要在屏幕上绘制几何体时,Unity会调用底层的图形API的Draw命令进行绘制。一个Draw命令高数图形API绘制什么以及如何绘制。每个Draw命令都包含图形API所需的所有信息,其中包括texture,shader和buffers数据。绘图调用可能是资源密集型的,但绘图调用的准备工作通常比绘图调用本身更耗费资源。
准备绘制调用时,CPU去构建资源并通过图形API改变GPU的内部设置。这些设置统称为渲染状态。改变这些渲染状态通常时资源密集型的操作,比如切换不同的材质时。 因为渲染状态的改变是资源密集型的,所有减少渲染状态改变的次数是主要的优化方法,这有两种方法能到达此目的:
- 减少总的绘制调用
- 有效组织绘制调用,以减少渲染状态的切换。
优化绘制调用和渲染状态改变数量,主要减少每帧的时间,它也能:
- 减少应用程序的电池的消耗。
- 提高应用程序未来开发的可维护性。当你更早的优化绘制调用和渲染状态改变,那么它将长期维持在一个相对优化的级别。
Unity提供了如下几种优化绘制调用和渲染状态的方法,一些方法只适用于特定的场景。
- Static Batching : 静态合并Mesh来减少绘制调用和渲染状态的改变。需要将对象标记为static。Unity将组合数据发送到GPU,但单独渲染组合中的每个网格。Unity仍然可以单独剔除网格,但每次绘制调用占用的资源较少,因为数据状态永远不会改变。(减少DrawCall)
- Dynamic Batching : 在CPU动态上转换网格顶点,将相同配置的顶点分组,并在一次绘制调用中渲染它们。 比如顶点存储相同数量和类型的属性,则它们共享相同的配置。例如,位置和法线。 (减少DrawCall)
- Manually combining meshes : 通过调用Mesh.CombineMeshes函数将多个Mesh合并为一个。 (减少DrawCall)
- GPU Instancing : 渲染相同的mesh多次。GPU 实例化对于绘制在场景中多次出现的几何图形非常有用,例如树木或灌木丛。(减少DrawCall)
- SRP Batcher : 在SRP项目中,可以使用SRP Batcher减少相同着色器变体的材质准备和绘制调用所需的CPU时间。 (不减少DrawCall,减少状态改变次数)
您可以在同一场景中使用多个绘制调用优化方法,但请注意,Unity会按特定顺序对绘制调用优化方法进行优先排序。如果您将一个游戏对象标记为使用多种绘制调用优化方法,Unity将使用优先级最高的方法。唯一的例外是SRP Batcher。当您使用SRP Batcher时,Unity还支持对与SRP Batcher兼容的游戏对象进行静态批处理。 Unity 按以下顺序对绘制调用优化进行优先排序:
- SRP Batcher and Static batching
- GPU Instancing
- Dynamic Batching
如果您将GameObject标记为静态批处理并且Unity成功对其进行了批处理,Unity会禁用该GameObject的GPU实例化,即使渲染器使用实例化着色器也是如此。发生这种情况时,Inspector 窗口显示一条警告消息,建议您禁用静态批处理。 同样,如果Unity可以对网格使用GPU实例化,Unity会禁用该网格的动态批处理。
合并Mesh减少DrawCall
将多个Mesh合并成一个提交给GPU,以减少DrawCall的调用,Unity提供了三种方式:Static Batching(静态批处理),Dynamic Batching(动态批处理)和Manually combining meshes(手动合并Mesh)API。与手动合并Mesh相比,Unity的内置绘图调用批处理有几个优点; 最值得注意的是,Unity仍然可以单独剔除网格。 但是,它也有一些缺点; 静态批处理会产生内存和存储开销,而动态批处理会产生一些CPU开销。
在内置渲染管线中,您可以使用MaterialPropertyBlock更改材质属性,不会中断绘制调用批处理。CPU仍需要进行一些渲染状态更改,但使用MaterialPropertyBlock比使用多种材质更快。如果您的项目使用SRP,请不要使用,MaterialPropertyBlock因为它们删除了材质的SRP Batcher兼容性。
透明着色器通常需要Unity以从后到前的顺序渲染网格。为了批量处理透明网格,Unity首先将它们从后向前排序,然后尝试对它们进行批量处理。由于Unity必须从后到前渲染网格,因此它通常无法批量处理与不透明网格一样多的透明网格。
Unity无法将动态批处理应用于包含镜像的游戏对象. 例如,如果一个GameObject的Scale为1而另一个GameObject的Scale为–1,Unity无法将它们批处理在一起。
如果您不能使用绘图调用批处理,手动组合彼此靠近的网格可能是一个不错的选择。
警告:当您从C#脚本访问共享材质属性时,请确保使用Renderer.sharedMaterial而不是Renderer.material。Renderer.material创建材质的副本并将副本分配回渲染器。这会阻止Unity为该渲染器批处理绘制调用。
Static Batching
静态批处理是将不移动对象的Mesh合并以达到减少DrawCall的目的,它将合并的Mesh转换为世界空间,并为它们构建一个共享的顶点和索引缓冲区。 然后,对于可见网格,Unity执行一系列简单的绘制调用,每个调用之间几乎没有状态变化。 静态批处理不会减少绘制调用的次数(实测是能减少绘制调用的,这取决于摄像机观察到的对象顶点,在共享的顶点缓冲区中是否连续),而是减少它们之间渲染状态更改的次数。
不连续时的DrawCall情况
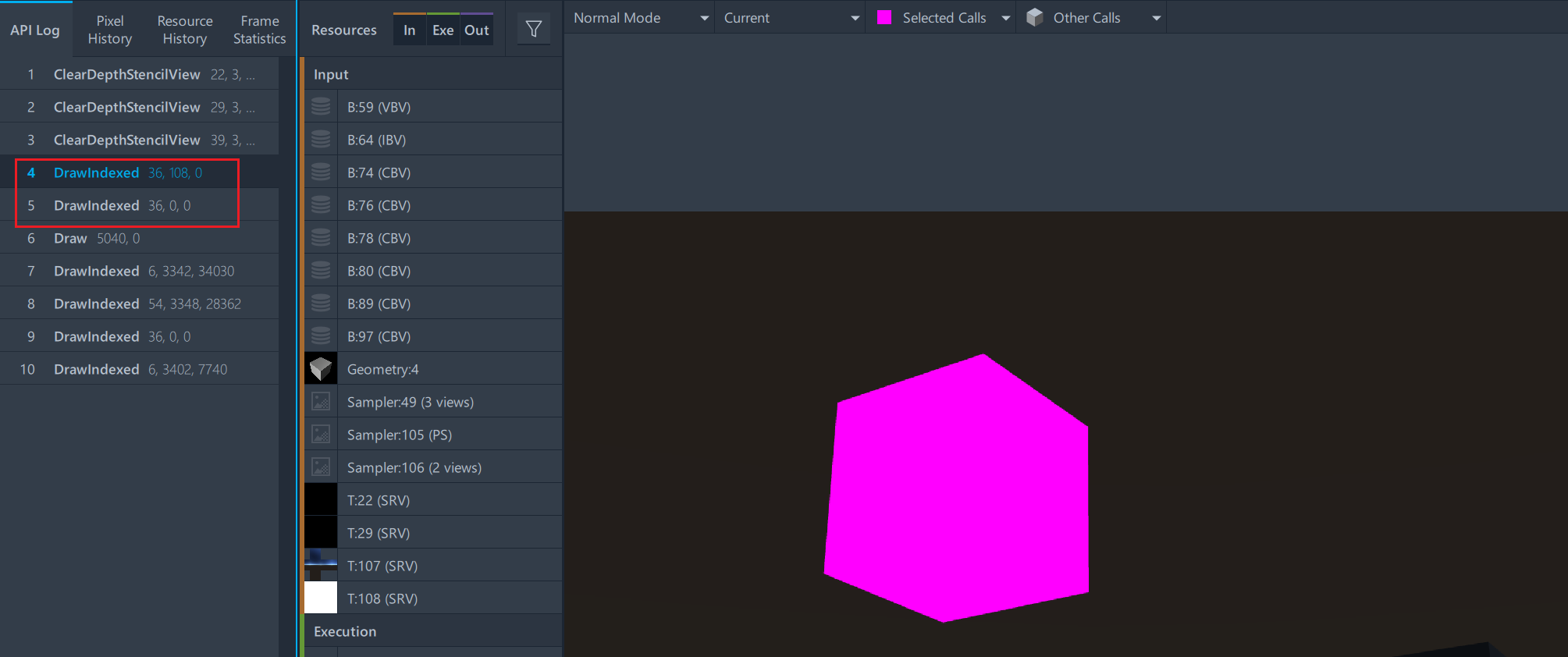
从上图中,可以看出在顶点不连续的情况下是通过两个DrawCall来绘制的,第一个从Index 108开是绘制了一个Cube,第二个从0开始绘制了一个Cube。
连续时的DrawCall情况
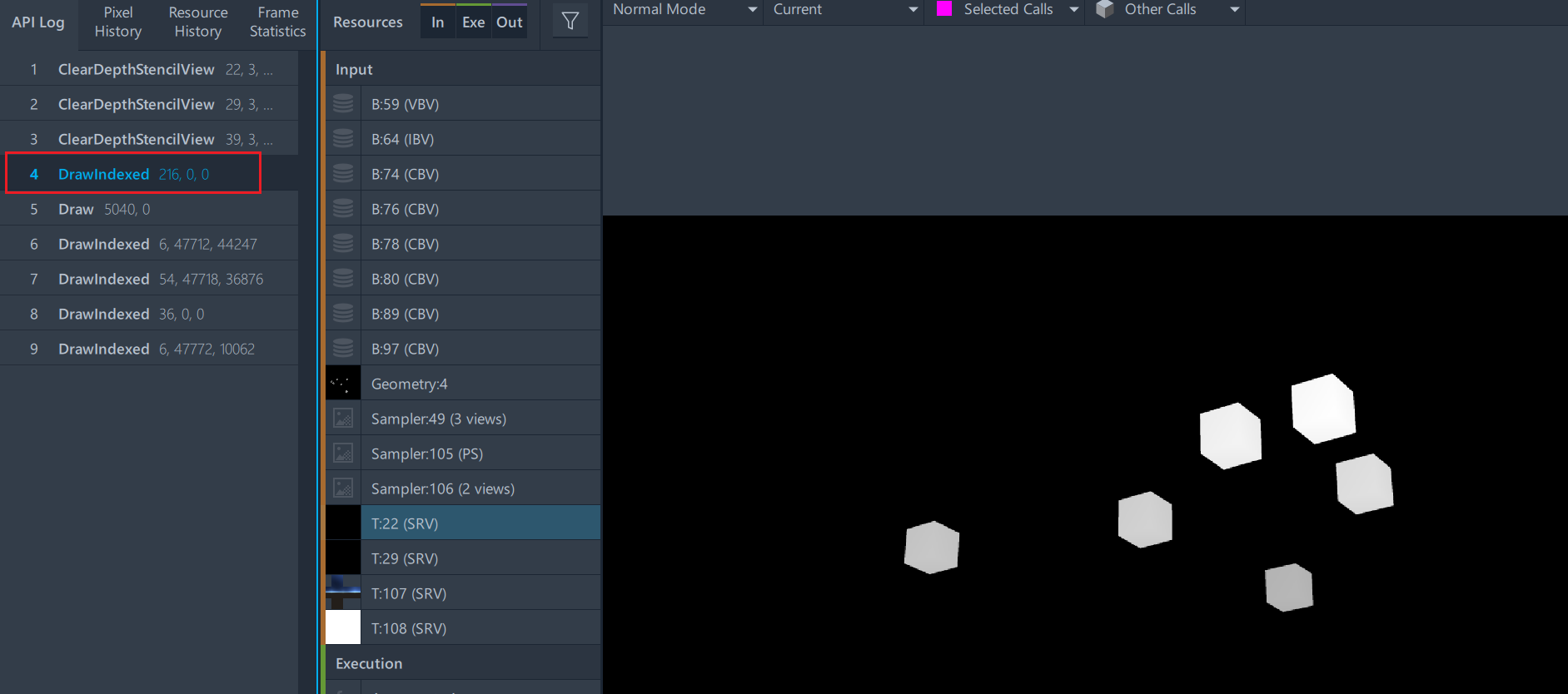
从上图中,可以看出在顶点连续的情况下只需要一个DrawCall就可以把所有的Cube绘制完成。
如何使用静态批处理
Unity可以在构建时和运行时执行静态批处理。 作为一般规则,如果游戏对象存在于场景中在构建应用程序之前,使用编辑器在构建时批处理游戏对象。 如果您在运行时创建游戏对象及其网格,则需要使用用运行时API。使用运行时 API时,您可以更改静态批处理根的对象的Transform属性。 这意味着您可以移动、旋转或缩放构成静态批次的整个网格组合。 您不能更改单个网格的Transform属性。 要对一组游戏对象使用静态批处理,游戏对象必须符合静态批处理的条件。 除了常见使用信息中描述的标准外,请确保:
- 游戏对象处于活动状态。
- GameObject 有一个 Mesh Filter组件,并且该组件已启用。
- Mesh Filter 组件引用了 Mesh。
- 网格已启用读/写。
- 网格的顶点数大于 0。
- 该网格尚未与另一个网格组合。
- 游戏对象有一个MeshRender组件,并且该组件已启用。
- MeshRenderer组件不使用带有DisableBatching标记设置为true的着色器材质
- 要一起批处理的网格必须使用相同的顶点属性。 例如,可以将使用顶点位置、顶点法线和一个UV的网格相互批处理,但不能与使用顶点位置、顶点法线、UV0、UV1和顶点切线的网格进行批处理。
在构建时使用静态批处理,需要在Edit > Project Settings > Player->Other Settings中启用Static Batching, 并在场景中,将需要批处理的对象勾上Batching Static。 在运行时,可以使用StaticBatchingUtility.Combine函数进行静态批处理,跟直接使用建模工具合并不同,静态批处理的对象能够执行单独的相机剔除。
注意: - 使用静态批处理需要额外的CPU内存来存储组合的几何图形。 如果多个游戏对象使用相同的网格,Unity会为每个游戏对象创建一个网格副本,并将每个副本插入到组合网格中。这意味着相同的几何体多次出现在组合网格中。无论您是使用编辑器还是运行时API为静态批处理准备游戏对象,Unity都会这样做。如果您想保持较小的内存占用,您可能不得不牺牲渲染性能并避免对某些游戏对象进行静态批处理。 例如,在茂密的森林环境中将树标记为静态会对内存产生严重影响。 - 静态批次可以包含的顶点数量是有限制的。每个静态批次最多可包含64000个顶点。 如果有更多,Unity会创建另一个批次。
Dynamic Batching
动态批处理是一种绘制调用批处理方法,可对移动的GameObjects进行批处理减少绘制调用。Unity在运行时动态生成的网格和几何体之间的工作方式不同,例如粒子系统。 动态批处理网格和动态几何之体间的内部差异如下:
动态批处理网格
网格的动态批处理通过将所有顶点转换为世界空间来工作。在CPU上,而不是在GPU上。这意味着动态批处理只是一种优化,前提是转换工作比绘制调用占用更少的资源。绘制调用的资源需求取决于许多因素,主要是图形API。 例如,在控制台或Apple Metal等现代API上,绘制调用开销通常要低得多,而且动态批处理通常不会产生性能提升。要确定在您的应用程序中使用动态批处理是否有益,需要分析使用和不使用动态批处理的应用程序。Unity可以对阴影投射者使用动态批处理,即使它们的材质不同,只要Unity需要的阴影传递的材质值相同即可。 例如,多个板条箱可以使用具有不同纹理的材质。 尽管材质资产不同,但这些差异与阴影投射Pass无关,Unity可以在阴影渲染步骤为GameObjects批处理阴影。
动态批处理的一些限制:
- Unity无法将动态批处理应用于包含超过900个顶点属性和225个顶点的网格。 这是因为网格的动态批处理具有每个顶点的开销。例如,如果您的着色器使用顶点位置、顶点法线和单个UV,那么Unity最多可以批处理225个顶点。但是,如果您的着色器使用顶点位置、顶点法线、UV0、UV1 和顶点切线,那么Unity只能批处理180个顶点。(说明:在Unity2021.3.6f中限制实际要大很多,内建管线:三个属性的情况4000多个顶点为一个批次,URP中三个属性的情况7000多个顶点为一个批次)
- 如果GameObjects使用不同的材质实例,Unity无法将它们批处理在一起,即使它们本质上相同。唯一的例外是阴影投射渲染。
- 具有光照贴图的游戏对象具有额外的渲染器参数。这意味着,如果您想批量处理光照贴图游戏对象,它们必须指向相同的光照贴图位置。
- Unity无法将动态批处理完全应用于使用多Pass着色器的游戏对象。
动态批处理动态产生的几何体
以下渲染器动态生成几何图形,例如粒子和线条,您可以使用动态批处理对其进行优化: - Built-in Particle Systems - Line Renderers - Trail Renderers
动态生成的几何图形的动态批处理与网格的工作方式不同: 1. 对于每个渲染器,Unity将所有可动态批处理的内容构建到一个大型顶点缓冲区中。 2. 渲染器设置批次的材质状态。 3. 然后Unity将顶点缓冲区绑定到GPU。 4. 对于批处理中的每个渲染器,Unity更新顶点缓冲区中的偏移量并提交新的绘制调用。
Manually combining meshes(手动合并Mesh)
使用建模工具或其他的工具在外部进行Mesh的合并,但就不能像静态批处理一样具有单独相机剔除了,如果Mesh有一个角在屏幕内都会将全部的Mesh丢给渲染器渲染。
GPU Instancing
GPU实例化是一种绘制调用优化方法,可在一次绘制调用中使用相同的材质渲染网格的多个副本。网格的每个副本都称为一个实例。这对于绘制在场景中多次出现的事物很有用,例如,树木或灌木。GPU实例化在相同的绘制调用中渲染相同的网格。为了增加变化并减少重复的出现,每个实例都可以具有不同的属性,例如颜色或缩放。 渲染多个实例的绘制调用在Frame Debugger中显示为Draw Mesh (instanced)。GPU Intancing与SRP Batcher不兼容。
SRP Batcher优先于GPU Intancing。 如果是游戏对象与SRP Batcher兼容,则优先使用SRP批处理,而不是GPUIntancing。 如果您的项目使用SRP批处理,并且您想将GPU Intancing用于GameObject,则可以执行以下操作之一:
- 使用Graphics.DrawMeshinstance。 该API绕过了GameObject的使用,并使用指定的参数直接在屏幕上绘制网格。
- 手动删除SRP批处理兼容性。不把材质属性放在CBuffer中。
如何使用GPU实例化
Unity使用GPU实例来共享相同网格和材质的游戏对象。 实例网格和材质:
材质球的着色器必须支持GPU实例。 Unity的标准着色器和所有表面着色器都支持GPU Instancing。要向任何其他着色器中添加GPU启动支持,请参阅创建支持GPU Intancing的着色器。
网格必须来自以下来这几种方式:
- Meshrenderer组件或Graphics.Rendermesh调用。Unity将这些网格添加到列表中,然后检查以查看可以实例的网格。Unity不支持SkinnedMeshrenderers和兼容SRP Batcher的Meshrenderer的组件。
- Graphics.RenderMeshInstanced或Graphics.RenderMeshIndirect调用。 这些方法使用相同的着色器多次渲染相同的网格。 这些方法的每次调用都会触发单独的绘制调用。Unity不会合并这些调用。
GPU Instancing支持Unity的烘焙全球照明系统。 Unity标准着色器和表面着色器支持GPU Intancingb以及Unity的烘焙全球照明。 每个GPU实例都支持以下来源之一的全局照明:
- 任何数量的光照探针。
- 一张光照图。注意:一个实例可以使用光照图中的多个区域。
- 一个光照探针代理(LPPV)组件。 注意:您必须烘培包含所有实例的LPPV。
使用GPU Intancing无法有效地处理具有较少顶点的网格,因为GPU无法以完全使用GPU资源的方式分发工作。 这种处理效率低下可能对性能产生不利影响。 效率低下的阈值取决于GPU,但作为一般规则,请不要将GPU Intancing用于少于256个顶点的网格。 如果您想多次渲染具有较少顶点的网格,最好的做法是创建一个包含所有网格信息的单个缓冲区,并使用它来绘制网格。
创建支持GPU Intancing的着色器
此节包含有关如何添加GPU Instancing到自定义Unity着色器中。首先说明自定义着色器支持GPU Instancing所需的着色器的关键字(keywords),变量(variables)和函数(function)。
着色器修改
本节包含有关着色器添加的信息,这些信息与GPU实例有关。
- #pragma multi_compile_instancing 生成实例变体。这是片段和顶点着色器所需的。对于表面着色器是可选的。
- #pragma instancing_options 指定Unity用于实例的选项。 有关可用选项开关的信息,请参见#Pragma Intancing_options。
- UNITY_VERTEX_INPUT_INSTANCE_ID 在顶点着色器输入/输出结构中定义实例ID。 要使用此宏,请启用INSTANCING_ON着色器关键字。 否则,Unity无法设置实例ID。要访问实例ID,请在#IFDEF INSTANCING_ON块中使用vertexInput.instanceID。 如果您不使用此块,则变体无法编译。
- UNITY_INSTANCING_BUFFER_START(bufferName) 声明名为bufferName的每种固定常数缓冲区的开始。 将此宏与UNITY_INSTANCING_BUFFER_END一起使用,以包装您想要在每个实例中唯一的属性的声明。 使用UNITY_DEFINE_INSTANCED_PROP在缓冲区内声明属性。
- UNITY_INSTANCING_BUFFER_END(bufferName) 声明名为bufferName的每种固定常数缓冲区的结束。 将此宏与UNITY_INSTANCING_BUFFER_START一起使用,以包装您想要在每个实例中唯一的属性声明。 使用UNITY_DEFINE_INSTANCED_PROP在缓冲区内声明属性。
- UNITY_DEFINE_INSTANCED_PROP(type, propertyName) 用指定的类型和名称定义着色器属性。
- UNITY_SETUP_INSTANCE_ID(v); 允许着色器函数访问实例ID。 对于顶点着色器,开始时需要此宏。 对于碎片着色器,此添加是可选的。
- UNITY_TRANSFER_INSTANCE_ID(v, o); 将实例ID从输入结构复制到顶点着色器中的输出结构。 如果您需要在片段着色器中访问每种实体数据,请使用此宏。
- UNITY_ACCESS_INSTANCED_PROP(bufferName, propertyName) 在实例常量缓冲区中访问每个着色器属性。 Unity使用实例ID去索引实例数据数组中的数据。 bufferName必须匹配包含指定属性的常量缓冲区的名称。
当您使用多个属性时,您无需在MaterialPropertyBlock对象中填充所有这些属性。 另外,如果一个实例缺乏属性,Unity将从引用材质中的默认值。 如果材质没有该属性的默认值,则Unity将值设置为0。不要放置一个非实例属性在MaterialPropertyBlock中,因为此操纵会禁用GPU实例化。 相反的,为它们创建不同的材质。
Instancing_options 开关
#pragma instancing_options 指令能使用下列的开关:
- forcemaxcount:batchSize和maxcount:batchSize 在大多数平台上,Unity会自动计算实例化数据数组的大小。它将目标设备上的最大常量缓冲区大小除以包含所有实例属性的结构的大小。 通常,您无需担心批量大小。 但是,某些平台需要固定的数组大小。要为这些平台指定批次大小,请使用maxcount选项。 其他平台忽略此选项。 如果你想为所有平台强制一个批次大小,使用forcemaxcount。 例如,当您的项目使用DrawMeshInstanced绘制带有256个实例化对象的绘制调用时,这很有用. 这两个选项的默认值为500。
- assumeuniformscaling 指示Unity假定所有实例都具有统一的缩放(所有 X、Y 和 Z 轴的缩放相同)。
- nolodfade 使Unity不将GPU实例化应用于LOD fade值。
- nolightprobe 防止Unity将GPU实例化应用到Light Probe值及其遮挡数据。 如果您的项目不包含使用了GPU实例化和光照探针的对象,将此选项设置为ON可以提高性能。
- nolightmap 防止Unity将GPU实例化应用到光照图中值。 如果您的项目不包含同时使用GPU实例化和光照贴图的游戏对象,则将此选项设置为ON可以提高性能。
- procedural:FunctionName 生成用于Graphics.DrawMeshInstancedIndirect的附加变体。在顶点着色器阶段开始时,Unity调用冒号后指定的函数。 手动设置实例数据,请将每个实例数据在此函数中添加。 如果任何获取的实例属性包含在片段着色器中,Unity也会在片段着色器的开头调用此函数。
将实例属性添加到GPU实例化着色器
默认情况下,Unity GPU实例化在每个绘制调用中具有不同Transform信息。 要为实例添加更多变化,请修改着色器以添加每个实例的属性,例如颜色。 您可以在表面着色器和顶点/片段着色器中执行此操作。 自定义着色器不需要每个实例数据,但它们确实需要一个实例ID,因为世界矩阵需要一个实例ID才能正常运行。 表面着色器会自动设置实例ID,但自定义顶点和片段着色器不会。 要为自定义顶点和片段着色器设置ID,请在着色器的开头使用UNITY_SETUP_INSTANCE_ID。 有关如何执行此操作的示例,请参阅下方的“顶点和片段着色器”。 当您声明一个实例化属性时,Unity会将GameObjects上设置的MaterialPropertyBlock对象的所有属性值收集到单个绘制调用中。 有关如何使用MaterialPropertyBlock设置对象在运行时每个实例数据,请参阅下方的“在运行时改变每个实例数据”。
顶点和片段着色器: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68Shader "Unlit/GPUInstancing"
{
Properties
{
_MainTex ("Texture", 2D) = "white" {}
_Color ("Color", Color) = (1, 1, 1, 1)
_ExtSize ("ExtSize", float) = 0
}
SubShader
{
Tags { "RenderType"="Opaque" "RenderPipeline"="UniversalPipeline"}
Pass
{
Tags {"LightMode" = "UniversalForward"}
HLSLPROGRAM
#pragma vertex vert
#pragma fragment frag
#pragma multi_compile_instancing
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
struct Attributes
{
float4 positionOS : POSITION;
float3 normalOS : NORMAL;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
struct Varyings
{
float4 positionCS : SV_POSITION;
float2 uv : TEXCOORD0;
UNITY_VERTEX_INPUT_INSTANCE_ID
};
sampler2D _MainTex;
float4 _MainTex_ST;
UNITY_INSTANCING_BUFFER_START(Test)
UNITY_DEFINE_INSTANCED_PROP(float4, _Color)
UNITY_DEFINE_INSTANCED_PROP(float, _ExtSize)
UNITY_INSTANCING_BUFFER_END(Test)
Varyings vert (Attributes input)
{
Varyings o;
UNITY_SETUP_INSTANCE_ID(input);
UNITY_TRANSFER_INSTANCE_ID(input, o);
float3 positionOS = input.positionOS.xyz + input.normalOS * UNITY_ACCESS_INSTANCED_PROP(Test, _ExtSize);
o.positionCS = TransformObjectToHClip(positionOS);
o.uv = TRANSFORM_TEX(input.uv, _MainTex);
return o;
}
half4 frag (Varyings input) : SV_Target
{
UNITY_SETUP_INSTANCE_ID(input);
float4 col = UNITY_ACCESS_INSTANCED_PROP(Test, _Color);
float4 mainCol = tex2D(_MainTex, input.uv);
return mainCol * col;
}
ENDHLSL
}
}
}
在运行时改变每个实例数据
1 | using UnityEngine; |
SRP Batcher
可编程渲染管线(SRP) Batcher是一种绘制调用优化,可显着提高使用SRP的应用程序的性能。 SRP Batcher减少了Unity为使用相同着色器变体的材质准备和调度绘制调用所需的CPU时间。
需求和兼容性
GameObject兼容性
在任何给定的场景中, 一些游戏对象与SRP Batcher兼容,有些则不兼容。兼容的游戏对象使用SRP Batcher代码路径,不兼容的游戏对象使用标准的SRP代码路径。 有关详细信息,请参阅后续章节的“SRP Batcher的工作原理”。
GameObject必须满足以下要求才能与SRP Batcher代码路径兼容:
- GameObject必须包含网格或蒙皮网格。 它不能是一个粒子。
- GameObject不得使用 MaterialPropertyBlocks。
- GameObject使用的着色器必须与SRP Batcher兼容。 有关详细信息,请参阅后续章节的“着色器兼容性”。
着色器兼容性
高清渲染管线 (HDRP) 和通用渲染管线(URP)中的所有带光照和不带光照的着色器都符合此要求(除粒子版本)。 对于与SRP Batcher兼容的自定义着色器,它必须满足以下要求:
- 着色器必须在名为UnityPerDraw的单个常量缓冲区中声明所有内置引擎属性。 例如,unity_ObjectToWorld或unity_SHAr。
- 着色器必须在名为UnityPerMaterial的单个常量缓冲区中声明所有材质属性。
SRP Batcher的工作原理
优化绘制调用的传统方法是减少它们的数量。 相反,SRP Batcher减少了绘制调用之间的渲染状态更改。 为此,SRP Batcher结合了一系列绑定和绘制GPU命令。 每个命令序列称为一个SRP批处理。
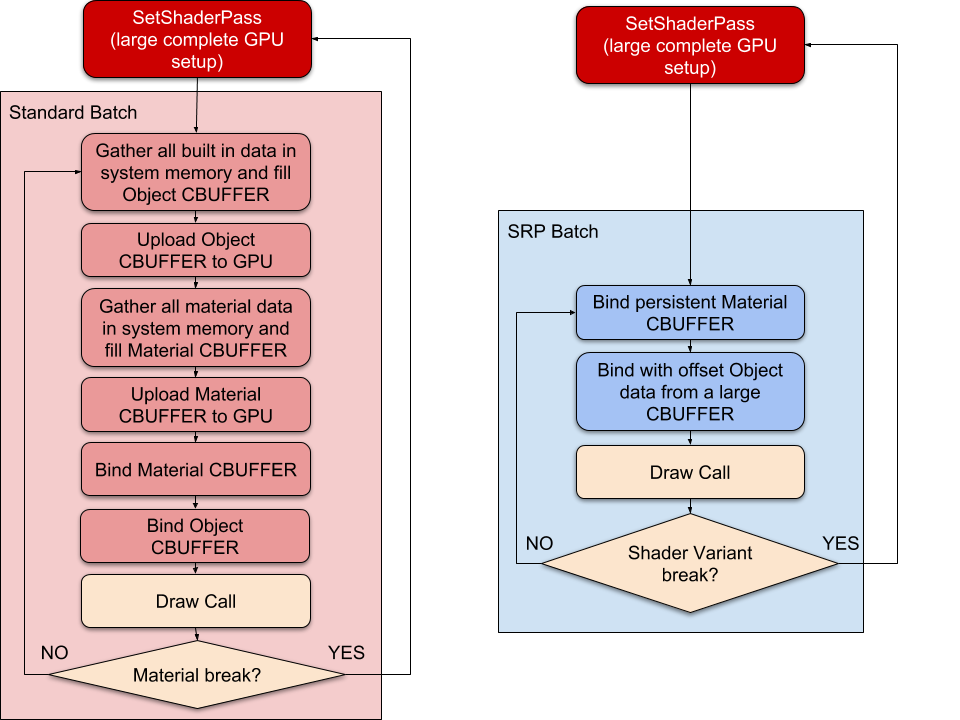
为实现渲染的最佳性能,每个SRP Batcher应包含尽可能多的绑定和绘制命令。 为此,请使用尽可能少的着色器变体。 您仍然可以根据需要使用具有相同着色器的任意多种不同材质。 当Unity在渲染循环中检测到新材质时,CPU会收集所有属性并将它们绑定到GPU的常量缓冲区中。 GPU缓冲区的数量取决于着色器如何声明其常量缓冲区。
SRP Batcher是一个底层的渲染循环,可使材质数据持久保存在GPU内存中。 如果材质内容没有改变,SRP Batcher不会改变任何渲染状态。 相反,SRP Batcher使用专用代码路径来更新大型GPU缓冲区中的Unity引擎属性,如下所示:
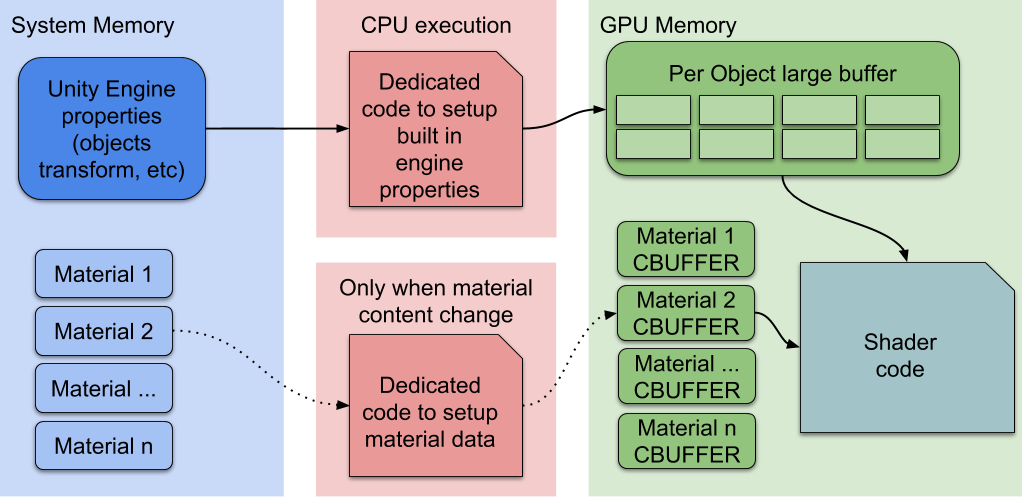
在这里,CPU只处理Unity引擎属性,在上图中标记为 Per Object large buffer。 所有材质都有位于GPU内存中的持久常量缓冲区,随时可以使用。这会加快渲染速度,因为:
- 所有材质内容现在都保存在GPU内存中。
- 专用代码为每个对象的所有属性管理一个大型的GPU常量缓冲区。
故意删除GameObjects的SRP Batcher兼容性
在极少数情况下,您可能希望故意使特定游戏对象与SRP Batcher不兼容。 例如,如果您想使用与SRP Batcher不兼容的GPU实例化。 如果您想使用完全相同的材质渲染许多相同的网格,GPU实例化可能比SRP Batcher更高效。 要使用GPU实例化,您必须:
- 使用 Graphics.DrawMeshInstanced。
- 手动删除SRP Batcher兼容性并为材质启用GPU实例化。
有两种方法可以从GameObject中删除与SRP Batcher的兼容性:
- 使着色器不兼容。
- 使渲染器不兼容。
提示:如果您使用GPU实例化而不是SRP Batcher,请使用 Profiler以确保GPU实例化对于您的应用程序比SRP Batcher更有效。
删除着色器兼容性
您可以使手写着色器和Shader Graph着色器与SRP Batcher不兼容。 但是,对于Shader Graph着色器,如果您经常更改和重新编译Shader Graph,则使渲染器不兼容会更简单。 要使Unity着色器与SRP Batcher不兼容,您需要更改着色器源文件:
- 对于自定义着色器,打开着色器源文件。 对于Shader Graph着色器,将Shader Graph的已编译着色器源代码复制到新的着色器源文件中。 在您的应用程序中使用新的着色器源文件而不是着色器图。
- 将新的材质属性声明添加到着色器的属性块中。 不要在UnityPerMaterial常量缓冲区中声明新的材质属性。
材质属性不需要做任何事情;只需要将其放在UnityPerMaterial常量缓冲区外部,则可以使着色器与SRP Batcher不兼容。
警告:如果使用 Shader Graph,请注意每次编辑和重新编译 Shader Graph 时,都必须重复此过程。
删除渲染器兼容性
可以将MaterialPropertyBlock添加到渲染器,一旦渲染器中添加了MaterialPropertyBlock则不能SRP Batcher兼容。
SRP Batcher着色器示例
1 | Shader "Unlit/SRPBatcher" |
说明:以上的测试结果是基于Unity 2021.3.6f1,每个版本的测试的结果可能会不一样。