到下一跳设备(如交换机或路由器)。
6. 交换机
局域网传输:
- 如果客户端和服务器在同一局域网(LAN)内,交换机会根据目标MAC地址将数据帧转发到目标服务器。
- 如果不在同一局域网内,数据帧会被转发到网关路由器。
7. 路由器
广域网传输:
- 路由器接收到数据帧,将其解封装为IP数据包。
- 路由器使用路由表查找目标IP地址的最佳路径,并将IP数据包封装成新的数据帧,发送到下一跳路由器。
- 此过程在多个路由器间进行,直至数据包到达目标局域网。
8. 目标局域网
局域网传输:
- 数据包进入目标局域网后,交换机根据目标MAC地址将数据帧转发到目标服务器。
9. 目标服务器
数据解封装:
- 服务器网络接口卡(NIC)接收数据帧,数据链路层解封装为IP数据包。
- 网络层将IP数据包解封装为TCP段或UDP数据报。
- 传输层根据目标端口号将数据传递到相应的应用程序。
10. 应用层
服务器处理请求:
- 服务器上的应用程序(例如Web服务器)接收并处理HTTP请求,生成响应消息。
- 响应消息经过相同的封装和传输过程返回给客户端。
网络参数
1. 吞吐量(Throughput)
- 定义:单位时间内成功传输的数据量,通常以比特每秒(bps)、千比特每秒(kbps)、兆比特每秒(Mbps)或千兆比特每秒(Gbps)表示。
- 影响因素:网络带宽、传输协议、网络拥塞等。
- 衡量方法:使用网络性能测试工具(如iPerf、Speedtest)进行测量。
2. 延迟(Latency)
- 定义:数据从源到目的地所需的时间,通常以毫秒(ms)表示。
- 影响因素:网络路径的长度和复杂性、路由器和交换机的处理时间、网络拥塞等。
- 衡量方法:使用ping命令测量往返时间(RTT)。
3. 抖动(Jitter)
- 定义:数据包之间传输延迟的变化量,通常以毫秒(ms)表示。
- 影响因素:网络拥塞、路由器和交换机的处理时间波动等。
- 衡量方法:使用工具(如ping、iPerf)测量连续数据包的延迟变化。
4. 数据包丢失率(Packet Loss Rate)
- 定义:传输过程中丢失的数据包比例,通常以百分比表示。
- 影响因素:网络拥塞、链路错误、硬件故障等。
- 衡量方法:使用ping或其他网络诊断工具进行数据包传输测试。
5. 连接建立时间(Connection Establishment Time)
- 定义:从发起连接请求到连接成功建立所需的时间,通常以毫秒(ms)表示。
- 影响因素:服务器响应时间、网络延迟等。
- 衡量方法:使用网络监控工具(如Wireshark)分析连接建立过程。
6. 响应时间(Response Time)
- 定义:客户端发出请求到收到服务器响应的时间,通常以毫秒(ms)表示。
- 影响因素:服务器处理能力、网络延迟、网络拥塞等。
- 衡量方法:使用Web性能测试工具(如Pingdom、GTmetrix)进行测量。
7. 并发连接数(Concurrent Connections)
- 定义:在同一时间段内网络上可以同时处理的连接数量。
- 影响因素:服务器的处理能力、网络带宽、协议栈实现等。
- 衡量方法:使用负载测试工具(如Apache JMeter)进行测量。
8. 带宽利用率(Bandwidth Utilization)
- 定义:实际使用的带宽与可用带宽的比例,通常以百分比表示。
- 影响因素:网络应用的传输需求、网络的总带宽容量等。
- 衡量方法:使用网络监控工具(如NetFlow、SNMP)进行测量。
9. 会话维持时间(Session Duration)
- 定义:一个会话从开始到结束的时间长度,通常以秒或分钟表示。
- 影响因素:应用特性、用户行为、网络稳定性等。
- 衡量方法:使用应用监控工具(如Google Analytics、New Relic)进行测量。
10. 错误率(Error Rate)
- 定义:传输过程中发生错误的比例,通常以百分比表示。
- 影响因素:网络噪声、链路错误、硬件故障等。
- 衡量方法:使用网络诊断工具(如Wireshark、ping)分析数据传输错误。
11. 流量分析(Traffic Analysis)
- 定义:分析网络上传输的数据流量,以便了解网络使用情况和发现潜在问题。
- 影响因素:网络应用的类型、用户行为、网络架构等。
- 衡量方法:使用网络流量分析工具(如Wireshark、NetFlow Analyzer)进行分析。
12. 服务质量(Quality of Service, QoS) - 定义:衡量网络服务在传输过程中对不同类型流量的优先级管理和性能保证。 - 影响因素:网络配置、QoS策略等。 - 衡量方法:使用网络监控和管理工具(如Cisco QoS)进行测量和管理。
性能分析工具
在Unity开发过程中,性能分析是确保游戏运行流畅和优化资源使用的重要步骤。市面上有很多分析工具,它们可以帮助我们识别和解决性能瓶颈。本节的主要目的是熟悉各种分析工具以及相关参数。
Unity Profiler
Unity Profiler是Unity自带的性能分析工具,功能强大,支持扩展可自定义统计数据。
Unity Profiler界面概述
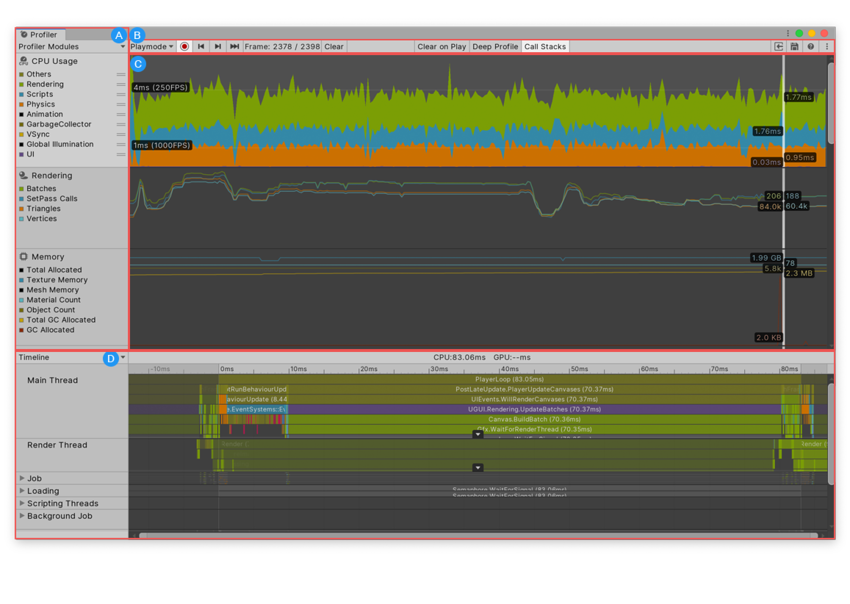
- A:Profiler的模块窗口,包括CPU,GPU,Rendering,Memory,自定义等模块
- B:工具栏,从左往右依次是:连接目标,数据记录开关,帧控制,清理,播放时清理开关,深度捕获开关,调用栈,打开profile数据,保存数据按钮,帮助按钮,设置按钮
- 深度捕获开关:开启后Unity将在每个函数(除Native函数)中添加捕获标记。
- 调用栈:可以在不开启深度捕获的情况下,捕获每个函数的内存分配
- C:帧图表区域,此区域显示每个模块捕获的性能数据图表。
- D:模块详细信息,选择一个模块后,此区域显示模块的详细数据,每个模块显示的内容不一样。
资源模块
资源模块主要包含两个:文件访问分析模块(File Access Profiler module)和资源加载分析模块(Asset Loading Profiler module),如下图:
文件访问分析模块
此模块显示有关应用程序中文件活动的信息,例如 Unity 执行的读写操作数或打开的文件句柄数(针对特定帧或捕获的所有帧)。您可以使用此信息来帮助确定应用程序执行文件操作的效率。此模块可以捕获有关您构建的应用程序文件夹结构中任何文件的文件操作的信息,或者如果您在 Unity 编辑器中运行 Profiler,则可以捕获 Unity 项目文件夹中任何文件的文件操作的信息。
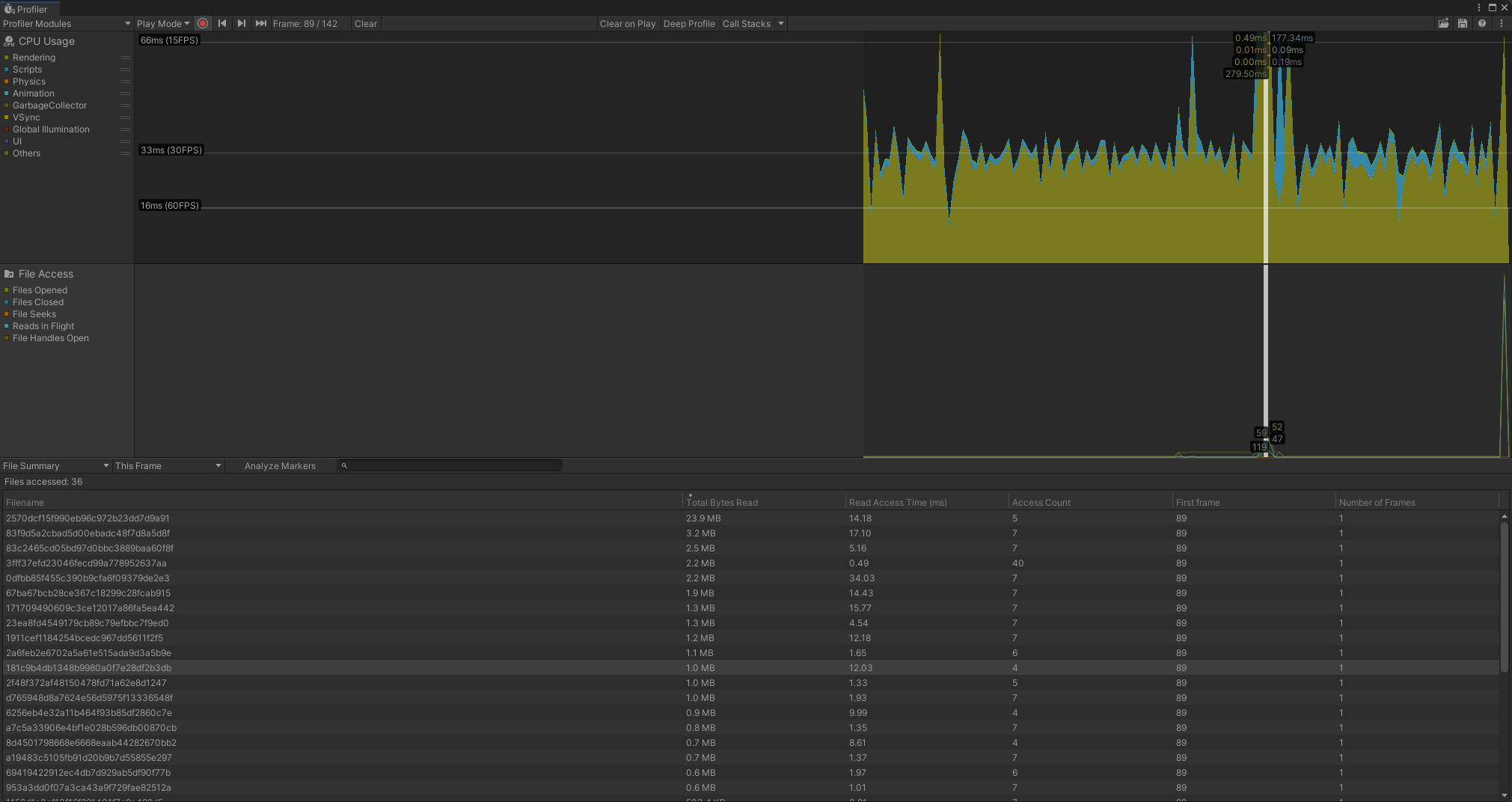
- Files Opened: 此帧期间成功打开的文件总数。
- Files Closed:此帧期间成功关闭的文件总数。
- File Seeks:此帧期间修改文件指针位置的次数。
- Reads in Flight:此帧期间正在进行的读取操作总数。
- File Handles Open:此帧期间任何时候保持打开状态的文件句柄总数。这包括Unity在同一帧内打开和关闭的文件。
资源加载分析模块
此模块显示有关应用程序如何加载资源的信息,包括按区域细分的读取操作。详细信息窗口提供了对在分析期间捕获的每个资源加载标记的深入了解。您可以使用此信息来了解应用程序加载资源的效率,并确定任何特定问题。
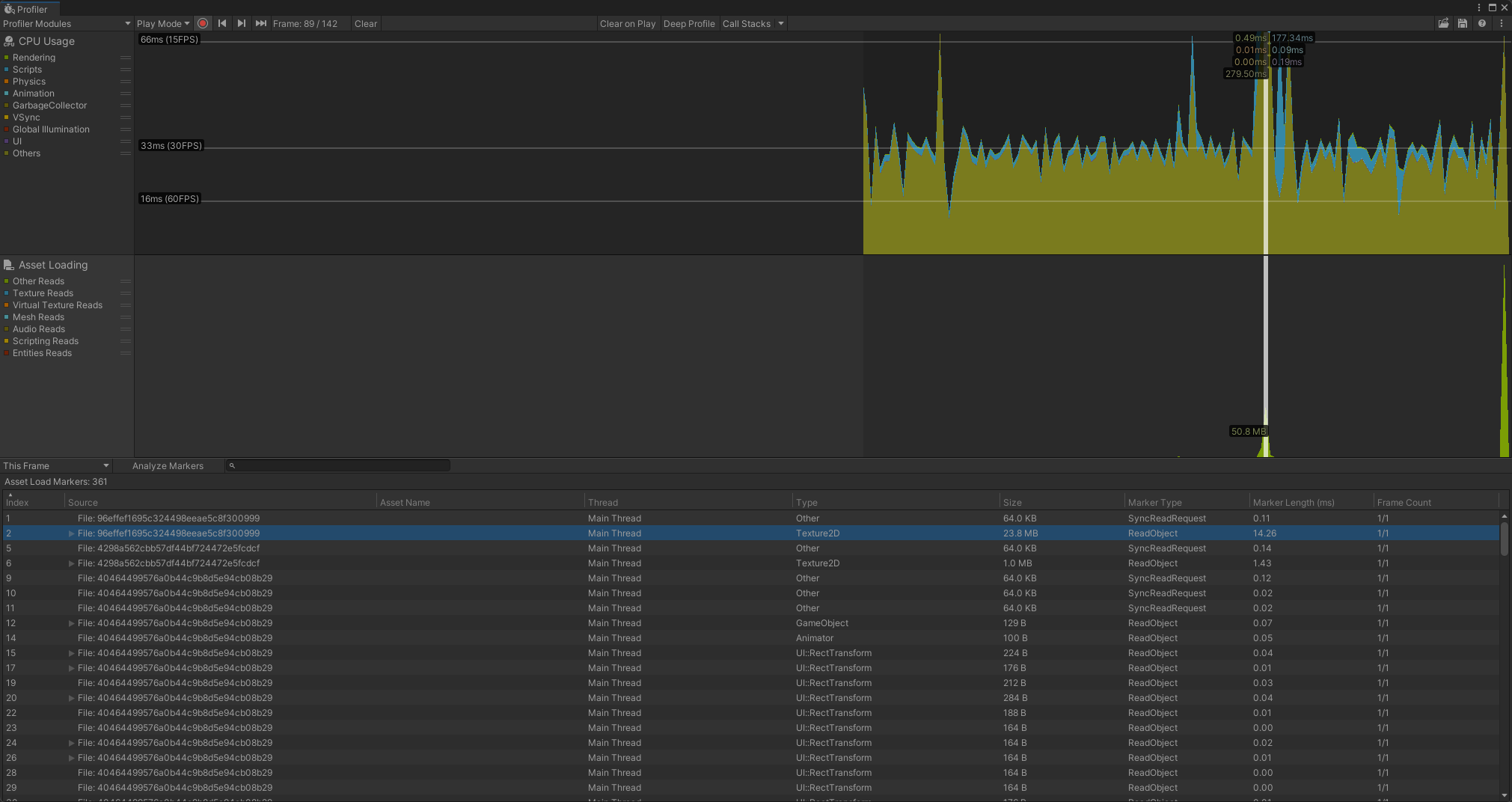
- Texture Reads: 从AsyncReadManager请求加载纹理字节数。
- Virtual Texture Reads: 从AsyncReadManager请求加载虚拟纹理字节数。
- Mesh Reads:从AsyncReadManager请求加载Mesh字节数。
- Audio Reads:从AsyncReadManager请求音频字节数。
- Scripting Reads:通过脚本API从AsyncReadManager请求的字节数。
- Entities Reads: Entities包中的脚本,从AsyncReadManager请求的字节数。
- Other Reads: 除开上面的这些分类外,向AsyncReadManager请求的字节数。
为了更好的理解文件的相关操作,我们通过一个简单的程序来分析文件的打开,定位,读写和关闭的操作。
操作系统如何处理文件
先写一个简单的文件操作程序,代码如下:
1 |
|
进程结构
我们通过Linux源码来看一下,一个进程的大致结构,这个结构体非常大,我们看几个核心的字段:
1 | //进程的结构体 |
从进程的结构体中,我们可以发现 struct files_struct *files,中存储了打开的文件信息。接下来我们去窥探一下文件的打开过程。
打开过程
在Linux内核中,open系统调用的核心代码位于fs/open.c文件中。open函数是用户空间程序用来打开文件的系统调用。以下是核心函数的详细说明:
- 系统调用入口 (sys_open)
概述: sys_open 是 open 系统调用的入口函数。它的作用是处理来自用户空间的 open 系统调用请求。
代码: 1
2
3
4SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
- 核心处理函数 (do_sys_open)
概述:
do_sys_open 是核心处理函数,负责执行实际的文件打开操作。它处理文件路径解析、权限检查、文件描述符分配等。
代码:
1 | long do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode) |
- build_open_flags:解析和验证传入的标志和模式,构建 open_flags 结构体。
- do_filp_open:执行具体的文件打开操作,并返回文件指针。
- 构建打开标志 (build_open_flags)
概述:
build_open_flags 函数解析并构建文件打开标志和模式。
代码:
1 | int build_open_flags(int flags, umode_t mode, struct open_flags *op) |
- 解析传入的 flags 和 mode 参数,并进行权限检查。
- 文件打开操作 (do_filp_open)
概述:
do_filp_open 函数处理文件路径解析、权限检查,并最终打开文件。
代码:
1 | struct file *do_filp_open(int dfd, const char *pathname, const struct open_flags *op) |
- set_nameidata:初始化 nameidata 结构体,用于路径解析。
- path_openat:解析路径并执行文件打开操作。
- 路径解析和打开 (path_openat)
概述:
path_openat 函数解析文件路径并执行具体的打开操作。
代码:
1 | struct file *path_openat(struct nameidata *nd, const struct open_flags *op, unsigned flags) |
- do_last:执行路径解析的最后一步,并打开文件。
- 最后一步解析和打开 (do_last)
概述:
do_last 函数完成路径解析的最后一步,并执行文件打开操作。
代码: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25static struct file *do_last(struct nameidata *nd, struct file *file, const struct open_flags *op)
{
struct dentry *dentry;
struct inode *dir;
// 获取目录 inode
dir = nd->path.dentry->d_inode;
// 创建或打开文件
dentry = lookup_open(nd, op, dir);
if (IS_ERR(dentry))
return ERR_CAST(dentry);
// 分配并初始化 file 结构体
file = alloc_empty_file(op->open_flag, current_cred());
if (IS_ERR(file))
return file;
file->f_path = nd->path;
file->f_inode = dentry->d_inode;
file->f_op = fops_get(dentry->d_inode->i_fop);
return file;
}
通过上述代码和解释,可以看到 open 系统调用在 Linux 内核中经过了多个步骤和函数调用,包括路径解析、权限检查、文件描述符分配等。这些步骤协同工作,确保文件能够正确地被打开,并为进程提供所需的文件访问功能, 打开的文件会放在进程的struct files_struct *files字段中。接下来我们再看一下文件指针的移动。
定位
定位的过程就是一个移动指针的过程,我们可以看一下struct file 结构体,它表示一个打开的文件,包含文件的状态和操作函数等信息。
1 | struct file { |
定义的大致流程如下:
用户空间流程:
- fseek 函数:用户程序调用 fseek 函数。
- 调用 lseek:fseek 调用 lseek 系统调用。
内核空间流程:
- 系统调用入口 (sys_lseek):处理文件描述符,调用 vfs_llseek。
- 虚拟文件系统层 (vfs_llseek):调用具体文件系统的 llseek 实现或默认 llseek 实现。
- 默认 llseek 实现 (default_llseek):计算并更新文件指针。
通过上述过程,fseek 函数实现了对文件指针的调整,从而支持文件的随机访问。内核中处理文件偏移调整的核心代码确保了这一过程的正确性和高效性。
读
在Linux内核中,读取的文件内容通过多个层次的缓存机制存储和管理,主要涉及以下几个关键组件和数据结构:
页缓存(Page Cache)
地址空间(Address Space)
缓冲区头(Buffer Head)
页缓存(Page Cache) 页缓存是Linux内核用于缓存文件数据的主要机制。当文件被读取时,文件的内容首先会被缓存到页缓存中。页缓存是由多个内存页(通常是4KB)组成的。
相关数据结构:
- struct page:表示一个物理内存页。
- struct address_space:表示文件或设备的地址空间。
页缓存读取过程:
- 当用户进程通过系统调用(如 read)请求读取文件时,内核首先检查页缓存中是否存在请求的数据。
- 如果数据在页缓存中,则直接从页缓存返回数据。
- 如果数据不在页缓存中,则从磁盘读取数据到页缓存中,然后返回给用户进程。
- 地址空间(Address Space)
每个文件或设备都有一个地址空间(address_space),用于管理该文件或设备的页缓存。
struct address_space 结构体: 1
2
3
4
5
6
7
8
9
10
11
12struct address_space {
struct inode *host; /* 关联的 inode */
struct radix_tree_root page_tree; /* 用于存储页缓存的树结构 */
spinlock_t tree_lock; /* 保护 page_tree 的自旋锁 */
unsigned int i_mmap_writable; /* 可写映射计数 */
struct rb_root i_mmap; /* 区域映射的红黑树 */
struct list_head i_mmap_nonlinear;
atomic_t truncate_count; /* 文件截断计数 */
unsigned long nrpages; /* 页缓存中的页数 */
pgoff_t writeback_index; /* 写回索引 */
// 其他字段...
};
- 缓冲区头(Buffer Head)
在较老的文件系统中(如 ext2),缓冲区头(buffer_head)结构体用于管理磁盘块和页缓存之间的关系。现代文件系统(如 ext4)更多地依赖直接的页缓存管理。
struct buffer_head 结构体:
1 | struct buffer_head { |
从文件读取内容的典型流程,包括页缓存的使用:
- 系统调用接口:用户进程调用 read 系统调用请求读取文件。
- 文件系统层:文件系统的 read 方法处理读取请求。
- 页缓存检查:文件系统检查页缓存中是否已有请求的数据。
- 如果数据在页缓存中,则直接返回数据。
- 如果数据不在页缓存中,则从磁盘读取数据到页缓存,然后返回给用户进程。
- 返回用户空间:读取的数据被拷贝到用户进程的缓冲区中。
关闭
关闭文件时,内核执行的关键步骤包括:
- 获取并释放文件描述符:从文件描述符表中删除对应的项。
- 减少引用计数:调用 fput 减少文件指针的引用计数。
- 最终清理:如果引用计数为0,调用 __fput 进行文件指针的最终清理,包括刷新数据、通知文件系统、清除 inode、释放路径、调用文件系统的 release 方法,最终释放文件结构。
内存模块
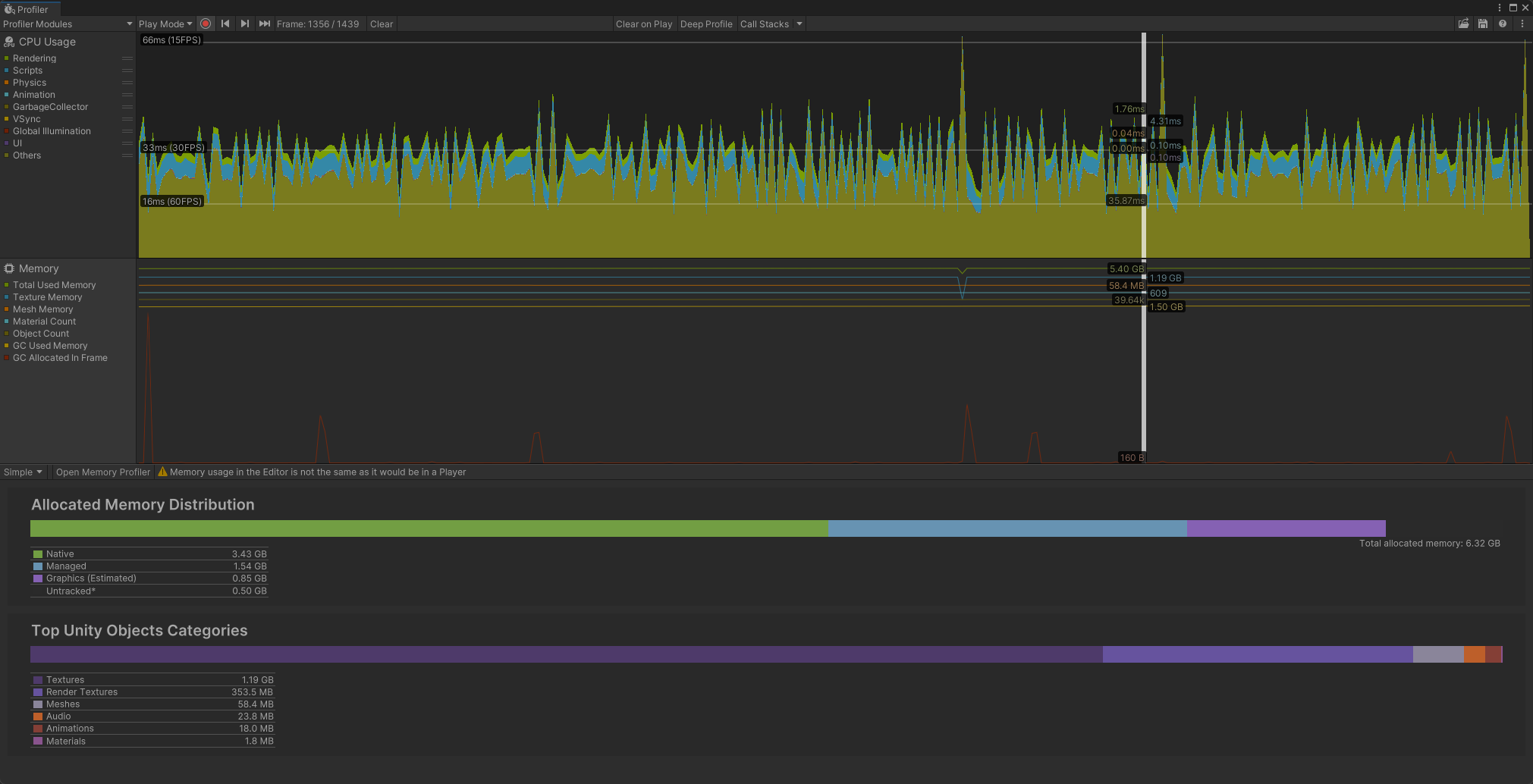
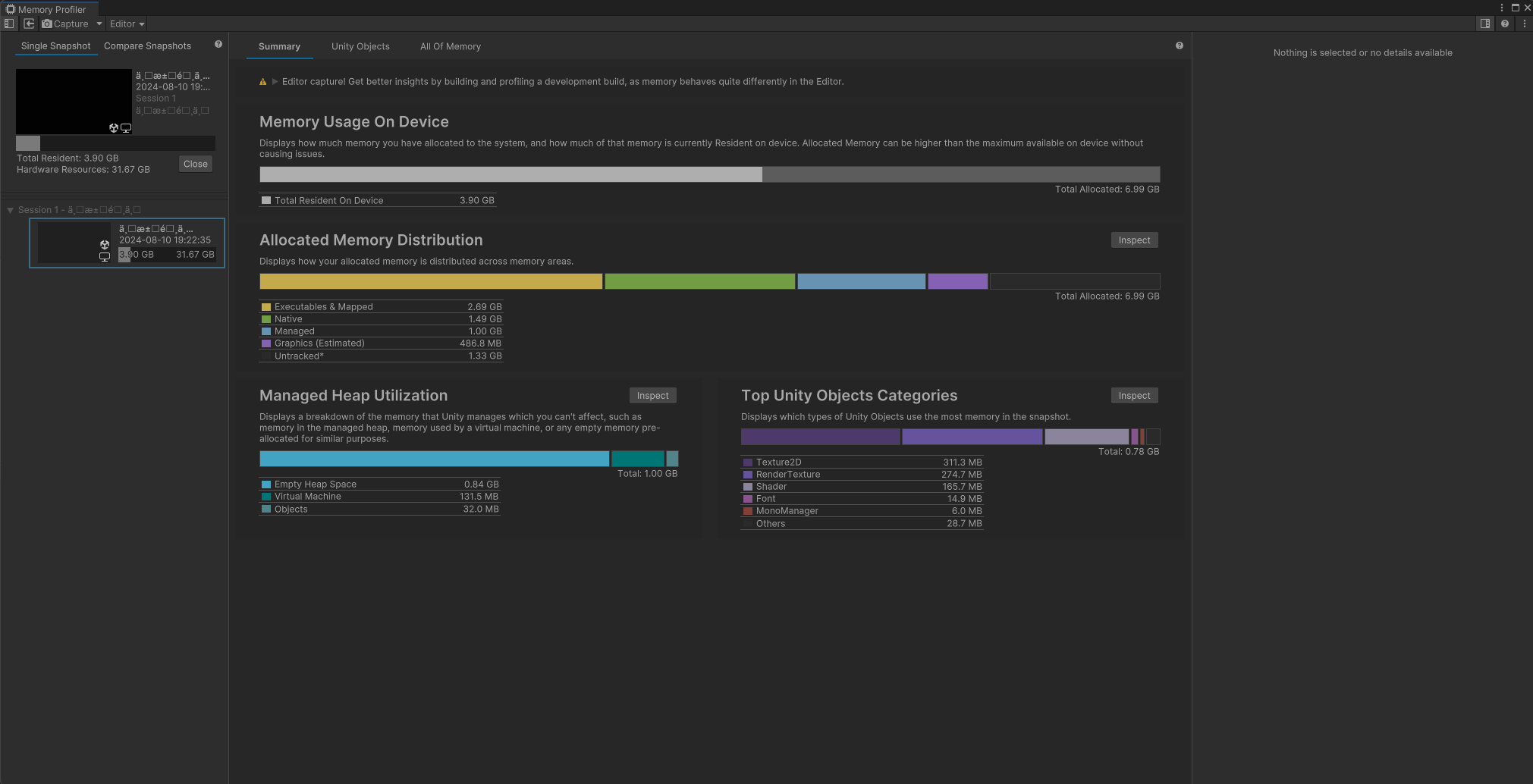
在Unity中,有两种方法可以分析应用程序的内存使用情况:
内存分析器模块:内置的分析器模块,提供应用程序使用内存的基本信息。 内存分析器包:是一个可以添加到项目中的Unity包。它会向Unity编辑器添加一个额外的内存分析器窗口,然后我们可以使用它更详细地分析应用程序中的内存使用情况。也可以存储和比较快照以查找内存泄漏,或者查看内存布局以查找内存碎片问题。
内存分析器模块会直观显示应用中分配的总内存量的计数器。可以使用内存模块查看已加载对象的数量以及每个类别中它们总共占用的内存量等信息。还可以查看每帧的GC分配数量。
在编辑器模式下的内存分析可能和实际的运行在目标平台上捕获到的内存存在差异,这主要是因为,当我们在编辑器中分析应用程序时,内存分析器模块报告的内存使用量比在目标设备上构建的应用程序的类似分析结果更高。这是因为Unity编辑器使用特定对象占用额外的内存,以及编辑器窗口本身使用额外的内存。 额外内存的主要原因是Unity将对象(如纹理)视为编辑器中启用的读/写功能,并在CPU上保留每个纹理的额外副本。这实际上使编辑器中报告的纹理内存使用量翻倍;为了更准确地了解纹理的内存使用情况,需要在目标平台上运行的应用程序的构建版本进行分析。
此外,由于Unity也无法将Profiler本身占用的内存与播放模式的内存完全分开,因此Profiler使用的内存会显示在Profiler窗口中。
内存分析器模块
内存分析器包
内存分布概述
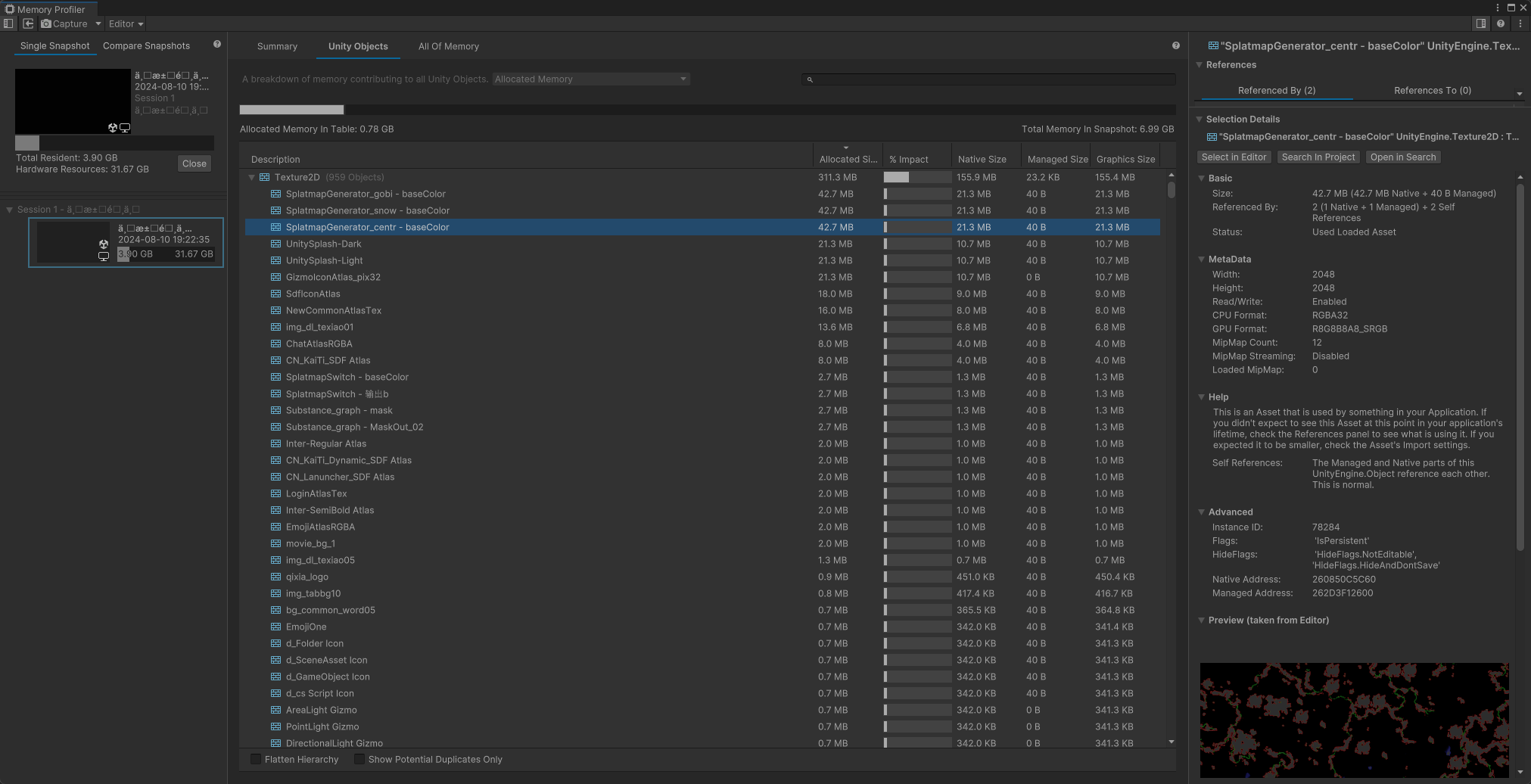
详细的Unity的对象
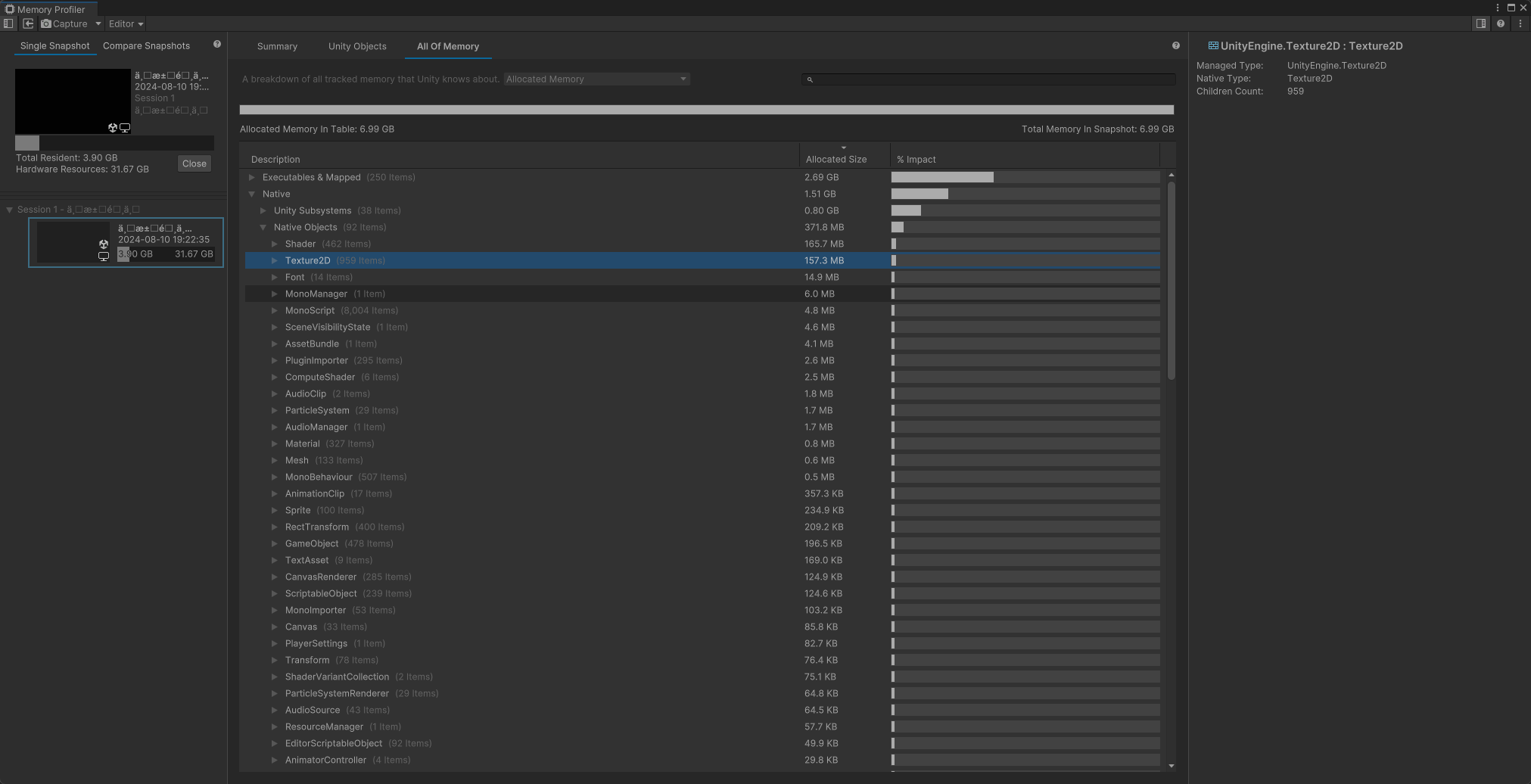
所有的内存对象
内存分析器包 可以对两次的内存快照进行比较,那确定是否有内存泄漏。
操作系统如何管理内存
在Linux操作系统中,当进程启动时,内存分配和管理是通过多个步骤和系统调用来完成的。
- 进程创建与内存分配的概述
当一个进程被创建时,通常是通过fork()系统调用来复制一个现有进程的内存空间。内存分配涉及到以下几个关键点:
- 虚拟内存空间的创建
- 页表的建立与管理
- 实际物理内存的分配
- 关键的数据结构
2.1 进程描述符(task_struct)
每个进程在Linux中都有一个task_struct结构体,该结构体保存了进程的所有信息,包括内存管理信息。这个结构体在include/linux/sched.h中定义。
1 | struct task_struct { |
2.2 内存描述符(mm_struct)
mm_struct是进程内存管理的核心结构,它描述了进程的虚拟地址空间。它在include/linux/mm_types.h中定义。
1 | struct mm_struct { |
- 内存管理的主要流程
3.1 进程创建(fork())时的内存分配
- 当 fork() 被调用时,Linux会为新进程创建一个新的task_struct以及一个新的mm_struct。
- copy_mm() 函数被调用以复制父进程的内存管理结构。该函数在 kernel/fork.c 中定义。
1 | static struct mm_struct *copy_mm(unsigned long clone_flags, struct task_struct *tsk) |
mm_dup()函数会复制父进程的mm_struct到子进程,同时通过copy_page_range()来复制父进程的页表。
3.2 虚拟内存区域(vm_area_struct)的管理
虚拟内存区域 (vm_area_struct) 结构体描述了进程地址空间的连续区间,每个区间对应着不同的权限和用途(如代码段、数据段、堆、栈等)。
1 | struct vm_area_struct { |
这些结构在include/linux/mm_types.h中定义。
3.3 物理内存的分配
实际的物理内存分配通常发生在需要访问某个页面(页缺失)的时刻。Linux使用按需分页机制,初始进程并不会立即分配所有物理内存。
当发生页缺失时,内核会通过 do_page_fault() 处理页缺失中断,并调用 alloc_page() 或 __get_free_pages() 来分配物理页面。alloc_page() 在 mm/page_alloc.c 中定义。
1 | struct page *alloc_page(gfp_t gfp_mask) |
__alloc_pages() 是分配物理页的核心函数,负责找到合适的内存区域并标记为已分配。
malloc和realloc实现
malloc和realloc是用户空间内存分配函数,通常用于在C程序中动态分配和调整内存块的大小。在Linux系统中,malloc和realloc 的具体实现是通过C标准库(glibc)提供的,而不是直接由内核实现的。这些函数的底层实现涉及到内存管理函数,如brk和mmap,以便在进程的虚拟地址空间中分配内存。
- malloc的实现
malloc函数用于从堆中分配指定大小的内存块。其具体实现涉及以下几个步骤:
1.1 内存分配算法
malloc在内部分配内存时,通常使用一些分配算法,如first fit、best fit 或 worst fit。glibc实现通常使用binning技术,将不同大小的内存块放入不同的“垃圾桶”(bins)中,以便更快速地找到合适的内存块。
1.2 核心数据结构
glibc的malloc实现使用了多个核心数据结构,其中最重要的是malloc_state和malloc_chunk:
- malloc_state: 代表一个分配器的状态,包括用于管理内存块的bins。
- malloc_chunk: 表示内存块的头部,用于记录块的大小和状态(是否已使用等)。
这些数据结构在glibc的malloc/malloc.c文件中定义。
1.3 实现细节
当malloc被调用时,glibc会首先检查是否有合适大小的空闲内存块。如果没有,则调用sbrk()或mmap()从操作系统请求新的内存。
1 | void *malloc(size_t size) { |
_int_malloc是malloc的内部实现函数,它负责从适当的bin中查找或分配内存块。
- realloc的实现
realloc函数用于调整已分配内存块的大小。其实现相对复杂,因为它不仅需要调整内存块的大小,还可能需要将数据移动到新位置。
2.1 内存调整逻辑
- 如果现有的内存块足够大,则直接缩小或扩展该块。
- 如果现有的内存块无法满足要求,realloc 会分配一个新的内存块并将旧内存的数据复制到新块中。
2.2 实现细节
realloc的实现也是在glibc的malloc/malloc.c 文件中完成的:
1 | void *realloc(void *ptr, size_t size) { |
_int_realloc是realloc的内部实现函数,它处理内存块的调整:
- 如果新块比旧块小,直接修改块的大小。
- 如果新块比旧块大且相邻块有足够的空间,扩展现有块。
- 如果扩展不可能,则分配新块并复制数据。
- Linux内核的支持
malloc和realloc的底层依赖于Linux内核的系统调用,例如:
- brk():用于调整数据段的结尾,从而扩展或缩小堆。malloc在小规模内存分配时使用brk()。
- mmap():用于直接映射内存区域。malloc 在大规模内存分配时使用 mmap(),并且这种分配方式不受堆的限制。
1 | void *sbrk(intptr_t increment) { |
do_brk在mm/mmap.c中定义,是实际执行堆扩展的函数。
free实现
free()函数在C语言中用于释放先前通过malloc()、calloc()(内存数据重置为0)、realloc()等函数分配的动态内存。它的具体实现依赖于底层的内存管理机制,并且在C标准库中通常通过glibc提供。free()的实现涉及对已分配内存块的管理、合并空闲块以及可能的内存释放回操作系统等操作。
- free()的概述
free()函数的主要功能是将动态分配的内存块标记为可用,并将其返回到内存分配器的空闲列表中,以供后续内存分配使用。它不会修改指针本身(即,不会将指针置为 NULL),并且不会清除内存内容,只是将内存块释放。
- free()的实现概述
free()的实现主要包含以下步骤:
检查指针有效性: 检查传递给 free() 的指针是否为空或无效。
获取内存块信息: 从指针推导出内存块的头部信息,通常通过指针减去一定的偏移量来获得内存块的头部信息。
合并相邻的空闲块: 如果被释放的内存块与相邻的内存块都是空闲的,内存分配器会尝试将这些块合并,以减少内存碎片。
更新空闲列表: 将释放的内存块插入到空闲列表或合适的 bin 中,以便在后续的内存分配请求中再次使用。
具体实现细节
下面详细说明free()的实现,基于glibc中的malloc实现。glibc的内存分配器基于ptmalloc,它是一种基于dlmalloc的分配器。
3.1 核心数据结构
glibc使用malloc_chunk结构体来描述内存块,它的定义通常在malloc.c中:
1 | struct malloc_chunk { |
- prev_size: 如果前一个块空闲,则保存其大小。
- size: 当前块的大小及一些状态标志位(如是否空闲)。
- fd和bk: 空闲链表中的前后指针。
3.2 free() 的实现
glibc中free()的实现大致如下(在 malloc.c 中):
1 | void free(void* ptr) { |
3.3 关键函数说明
- mem2chunk(ptr): 将用户指针转换为内存块的头部指针(即malloc_chunk结构体指针)。通常通过从ptr指针向前偏移来获得。
- chunksize(p): 获取内存块的大小,包括头部信息。通常通过访问malloc_chunk结构体的size字段来获得。
- unlink(p, bck, fwd): 从空闲列表中移除当前块。如果当前块已经空闲,意味着它可能被错误地多次释放或者存在内存管理上的问题。
- consolidate(p): 尝试合并当前块与前后相邻的空闲块,以减少内存碎片。这有助于将多个小的空闲块合并成一个更大的块,从而更好地利用内存。
- munmap_chunk(p): 如果内存块是通过mmap()分配的(通常用于分配大块内存),则直接使用munmap()释放该内存块。
CPU模块
CPU使用率分析器模块包含一个图表,显示应用程序在哪些地方花费了时间。它概述了应用程序在哪些重要方面花费了时间,例如渲染、其脚本和动画。
模块详细信息窗口有三个视图模式: - Timeline: 显示特定帧的计时明细,以及帧长度的时间轴。这是唯一可用于同时查看所有线程的计时以及帧内发生计时的视图模式,以便您可以关联线程之间的计时(例如,作业系统工作线程在主线程上的系统对其进行调度后启动)。 - Hierarchy: 按内部层次结构对时间数据进行分组。此选项以降序列表格式显示应用程序调用的元素,默认按所用时间排序。您还可以按分配的脚本内存量 ( GC Alloc ) 或调用次数对信息进行排序。要更改对表格进行排序的列,请点击表格列的标题。 - Raw Hierarchy: 以与发生计时的调用堆栈类似的层次结构显示计时数据。在此模式下,Unity 会单独列出每个调用堆栈,而不是像在层次结构视图中那样合并它们。
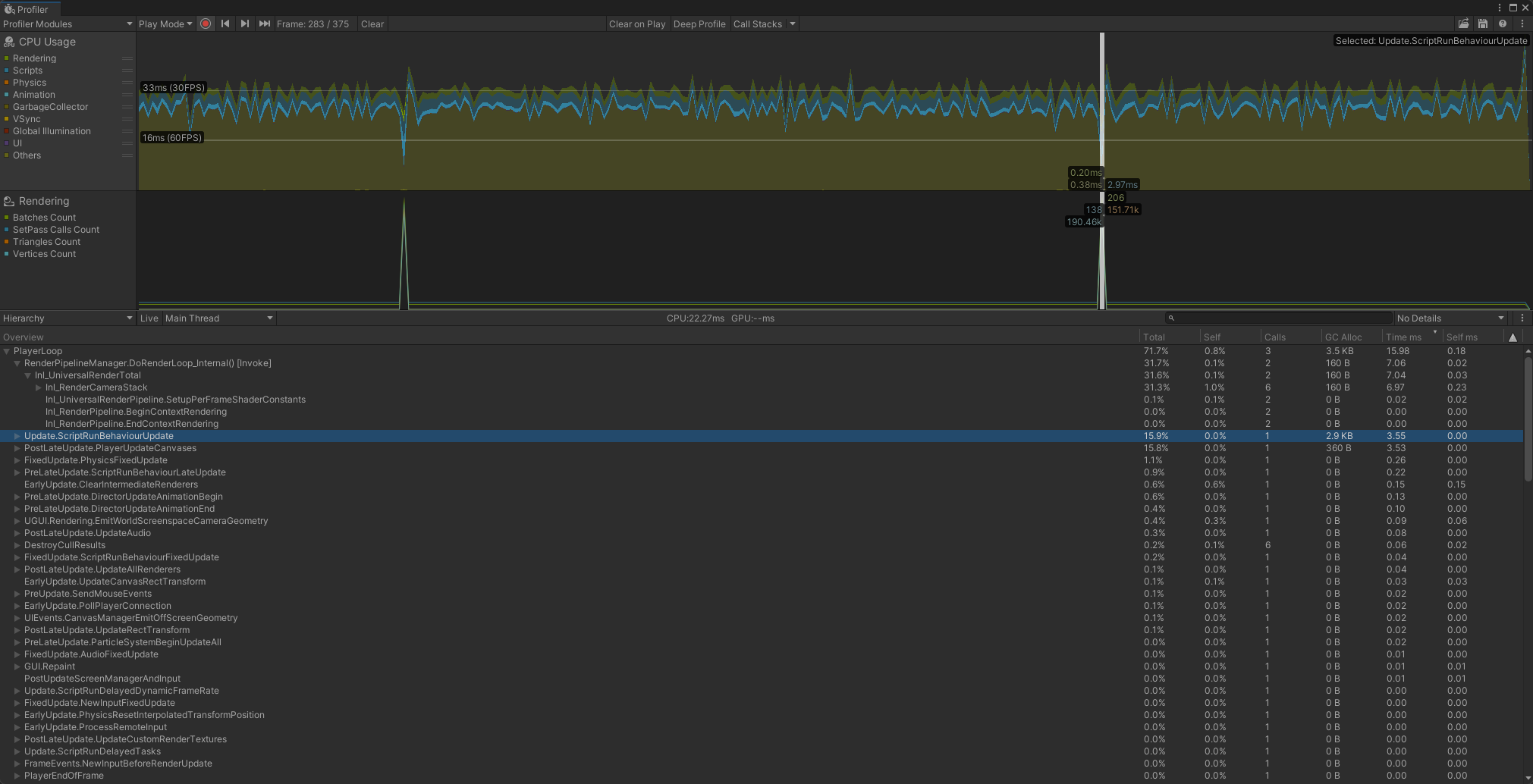
前面说的文件和内存资源都属于进程的资源,这些资源可以被进程中的线程进行共享访问,每个进程创建时都会相应的创建一个主线程。 从Timeline视图模式看,Unity创建多个线程,分别处理不同的任务,主要有:主线程(Main Thread)、渲染线程(Render Thread)、工作线程(Job Thread)和加载线程(Loading Thread)等。 下面看一下进程与线程的关系,以及线程的创建,执行和销毁相关的系统调用。
进程与线程
在Linux操作系统中,进程管理线程的方式、线程的创建、执行和销毁是通过一系列系统调用和内核机制实现的。这些操作涉及到Linux内核的调度器、进程控制块(PCB)、线程控制块(TCB)等关键概念。
- 进程与线程的关系 在Linux中,线程可以被视为一种特殊的进程,称为“轻量级进程”(Lightweight Process, LWP)。多个线程共享同一个进程的资源(如内存空间、文件描述符等),但每个线程有自己独立的栈、寄存器和线程控制块(TCB)。
- 进程:在Linux中,进程是资源分配的基本单位。
- 线程:线程是调度的基本单位,它们共享进程的资源,但可以独立执行。 Linux内核将线程和进程统一管理,线程本质上是通过clone()系统调用创建的一个进程,只是它共享了父进程的某些资源。
- 线程的创建
线程的创建主要依赖于clone()系统调用,它在Linux内核中是创建新进程或线程的核心机制。线程可以通过pthread_create()函数或直接使用 clone()系统调用来创建。
2.1 clone()系统调用
clone()是Linux中创建新进程或线程的核心系统调用。它允许新创建的进程/线程共享其父进程的资源,如内存地址空间、文件描述符、信号处理等。clone()的行为由传递的标志位(flags)决定。
1 |
|
- fn: 新线程执行的函数。
- child_stack: 新线程的栈指针。
- flags: 指定资源共享的标志,如 CLONE_VM(共享内存空间),CLONE_FS(共享文件系统信息)等。
- arg: 传递给线程函数的参数。
2.2 do_fork() 函数
clone()调用内核中的do_fork()函数来实际创建新线程(或进程)。do_fork()负责创建新的task_struct,并初始化线程的各种资源。
1 | long do_fork(unsigned long clone_flags, unsigned long stack_start, |
2.3 copy_process()函数
copy_process()是创建新线程的核心函数。它复制父进程的task_struct并进行必要的初始化,包括设置线程的状态、分配内核栈、处理信号等。
1 | struct task_struct *copy_process(struct pid *pid, int trace, int node, struct kernel_clone_args *args) |
- dup_task_struct(): 复制当前进程的 task_struct。
- p->mm = current->mm: 如果 CLONE_VM 标志设置,子线程与父线程共享内存空间。
- 线程的执行
线程创建后,内核调度器将其放入就绪队列,等待调度器分配CPU执行。线程的执行过程与普通进程相同。
3.1 调度器
Linux调度器是内核负责分配CPU时间给线程的组件。调度器决定哪个线程获得CPU执行,并处理线程的上下文切换。
1 | void __sched schedule(void) |
- pick_next_task(): 选择下一个要执行的线程。
- context_switch(): 执行上下文切换,保存当前线程的状态并加载下一个线程的状态。
3.2 上下文切换
上下文切换涉及保存当前线程的CPU寄存器、程序计数器等状态,并加载要执行的线程的状态。Linux通过switch_to()函数完成上下文切换。
1 |
|
- switch_to(): 完成实际的上下文切换,将 CPU 执行权转移到 next 线程。
- 线程的销毁
线程的销毁发生在线程完成其任务并退出时。线程的销毁涉及资源的释放、状态的更新和通知父线程。
4.1 do_exit()函数
do_exit()是线程或进程退出时调用的核心函数。它负责清理线程的资源,将线程标记为僵尸状态,并通知父线程。
1 | void do_exit(long code) |
- exit_mm(): 释放内存资源。
- exit_files(): 关闭打开的文件。
- notify_parent(): 通知父进程线程已经退出。
4.2 release_task()函数
release_task()负责最终清理僵尸线程的资源,并将其从系统中移除。
1 | void release_task(struct task_struct *p) |
- list_del_rcu(): 将任务从链表中删除。
- free_task_struct(): 释放 task_struct 相关资源。
渲染模块
显示渲染统计数据以及有关CPU和GPU渲染内容的信息,我们可以通过这些统计数据来衡量场景中不同区域的资源强度,这对于优化很有帮助。
该图表显示应用程序渲染的批次(Batches)、SetPass调用、三角形和顶点的数量。下方窗口显示更多渲染统计数据。
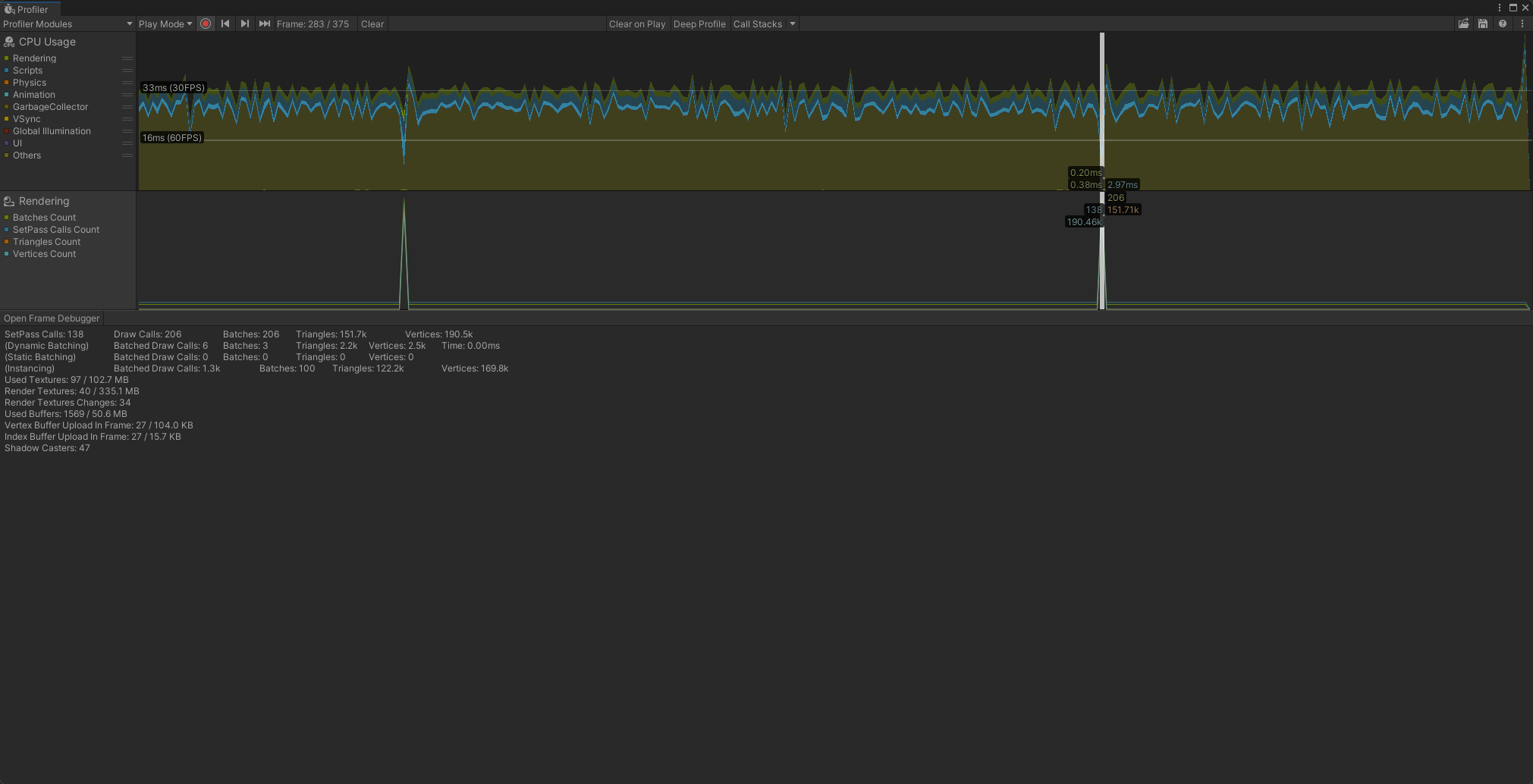
为了更好的理解上面的这些参数,我们将以伪代码的方式说明一下Unity渲染对象的流程。
在Unity中,渲染流程涉及多个步骤和概念,其中包括SetPass Calls、Draw Calls和Batches。理解这些概念及其在渲染流程中的作用,对优化Unity项目的性能至关重要。
- 渲染流程简述
- 场景处理: Unity根据摄像机的视角,计算出当前帧内所有可见的物体(Renderers)。
- SetPass Calls: 针对每个不同材质的物体,Unity会发起一次SetPass Call,将材质(Shader,参数和贴图等)绑定到GPU。
- Draw Calls: 对每个可见物体,Unity向GPU发送渲染指令,通过Draw Call绘制物体。
- Batching: Unity尝试通过合批技术(动态,静态,GPU Instancing等),将多个Draw Calls合并为一个,以减少开销。
- SetPass Calls
- 定义: SetPass Call是指在渲染管线中,Unity将材质(Material)和着色器(Shader)切换到GPU的过程。每次需要更换材质或着色器时,都会产生一次SetPass Call。
- 源码分析: 在Unity内部,SetPass Call通常是通过调用Material.SetPass()来实现的。这会将当前材质的渲染状态绑定到GPU,从而为后续的Draw Call做好准备。
- 性能影响: SetPass Calls相对昂贵,因为它们涉及GPU状态的切换,频繁的SetPass Calls会显著增加渲染开销。
- 优化:
- 合并相同材质的对象以减少SetPass Calls。
- 使用图集(Texture Atlas)来减少材质切换。
- Draw Calls
- 定义: Draw Call是指从CPU向GPU发出的一次渲染指令,用于绘制一个或多个三角形。每次调用Graphics.DrawMesh或Renderer.Render等渲染函数时都会产生Draw Call。
- 源码分析: 在Unity的渲染过程中,Draw
Call通常是通过以下流程产生的:
1
2
3
4
5
6
7
8
9
10
11
12// 伪代码说明Draw Call的处理流程
foreach (var renderer in visibleRenderers)
{
if (renderer.isVisible)
{
// 准备材质和Shader
renderer.material.SetPass(0);
// 触发一个绘制
Graphics.DrawMesh(renderer.mesh, renderer.transform.localToWorldMatrix, renderer.material, renderer.gameObject.layer);
}
} - 性能影响: Draw Calls是Unity渲染流程中的核心部分,过多的Draw Calls会导致CPU和GPU之间的通信瓶颈。
- 优化:
- 使用动态合批(Dynamic Batching)和静态合批(Static Batching)。
- 合并网格(Mesh)以减少Draw Calls。
- Batches
- 定义: Batches是指将多个Draw Calls合并为一个,以减少CPU与GPU之间的通信次数。在Unity中,合批技术可以分为静态合批(Static Batching)、动态合批(Dynamic Batching)和GPU Instancing。
- 源码分析:
- 静态合批: 当多个静态对象使用相同的材质时,Unity会将它们的网格合并为一个以减少Draw Calls。
- 动态合批: 适用于动态对象,小型网格的对象在满足一定条件时会被合并为一个Draw Call。
- GPU Instancing: 适用于同一个网格实例的多次渲染,将同一网格对象的多个实例合并为一个Draw Call。
1
2
3
4
5
6
7// GPU Instanceing
for (int i = 0; i < instanceCount; i++)
{
matrixArray[i] = Matrix4x4.TRS(positions[i], Quaternion.identity, Vector3.one);
}
materialPropertyBlock.SetMatrixArray("_Matrices", matrixArray);
Graphics.DrawMeshInstanced(mesh, 0, material, matrixArray, instanceCount, materialPropertyBlock); - 性能影响: 合批可以显著减少Draw Calls的数量,从而提高渲染性能。
- 优化:
- 对于静态物体,启用静态合批。
- 确保动态物体使用相同的材质和网格,以便动态合批生效。
- 使用GPU Instancing渲染大量相同的对象。
UI模块
UI和UI细节分析器模块提供有关Unity在应用程序中布局和渲染用户界面所花费的时间和资源的信息。我们可以使用此模块了解Unity如何处理应用程序的UI批处理,包括批处理对象的原因和方式。我们可以使用此模块找出UI的哪个部分导致性能缓慢,或者在拖动时间轴时预览UI。
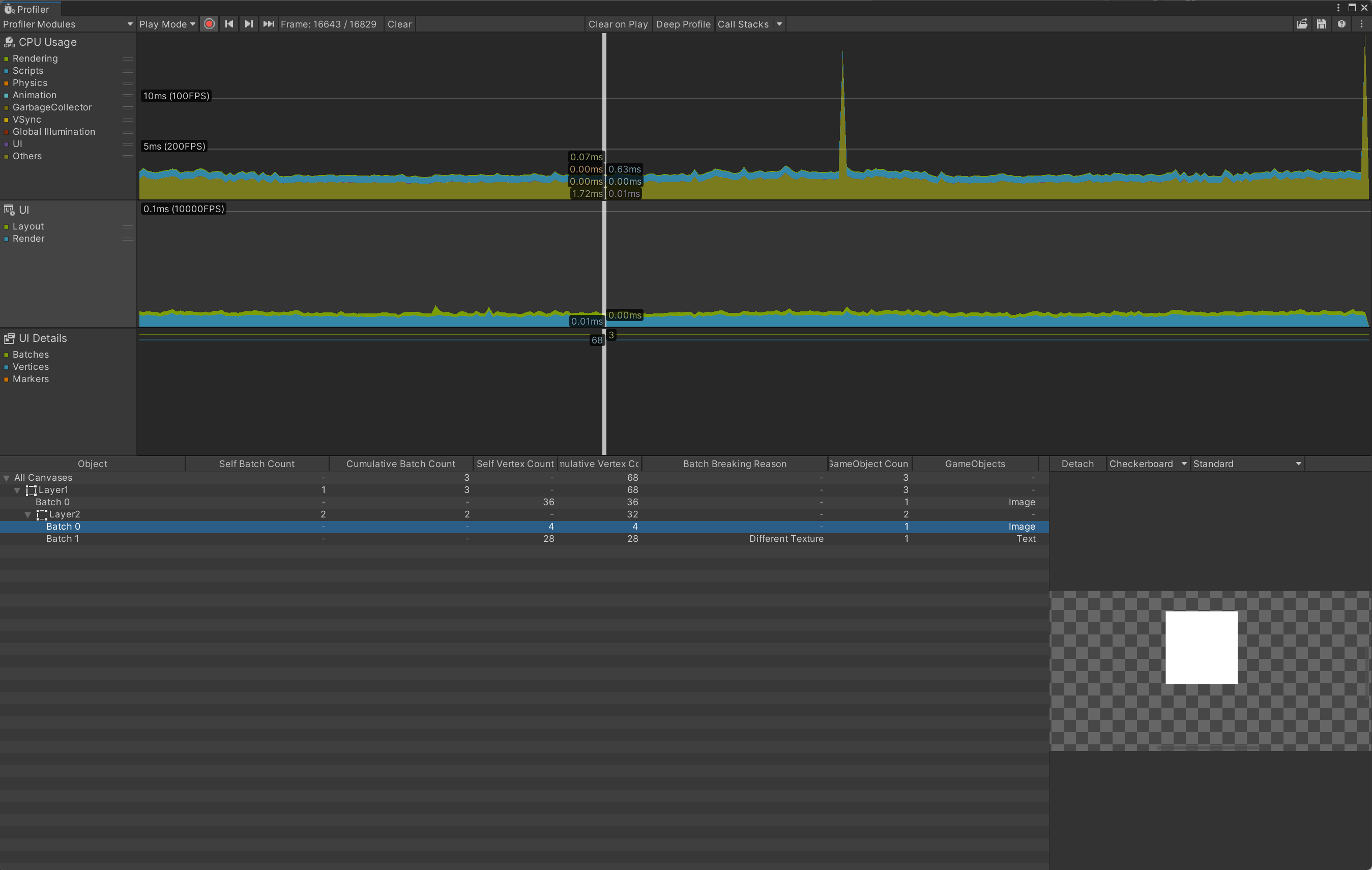
- Layout: Unity执行UI布局过程所花费的时间。这包括HorizontalLayoutGroup、VerticalLayoutGroup和GridLayoutGroup所做的计算。
- Render: UI花费多少时间完成其渲染部分。这是直接渲染到图形设备或渲染到主渲染队列的成本。
- Batches: 显示批处理在一起的绘制调用总数。
- Vertices: 用于渲染UI部分的总顶点数。
- Markers: 显示事件标记。Unity会在用户与UI交互时记录标记(例如,单击按钮或更改滑块值),然后将其绘制为图表上的垂直线和标签。
模块详细信息面板
Object:在分析期间,应用程序使用的UI画布列表。双击某一行可突出显示匹配的对象场景。
Self Batch Count: Unity为画布生成了多少个批次。
Cumulative Batch Count:Unity为画布及其所有嵌套画布生成了多少个批次
Self Vertex Count:该画布正在渲染多少个顶点。
Cumulative Vertex Count:此画布和嵌套画布正在渲染多少个顶点
Batch Breaking Reason:Unity拆分批次的原因。有时Unity可能无法将对象一起进行批处理。常见原因包括:
- 不与Canvas共面,批处理需要对象的矩形变换与画布共面(未旋转)。CanvasInjectionIndex ,其中存在
- CanvasInjectionIndex, 组件并强制进行新批次,例如当它在其余组件之上显示组合框的下拉列表时。
- 不同的材质实例、矩形裁剪、纹理或A8TextureUsage,其中Unity只能将具有相同材质、遮罩、纹理和纹理通道等完全相同的对象进行批处理。
GameObject Count:此批次中有多少个 GameObject
GameObjects:批次中的游戏对象列表。
UGUI的绘制过程,参见UGUI源码分析
物理模块(2D/3D)
物理学分析器模块显示物理系统在项目中处理的物理信息。这些信息可以帮助您诊断和解决与项目场景中的物理相关的性能问题或意外差异。
直接上2张图吧,这个内容比较直观,手游项目中也不重度使用物理系统,官方文档Physics Profiler module。 3D物理模块
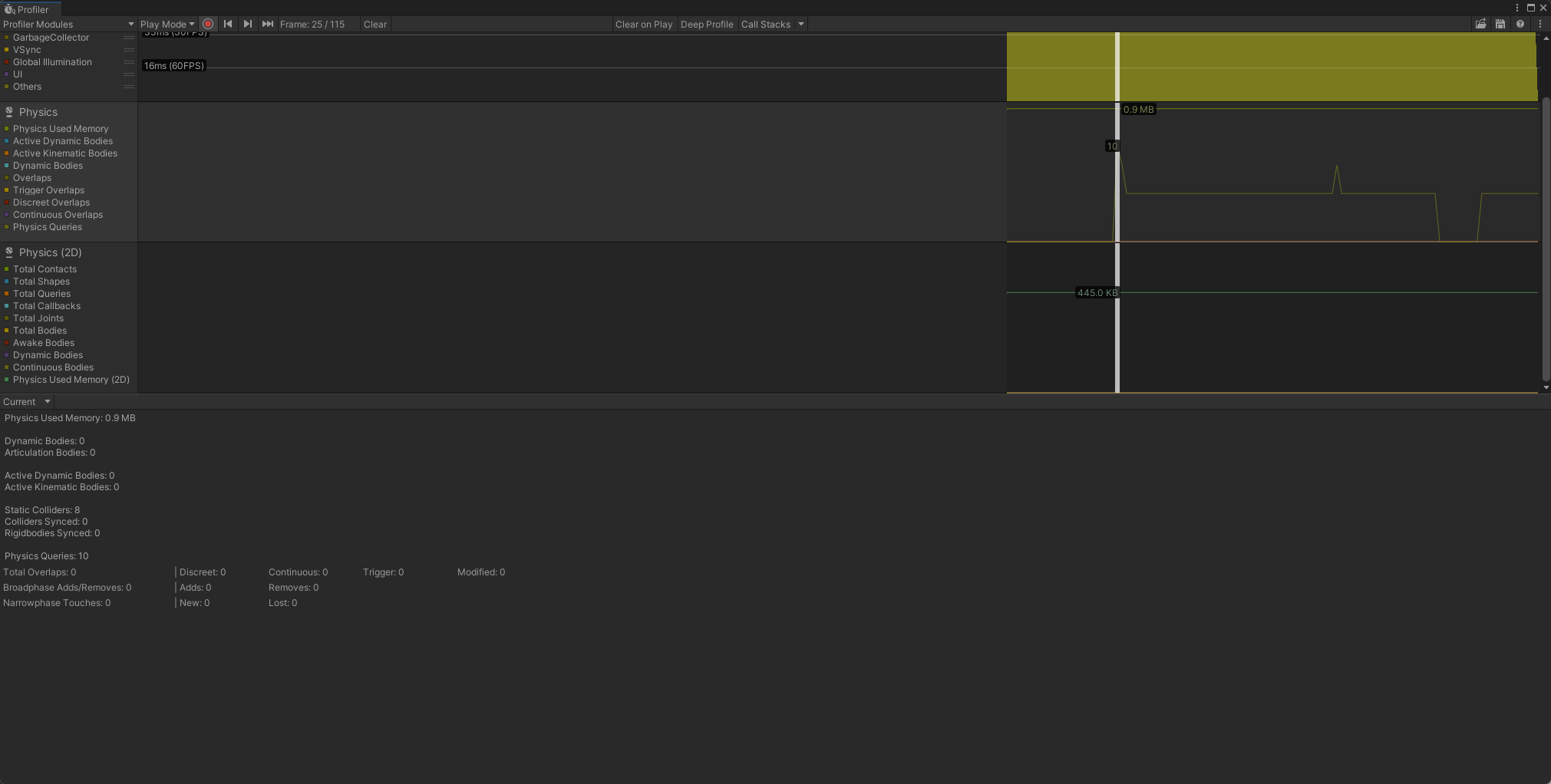
2D物理模块
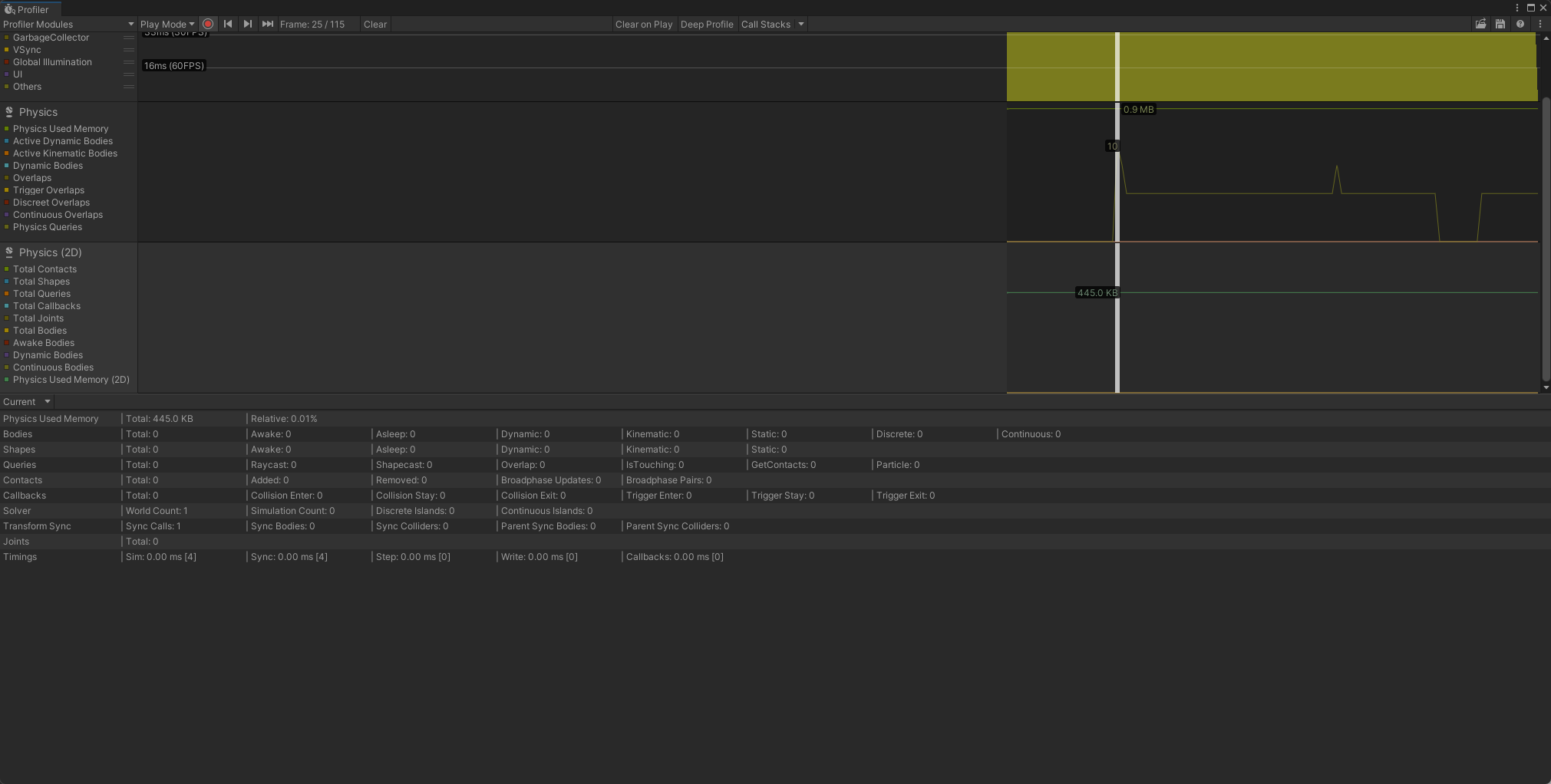
Unity的3D物理系统使用的是NVIDIA的PhysX,2D物理系统使用的是开源的Box2D。
自定模块
Unity为我们提供了自定捕获性能的接口,并可以在Unity Profiler窗口中进行查看,也可以根据内建的Counter和自定义的Counter创建自定Profiler模块,并且可以自定义详细面板,也为Native代码提供接口收集性能数据和监听Profiler中触发的事件。
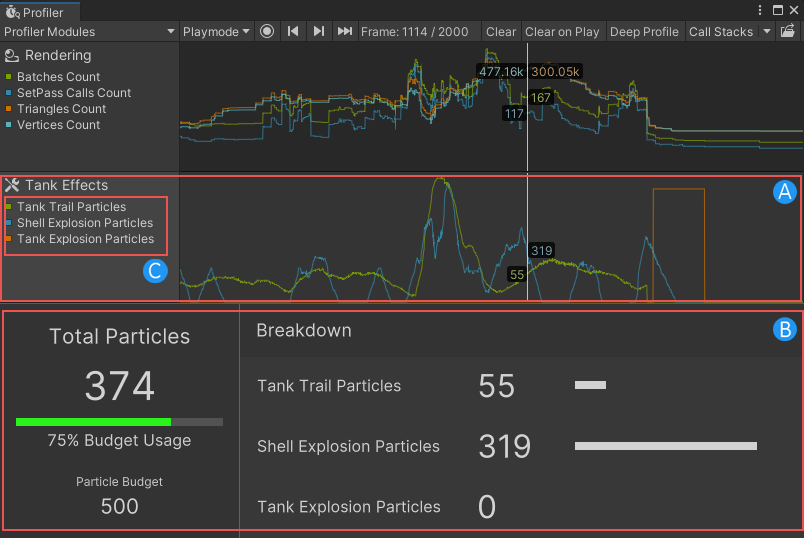
核心概念
自定义模块中主要有三个概念:记录(Recorder)、标记(Marker)和计数器(Counter)。
- 记录(Recorder), 记录(Recorder)是用于记录标记(Marker)或计数器(Counter)产生的测量数据。
- 标记(Marker), 在需要捕获性能的代码块中创建Marker,可以捕获代码块的执行时间,可以在Profiler的CPU模块中查看器性能参数。
- 计数器(Counter), 计数的主要用于统计每帧中次数,比如:对象创建的数量,执行的操作次数等。
API接口
Unity性能分析API, 主要分为两个部分: - Native API, Native API在Unity.Profiling包中,是对C++API的直接封装。核心类是ProfilerUnsafeUtility,通过它可以直接创建标记(Marker)和计数器(Counter),返回的是一个对象的指针IntPtr。 - C# API, C#的API是对Native API的再次封装,方便使用,主要有两个:一个在UnityEngine.Profiling包中,另一个是个外部包Unity Profiling Core。
记录(Recorder)
- ProfilerRecorderHandle, 记录(Recorder)的句柄,通过此类的ProfilerRecorderHandle.GetAvailable可以获取所有可用的记录句柄,并且可以通过ProfilerRecorderHandle.GetDescription函数获取所有句柄的描述信息。
- ProfilerRecorder, 记录的原始数据,可以通过此类获取自定义标记(Marker)和计数器(Counter)的采样数据。
- ProfilerRecorderSample, 记录里存储的值。
- Recorder,和ProfilerRecorder一样,感觉是为了兼容以前的接口而保留的类。
标记(Marker)
- ProfilerMarker, 是封装了对标记(Marker)相关的操作,ProfilerMarker内部直接调用ProfilerUnsafeUtility.CreateMarker创建标记(Marker),并管理返回的指针IntPtr。
- ProfilerMarker<T...>, 是由外部包Unity Profiling Core提供,与Unity内部的ProfilerMarker区别是可以在采用的时记录Meta数据,模板T就是记录的数据类型,内部也是对ProfilerUnsafeUtility的直接调用。
- CustomSampler, 和ProfilerMarker一样,功能几乎一样,感觉是为了兼容以前的接口而保留的类。
计数器(Counter)
- ProfilerCounter, 是一个计数器类,它将计数值,直接通过Marker的Meta数据存储
- ProfilerCounterValue, 此类也是一个计数器,它的不同之处在于,不依赖Marker,直接通过ProfilerUnsafeUtility.CreateCounterValue创建,并记录了数据的地址,内部直接使用*m_Value = value, m_Value是ProfilerUnsafeUtility.CreateCounterValue返回的地址。但是本质上还是存在Marker的Meta数据中。
其他类
- Profiler,此类设计的目标是表示Profiler本身的,虽然,现在基本上都用上面讨论的这些类来记录性能数据,但是此类里面记录了一些内存统计信息,可以方便我们在任何使用访问,因为Unity内部管理的着这些内存所有本身不存在统计开销。不要使用这里面的BeginSample和EndSample等,开销比上述的內开销大。也可以通过此类将性能分析器的数据以日志的方式输出到指定文件中。输出的问题可以直接通过Unity的Profiler工具打开查看和直接捕获的数据一致。
创建Marker和Counter
1 |
|
获取记录(Recorder)数据
1 | public class TestCode : MonoBehaviour |
创建自定Profiler模块
主要有两个部分组成: 1. Profiler模块 2. 模块详细界面
Profiler模块,代码如下:
1 | using Unity.Profiling; |
模块详细界面,代码如下:
1 | using Unity.Profiling.Editor; |
Native代码的支持
Native接口可以让C/C++代码调用Profiler的接口,以及在C/C++中接受Profiler发送的事件,实例代码入下:
1 |
|
Lua Profiler
Lua Profiler是一个开源的Lua性能分析工具,提供了CPU和内存情况的统计和分析。
LuaProfiler捕获性能数据的基本原理是在Lua函数中插入采样代码,通过Hook技术截获luaL_loadbuffer函数,在加载出来的lua代码中调用InsertSample函数插入采样代码,核心代码:
1 | public static readonly string LOCAL_PROFILER = |
上面的操作对于使用者来说时透明的,在开始记录数据时,正常运行游戏就可以在函数中插入采用代码了。有时我们也需要查看某个函数中特定部分代码的性能数据,可以通过如下代码插入自定义的采样:
1 | local LuaProfiler = MikuLuaProfiler.LuaProfiler |
Snapdragon Profiler
Snapdragon Profiler是高通官方开发的性能分析工具,它可以帮助我们分析CPU, GPU, DSP, 内存, 电量, 热量和网络数据,以便我们可以查找并修复性能瓶颈。Snapdragon Profiler主要有四种数据捕获模式:
- 实时(Realtime), 实时视图可以轻松地在时间线上关联系统资源使用情况。提供了22个类别的150多种不同的硬件性能计数器。
- 踪迹捕获(Trace Capture), 跟踪捕获模式允许您在时间线上可视化内核和系统事件,以分析 CPU、GPU 和 DSP 中的低级系统事件。查看 CPU 调度和 GPU 阶段数据,以了解您的应用程序将时间花在何处。
- 快照捕捉(Snapshot Capture), 快照捕获模式允许您从OpenGL ES或Vulkan应用程序捕获和调试渲染的帧。可以查看和编辑shader并实时在设备上预览,查看和调试像素历史记录。如果不能看到Shader,需要清理一下App的缓存,下载资源不用清
- 采样捕获(Sampling Capture), 采样捕获模式允许您记录应用程序的调用栈图以分析消耗的CPU时间。调用栈图以火焰图的形式可视化。此模式必须要配置NDK13及以上,在AndroidManifest.xml中android:debuggable必须为true(Root除外)
基本的操作和面板说明,可以看Snapdragon Profiler手册。
Snapdragon Profiler不仅可以用来分析性能,也可以捕捉其他游戏的帧,根据帧的绘制情况可以很容易分析出其设计,包括Shader源码都可以获取到
参数说明:
- CPU Core Load, 是指CPU每个核心的工作负载或使用情况的百分比。CPU是多核心处理器,通常一个CPU会包含多个核心,每个核心可以独立执行指令和处理任务。CPU Core Load代表了每个核心在特定时间内执行工作的强度。
- CPU Core Frequency, CPU Core Frequency(CPU 核心频率)是指CPU每个核心在每秒钟内执行指令的速度,通常以GHz(千兆赫兹)或 MHz(兆赫兹)为单位。核心频率越高,处理指令的速度就越快。
- CPU Core Utilization, CPU Core Utilization(CPU 核心利用率)是指每个CPU核心在特定时间段内被实际使用的百分比,表示该核心的繁忙程度。它反映了系统的任务在某个核心上执行的效率,以及该核心处理资源的利用率。与“Core Load”相比“Core Load”更侧重于当前任务对核心的实际占用,而“Utilization”一般指的是一段时间内的平均使用率。
- GPU Bus Busy, GPU Bus Busy 是指 GPU(图形处理单元)与其他组件(如 CPU 和内存)之间的数据总线的繁忙程度,通常以百分比表示。这一指标反映了 GPU 数据总线在特定时间内用于数据传输的活跃程度。
- Avg bytes/Fragment(平均每个片段的字节数), 是一个性能指标,用于衡量在图形渲染等上下文中,传输的每个数据片段的平均字节大小。
- Avg Bytes/Vertex(每个顶点的平均字节数), 是GPU内存统计中的一个重要指标,用于衡量在图形渲染过程中,每个顶点的数据大小。这一指标通常应用于3D图形处理,特别是在处理顶点缓冲区时。
- Avg Frame Time(平均帧时间), 表示在特定时间段内,生成和显示一帧图像所需的平均时间,通常以毫秒(ms)为单位表示。
- Clocks/Second(每秒钟时钟周期数), 是一个用于描述GPU性能的重要指标。它表示GPU在一秒钟内可以执行的时钟周期数,通常以赫兹(Hz)为单位表示。
- Read Total (Bytes/sec), 用于衡量 GPU 从内存中读取数据的总速率,单位为字节每秒(Bytes/sec)。这个指标可以帮助评估 GPU 的内存带宽和性能。
- SP Memory Read (Bytes/Second), 是一个专门用于衡量GPU中的 Shader Processor(着色器处理器)从内存中读取数据的速率的性能指标,单位为字节每秒(Bytes/sec)。这个指标反映了着色器在处理图形和计算任务时,从内存获取数据的效率。
- Texture Memory Read BW (Bytes/Second), 是一个用于衡量GPU从纹理内存 中读取数据的带宽的性能指标,单位为字节每秒(Bytes/sec)。这个指标专门关注 GPU 在图形渲染过程中访问纹理数据的效率。
- Vertex Memory Read (Bytes/Second), 是一个用于衡量 GPU 从 顶点内存 中读取数据的速率的性能指标,单位为字节每秒(Bytes/sec)。这个指标专注于 GPU 在处理图形渲染时访问顶点数据的效率。
- Write Total (Bytes/sec), 是一个用于衡量 GPU 向内存写入数据的总速率的性能指标,单位为字节每秒(Bytes/sec)。这个指标反映了 GPU 在处理图形渲染或计算任务时,将数据写入内存的效率。这包括所有写入操作,比如更新纹理、缓冲区和其他资源。
- Avg Preemption Delay(平均抢占延迟), 是一个用于衡量GPU任务被抢占后,恢复执行所需平均时间的性能指标,通常以毫秒(ms)为单位表示。这一指标对于理解 GPU 的抢占机制和性能表现至关重要。
- Preemption/Second, 是一个用于衡量 GPU 每秒发生的抢占事件数量的性能指标。这一指标有助于评估 GPU 任务调度的频率和效率。
- Prims Clipped, 是一个用于衡量 GPU 在图形渲染过程中被裁剪的图元(Primitives)数量的性能指标。图元通常指的是基本的几何体,如点、线和三角形。
- Prims Trivially Rejected, 是一个用于衡量 GPU 在图形渲染过程中被简单拒绝的图元(Primitives)数量的性能指标。这些图元在被处理之前就被识别为不需要进一步处理。简单拒绝指的是 GPU 在早期阶段判断某些图元(例如点、线、三角形)在渲染过程中不影响最终图像,因而直接拒绝这些图元,而无需进行更复杂的计算。这种拒绝通常基于图元的边界框与视口的关系。
- Average Polygon Area,(平均多边形面积)是一个用于衡量渲染过程中所处理的多边形的平均面积的性能指标。该指标通常以像素为单位,反映了在图形渲染中,GPU 处理的多边形的大小和复杂性。
- Average Vertices/Polygon(平均每个多边形的顶点数), 是一个用于衡量在图形渲染过程中,每个多边形(通常是三角形或其他类型的多边形)平均包含的顶点数量的性能指标。这个指标有助于理解场景的几何复杂性和GPU处理的效率。
- Pre-clipped Polygon/Second, 是一个用于衡量 GPU 在图形渲染过程中每秒处理的预裁剪多边形(Polygons)的数量的性能指标。该指标主要反映了 GPU 在进行图元处理前,经过初步裁剪的多边形数量,通常用于评估 GPU 的处理能力和渲染效率。预裁剪是指在多边形进入完整的渲染管线之前,GPU 对其进行初步的裁剪。这通常基于多边形与视口(viewport)或其他裁剪区域的关系,以确定哪些多边形是可见的,哪些是可以被丢弃的。
- Reused Vertices/Second,是一个用于衡量 GPU 在图形渲染过程中每秒重新使用的顶点(Vertices)数量的性能指标。该指标反映了 GPU 在处理图元(如三角形、线段等)时,能够重复利用已存在顶点的效率。
- Anisotropic Filtered,是一个用于衡量在图形渲染过程中,应用各向异性过滤的纹理像素(Texels)数量的性能指标。该指标通常用于评估 GPU 在处理纹理时的效果,尤其是在处理倾斜表面时的图像质量。
- Non-Base Level Textures, 是一个用于衡量在图形渲染过程中,使用的非基础级别(非一层)纹理数量的性能指标。这个指标主要反映了 GPU 在处理纹理时,涉及的不同层级的纹理数据。
- Shader ALU Capacity Utilized, 是一个用于衡量 GPU 在图形渲染过程中,着色器算术逻辑单元(ALU)的利用率的性能指标。这个指标反映了 GPU 在执行着色器程序时,算术逻辑单元的实际使用情况与其最大处理能力之间的比率。
- Shader Busy, 是一个用于衡量 GPU 在图形渲染过程中,着色器处于忙碌状态的时间占总时间的比例的性能指标。这个指标反映了 GPU 着色器执行任务的效率和资源利用情况。
- Shader Stalled, 是一个用于衡量 GPU 着色器在执行过程中因各种原因而处于等待或阻塞状态的时间比例的性能指标。这个指标反映了 GPU 着色器执行效率的下降及其可能受到的限制。
- Texture Pipes Busy, Texture Pipes Busy 是一个用于衡量 GPU 纹理处理管道(Texture Pipes)在图形渲染过程中忙碌状态的时间占总时间比例的性能指标。这个指标反映了 GPU 在处理纹理采样和纹理过滤操作时的效率和利用情况。
- Time ALUs Working, 是一个用于衡量 GPU 着色器中的算术逻辑单元(ALUs)实际执行计算任务的时间的性能指标。该指标反映了 GPU 在图形渲染过程中 ALU 的利用效率。
- Time Compute, 是一个用于衡量 GPU 在图形渲染过程中用于计算操作的总时间的性能指标。这个指标反映了 GPU 执行着色器计算任务的时间开销,尤其是在处理复杂的计算着色器(Compute Shaders)时。
- Time EFUs Working, 是一个用于衡量 GPU 中的执行功能单元(Execution Functional Units, EFUs)实际用于执行计算任务的时间的性能指标。该指标反映了 GPU 在处理着色器程序时,EFUs 的利用效率。EFUs 是 GPU 中专门用于执行各种类型运算的单元,包括整数运算、浮点运算和其他特定功能的计算。EFUs 可以被视为 ALUs 的更广泛类别,负责处理着色器中的各种计算任务。
- Time Shading Fragments, 是一个用于衡量 GPU 在处理和渲染片段(Fragment)时所花费的总时间的性能指标。这个指标主要反映了 GPU 在片段着色阶段的计算效率和性能。
- Time Shading Vertices, 是一个用于衡量 GPU 在处理和渲染顶点(Vertex)时所花费的总时间的性能指标。这个指标主要反映了 GPU 在顶点着色阶段的计算效率和性能。
- Wave Context Occupancy, 是一个用于衡量 GPU 在执行着色器程序时,波前(Wavefront 或 Warp)上下文占用的效率指标。该指标反映了 GPU 在处理并发执行的着色器线程时,资源的利用情况和计算效率。
- 波前(Wavefront/Warp):在现代 GPU 中,计算通常是以波前或 Warp 的形式进行的。一个波前包含多个线程(通常是 32 个或 64 个),这些线程同时执行相同的指令,但可以在不同的数据上操作。波前的并行处理能够提高计算效率。
- 上下文占用:Wave Context Occupancy 指的是在某一时间段内,实际活动的波前线程数量与理论上可以支持的最大线程数量的比率。这个值通常以百分比表示,反映了 GPU 在执行着色器时的并行利用程度。
- ALU/Fragment, 是一个用于衡量每个片段(Fragment)处理所需的算术逻辑单元(ALUs)操作数量的性能指标。这个指标反映了在片段着色阶段中计算的复杂性和资源的利用程度。
- Fragment ALU Instructions/Sec, 是一个用于衡量 GPU 每秒钟处理的片段着色器中的算术逻辑单元(ALU)指令数量的性能指标。这个指标反映了 GPU 在片段着色阶段的计算性能和吞吐量。
- Fragments Shaded, 是一个用于衡量 GPU 在特定时间段内处理和着色的片段(Fragment)数量的性能指标。这个指标反映了 GPU 在片段着色阶段的工作负载和效率。
- Textures/Fragment, 是一个用于衡量在片段着色过程中,每个片段所涉及的纹理样本(Texture Samples)数量的性能指标。这个指标反映了片段着色器在处理图形时对纹理的访问频率和复杂性。
- Textures/Vertex, 是一个用于衡量在顶点着色过程中,每个顶点所涉及的纹理样本(Texture Samples)数量的性能指标。这个指标反映了顶点着色器在处理图形时对纹理的访问频率和复杂性。
- Vertex Instructions/Second, 是一个用于衡量 GPU 每秒钟处理的顶点着色器中的指令数量的性能指标。这个指标反映了 GPU 在顶点处理阶段的计算性能和吞吐量。
- Vertices Shaded/Second, 是一个用于衡量 GPU 每秒钟处理和着色的顶点(Vertices)数量的性能指标。这个指标反映了 GPU 在顶点着色阶段的工作负载和效率。
- Instruction Cache Miss, 是一个用于衡量 GPU 在执行指令时缓存未命中(Cache Miss)的次数的性能指标。这一指标反映了指令缓存的效率,以及对 GPU 性能的潜在影响。
- Stalled on System Memory, 是一个用于衡量 GPU 在执行过程中由于访问系统内存而导致的停顿(Stall)次数或持续时间的性能指标。这一指标反映了 GPU 访问系统内存时的延迟和瓶颈程度。
- Texture Fetch Stall, 是一个用于衡量 GPU 在进行纹理获取(Texture Fetch)时由于等待纹理数据而导致的停顿(Stall)次数或持续时间的性能指标。这一指标反映了纹理访问过程中的延迟和可能的瓶颈。
- Texture L1 Miss, 是一个用于衡量 GPU 在访问一级纹理缓存(L1 Cache)时未命中的次数的性能指标。这个指标反映了纹理访问过程中的缓存效率,以及可能对 GPU 性能造成的影响。
- Vertex Fetch Stall, 是一个用于衡量 GPU 在进行顶点获取(Vertex Fetch)时由于等待顶点数据而导致的停顿(Stall)次数或持续时间的性能指标。这一指标反映了顶点访问过程中的延迟和潜在的瓶颈。
- L1 Texture Cache Miss Per Pixel, 是一个用于衡量每个像素的 L1 纹理缓存未命中(Miss)次数。这一指标反映了在图形渲染过程中,GPU 在处理每个像素时从 L1 纹理缓存未命中的情况,进而影响渲染效率。
- Rx Bytes (TCP), 是一个用于衡量通过 TCP 协议接收的字节数的性能指标。这个指标反映了系统在一段时间内通过网络接收的 TCP 数据量。Rx: Receive(接收)
- Tx Bytes (TCP), 是一个用于衡量通过 TCP 协议发送的字节数的性能指标。这个指标反映了系统在一段时间内通过网络发送的 TCP 数据量。Tx: Transmit(发送)
Xcode Instruments
Xcode Instruments 是一个功能强大的性能分析和调试工具,广泛用于iOS和macOS应用的开发过程。它提供多种工具来帮助开发者分析应用的性能、内存占用、能源使用等。Instruments主要有以下几个模块:
- Time Profiler
- 功能:分析代码的执行时间,定位性能瓶颈。
- 主要参数:
- CPU Usage: 显示 CPU 的使用情况。
- Call Tree: 展示方法调用的层级结构。
- Self (%): 每个方法自身消耗的 CPU 时间百分比。
- Total (%): 包括调用链中所有方法消耗的总时间百分比。
- Hide System Libraries: 隐藏系统方法,仅显示用户代码。
- Sampling Interval: 设置采样间隔时间,默认值通常为 1ms。
- Allocations
- 功能:跟踪内存分配,帮助发现内存泄漏和高内存消耗。
- 主要参数:
- Persistent Bytes: 持久占用的内存字节数。
- Transient Bytes: 瞬时分配的内存字节数。
- Heap Growth: 堆内存增长趋势。
- Address: 内存分配的地址。
- Category: 内存分配的类型(如堆分配、栈分配等)。
- Leaks
- 功能:检测内存泄漏,定位泄漏的对象。
- 主要参数:
- Leaked Bytes: 泄漏的内存字节数。
- Responsible Frame: 泄漏对象的调用栈。
- Process: 泄漏发生的进程。
- Energy Log
- 功能:分析应用的能源使用情况,优化电量消耗。
- 主要参数:
- Energy Impact: 显示应用的能源影响得分(数值越高越耗电)。
- CPU Activity: 处理器活动状态。
- Network Activity: 网络使用情况。
- Disk I/O: 磁盘读写操作。
- Core Animation
- 功能:分析界面渲染性能,优化动画效果。
- 主要参数:
- FPS (Frames Per Second): 显示当前帧率,理想值为 60 FPS。
- Animation Jank: 记录动画的卡顿次数。
- Render Server: 图形渲染服务的资源消耗。
- System Trace
- 功能:全系统级别的性能分析,包括 CPU、GPU、内存和线程的使用情况。
- 主要参数:
- Thread State: 每个线程的状态(如运行中、等待中)。
- CPU Load: 显示每个核的负载情况。
- System Calls: 系统调用的次数和耗时。
- Network
- 功能:分析网络请求和响应,优化网络使用。
- 主要参数:
- Request Duration: 网络请求的持续时间。
- Response Size: 响应的数据大小。
- Domain: 请求的域名。
- Protocol: 网络协议(如 HTTP、HTTPS)。
- Disk I/O
- 功能:分析磁盘读写性能,定位高频读写操作。
- 主要参数:
- Read/Write Operations: 读写操作的数量。
- Bytes Read/Written: 读写的数据字节数。
- File Path: 文件路径。
- Threads
- 功能:分析线程的活动,优化多线程使用。
- 主要参数:
- Active Threads: 活跃线程的数量。
- Blocked Threads: 阻塞线程的数量。
- Thread Name: 线程的名称。
- Context Switches: 线程上下文切换的次数。
- Metal System Trace
- 功能
- 分析 Metal API 的调用链及执行效率。
- 监控 GPU 和 CPU 在渲染管道中的任务分配。
- 优化命令缓冲区(Command Buffer)及绘制调用(Draw Calls)。
- 主要参数
- Command Buffers
- 显示每个命令缓冲区的执行时间和内容。
- Start/End Time:缓冲区的执行起止时间。
- Execution Time:缓冲区执行所用的时间。
- Command Encoder:命令编码器的类型(如渲染、计算、拷贝)。
- GPU Activity
- Active Time:GPU 执行命令的活跃时间。
- Idle Time:GPU 空闲时间,用于识别是否存在 GPU 瓶颈。
- Draw Calls
- 每帧的绘制调用次数。
- 绘制调用越多,GPU 处理负担越重,需尽量减少。
- Shader Execution
- Vertex Shader Time:顶点着色器的执行时间。
- Fragment Shader Time:片段着色器的执行时间。
- Compute Shader Time:计算着色器的执行时间。
- Resource Usage
- Texture Bindings:绑定到渲染管道的纹理数量。
- Buffer Uploads:上传到 GPU 的缓冲区大小。
- Heap Allocation:Metal 堆内存分配情况。
- 优化建议
- 合并绘制调用(Batching),减少 Draw Calls 的次数。
- 使用压缩纹理格式(如 ASTC)优化 GPU 内存和带宽。
- 优化着色器代码,避免复杂的动态分支(如 if 和 for)。
- 减少命令缓冲区的频繁切换。
- GPU Driver
- 功能
- 分析 GPU 渲染任务的耗时。
- 检测 Metal 应用的 GPU 瓶颈,如高频的纹理切换或缓冲区更新。
- 识别帧延迟(Frame Latency)问题。
- 主要参数
- Frame Latency
- 每一帧从命令提交到 GPU 渲染完成的延迟时间。
- 较高的延迟可能表示资源竞争或命令缓冲区堵塞。
- GPU Load
- GPU 的利用率,用于识别是否存在过载。
- 如果 GPU 长时间负载接近 100%,需优化渲染任务。
- Fragment Processing Time
- 片段着色器的处理时间,用于分析像素级渲染任务。
- Vertex Processing Time
- 顶点着色器的处理时间,通常用于分析模型的复杂性。
- Resource Binding
- Texture Binding Count:绑定的纹理数量。
- Buffer Binding Count:绑定的缓冲区数量。
- 优化建议
- 控制纹理和缓冲区的动态切换频率,尽量复用资源。
- 减少复杂的几何数据,优化顶点和索引缓冲区。
- 提前上传资源到 GPU,减少渲染时的内存访问延迟。
- OpenGL ES Analyzer
- 功能:
- 捕获 OpenGL API 调用并分析调用性能。
- 检测渲染管道中的瓶颈。
- 主要参数:
- Draw Calls: 渲染调用的次数。
- Shader Compilation Time: 着色器编译的耗时。
- State Changes: OpenGL 状态切换的次数。
- Framebuffer Switches: 帧缓冲区切换的次数。
参考
- 电脑110
- 华硕B760主板说明书
- 主板北桥芯片为何消失了?南桥消失了也不奇怪
- 【从零开始:现代PC】第三章:主板
- 浅谈智能手机硬件原理与常识一:性能篇
- 手机硬件科普
- 10分钟掌握手机配置知识(纯干货)
- 小米14 Pro拆解
- 掌中核心——手机SOC基础知识科普
- Snapdragon 8 Gen 3 Mobile Platform
- 如何看待ARM将要求使用ARM CPU后必须绑捆使用其它ARM产品(GPU、NPU、ISP等)?
- 人们常说的ARM究竟是什么意思?
- 手机Gpu参数和架构 手机gpu型号排名
- 嵌入式 NPU 发展概况
- 手机主流存储器件的分析与发展
- 了解如何使用 Unity 和 Arm 分析工具解决移动端游戏性能问题
- 【技术精讲】游戏CPU性能分析及工具
- Mobile App Performance Testing: Tools and Checklist
- Armv8/armv9架构入门指南
- ARM Compiler armasm User Guide
- Arm GPU Best Practices Developer Guide
- ARM UAL Guide
- ARM Assembly Language Tools
- RASPBERRY PI ASSEMBLER
- System V Application Binary Interface - DRAFT - 24 April 2001
- NDK 使用入门
- Getting Started with the LLVM System
- 详解三大编译器:gcc、llvm 和 clang
- 人人都应该知道的CPU缓存运行效率
- ARM 版的Clang的使用
- Linux 内核源码
- 计算机那些事(4)——ELF文件结构
- Unity Manual - Analysis