在开始学习ShaderLab之前,我们先简单的了解一下着色器语言。着色器语言主要分为离线渲染时使用的着色器语言和实时渲染中使用的着色器语言。
离线作色器语言
- RenderMan 着色语言(RSL)
- Houdini VEX 着色语言
- Gelato 着色语言
- 开放着色器编程语言(OSL)
实时着色器语言
- ARB汇编语言(英语:ARB assembly language)
- OpenGL 着色语言(GLSL)
- Cg语言
- DirectX 着色器汇编语言
- DirectX 高级着色器语言(HLSL)
- Metal 着色语言
ShaderLab与以上的作色语言有什么区别呢?ShaderLab是Unity定义的一个Shader描述性语言,不能直接在对应图形平台运行,并且是夸平台。为了更好的理解它们的区别,先来看一下OpenGL是如何通过GLSL着色语言对一个三角形进行着色的。
OpenGL如何渲染一个三角形
首先创建一个窗口用于显示渲染对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42int main()
{
// 使用glfw初始化和配置窗口
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
// 创建窗口
GLFWwindow* window = glfwCreateWindow(SCR_WIDTH, SCR_HEIGHT, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
// 构建窗口上限文信息
glfwMakeContextCurrent(window);
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
// 使用glad库加载所有的OpenGL函数指正
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
}
// 处理所欲输入信息
// ---------------------------------------------------------------------------------------------------------
void processInput(GLFWwindow *window)
{
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}
// 窗口大小改变时执行的回调函数
// ---------------------------------------------------------------------------------------------
void framebuffer_size_callback(GLFWwindow* window, int width, int height)
{
glViewport(0, 0, width, height);
}构建用于着色的着色器程序
顶点着色器代码:
1
2
3
4
5
6
7
layout (location = 0) in vec3 aPos;
void main()
{
gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);
}片元着色器代码:
1
2
3
4
5
6
7
out vec4 FragColor;
void main()
{
FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);
}编译链接着色器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54int main()
{
// 构建和编译着色器程序
// 顶点着色器
// 创建一个顶点着色器对象
unsigned int vertexShader = glCreateShader(GL_VERTEX_SHADER);
// 将顶点着色器的类容给着色器对象
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL); // vertexShaderSource就是上面的“顶点着色器代码”中的类容,为了好看单独放上面
// 编译着色器对象
glCompileShader(vertexShader);
// 检查编译错误
int success;
char infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);
if (!success)
{
glGetShaderInfoLog(vertexShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 片元着色器
// 创建一个片元着色器对象
unsigned int fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
// 将片元着色器的类容给着色器对象
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL); //fragmentShaderSource 就是上面的“片元着色器代码”中的类容,为了好看单独放上面
// 编译片元着色器对象
glCompileShader(fragmentShader);
// 检查编译错误
glGetShaderiv(fragmentShader, GL_COMPILE_STATUS, &success);
if (!success)
{
glGetShaderInfoLog(fragmentShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::FRAGMENT::COMPILATION_FAILED\n" << infoLog << std::endl;
}
// 链接着色器程序
// 创建一个着色器程序对象
unsigned int shaderProgram = glCreateProgram();
// 将编译后的顶点着色器对象和片元着色器对象给着色器程序进行编译
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
// 开始链接着色器程序,当链接着色器至一个程序的时候,它会把每个着色器的输出链接到下个着色器的输入。当输出和输入不匹配的时候,你会得到一个连接错误。
glLinkProgram(shaderProgram);
// 检查链接错误
glGetProgramiv(shaderProgram, GL_LINK_STATUS, &success);
if (!success) {
glGetProgramInfoLog(shaderProgram, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::PROGRAM::LINKING_FAILED\n" << infoLog << std::endl;
}
// 链接完后,将顶点和片元着色器对象删除
glDeleteShader(vertexShader);
glDeleteShader(fragmentShader);
}创建三角形顶点数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31int main()
{
// 设置顶点数据并配置属性
float vertices[] = {
-0.5f, -0.5f, 0.0f, // left
0.5f, -0.5f, 0.0f, // right
0.0f, 0.5f, 0.0f // top
};
unsigned int VBO, VAO;
glGenVertexArrays(1, &VAO); // 向GPU申请一个顶点数组对象
glGenBuffers(1, &VBO); // 向GPU申请一个顶点缓冲对象
// 绑定顶点数组对象
glBindVertexArray(VAO);
// 绑定顶点缓冲对象
glBindBuffer(GL_ARRAY_BUFFER, VBO);
// 将顶点数据复制到顶点缓冲对象中
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 告知GPU顶点数据的格式,启用顶点属性,顶点属性默认是禁用的
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 解除绑定VBO对象
glBindBuffer(GL_ARRAY_BUFFER, 0);
// 解除绑定VAO对象
glBindVertexArray(0);
}使用三角形顶点数据和着色器程序绘制三角形
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23int main()
{
// 渲染循环
while (!glfwWindowShouldClose(window))
{
// 处理输入
processInput(window);
// 渲染
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
// 绘制三角形
glUseProgram(shaderProgram);
glBindVertexArray(VAO); // 由于我们只有一个 VAO,因此无需每次都绑定它,但我们会这样做以使事情更有条理
glDrawArrays(GL_TRIANGLES, 0, 3);
// glBindVertexArray(0); // 不需要每次都解绑
// 交换前后缓冲区并轮询IO事件
glfwSwapBuffers(window);
glfwPollEvents();
}
}
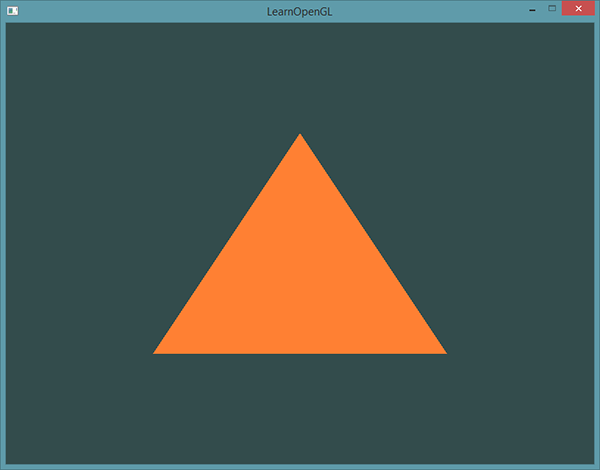
至此一个三角形就绘制出来了,为了逻辑更加清晰以上的代码在排版上做了调整,不能用于直接运行,最明显的就是每个阶段都有main函数,这主要时为了好看,完整的代码参见:LearnOpenGL网站。渲染图如下:
ShaderLab
ShaderLab中相关术语
Shader这个术语通常是令人困惑,人们通常使用shader这个词代表不同的意思。在本文中,Shader这个术语有如下:
- Shader或Shader program 指的是在GPU上运行的一段程序代码。
- Shader object 指的是一个Shader类的实例。一个Shader对象包含了Shader程序和其他信息。
- ShaderLab 指的是Unity专用的写Shader的着色器语言。
- Shader Graph 指的是一个不需要写代码就能创建Shader的工具
- Shader asset 指的是扩展名为.shader的着色器对象文件。
- Shader Graph asset 指的是由Shader Graph创建的着色器对象。
ShaderLab做了哪些事
- 定义了Shader object(着色器对象)的结构。
- 暴露了属性给材质球。
- 使用命令去设置了GPU的渲染状态。
- 使用HLSL代码块进行着色代码编写。
- 可以指定子Shader和Pass的包依赖。
- 使用Fallback定义了兜底行为。
Shader object(着色器对象)
Shader object(着色器对象)就是C#的Shader类的一个实例,Shader类主要是用来管理一个.shader着色器文件,以及Shader的一些全局设置。比如:Shader.Find, Shader.globalKeywords, Shader.PropertyToID, Shader.SetGlobalXXXX和Shader.GetGlobalXXXX等。
Shader类主要是用来管理如下的ShaderLab代码: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86// URPUnlitShaderBasic.shader
Shader "Example/URPUnlitShaderBasic"
{
// 属性块
Properties
{
// 定义了一个纹理属性, 可以通过Shader.FindPropertyIndex查找索引,让后通过索引获取属性相关的信息Shader.GetPropertyXXX
[MainTexture] _MainTex ("Texture", 2D) = "white" {}
}
// SubShader块,包含着色器代码
SubShader
{
// 定义Shader的LOD级别
LOD 100
// 定义Shader的Tag, 可以通过Shader.FindPassTagValue获取对应的值
Tags { "RenderType" = "Opaque" "RenderPipeline" = "UniversalPipeline" }
Pass
{
// HLSL代码块 SRPHLSL语言.
HLSLPROGRAM
// 指明顶点着色器是哪个函数
#pragma vertex vert
// 指明片元着色器是哪个函数
#pragma fragment frag
// 引入包含文件,Core.hlsl文件包含了一些在HLSL中频繁使用的宏和函数
#include "Packages/com.unity.render-pipelines.universal/ShaderLibrary/Core.hlsl"
// 这个结构定义了传入顶点着色器的参数
struct Attributes
{
// 顶点的对象空间位置
float4 positionOS : POSITION;
// 顶点的纹理坐标
float2 uv : TEXCOORD0;
};
// 定义了顶点着色器的输出结果
struct Varyings
{
// 定义了输出到裁剪空间中的位置
float4 positionHCS : SV_POSITION;
// 顶点的纹理坐标
float2 uv : TEXCOORD0;
};
// 这个宏定义了_MainTex是一个2D纹理对象
TEXTURE2D(_MainTex);
// 这个宏声明了_MainTex的采样器
SAMPLER(sampler_MainTex);
// 设置纹理的平铺和偏移
float4 _MainTex_ST;
// 顶点着色器函数
Varyings vert(Attributes IN)
{
// 声明一个顶点的输出数据
Varyings OUT;
// 将输入的对象空间的坐标转换到裁剪空间中
OUT.positionHCS = TransformObjectToHClip(IN.positionOS.xyz);
// 计算平铺和偏移后的纹理坐标并传递给下一个阶段
OUT.uv = TRANSFORM_TEX(IN.uv, _MainTex);
// 返回输出的结果
return OUT;
}
// 片元着色器函数
half4 frag() : SV_Target
{
// 采样纹理,并返回采样后的纹理颜色
half4 color = SAMPLE_TEXTURE2D(_MainTex, sampler_MainTex, IN.uv);
return color;
}
ENDHLSL
}
}
SubShader
{
// 子Shader,Unity在使用此着色器的时候,会激活硬件兼容的子Shader,一个着色器同时只能有一个子Shader被激活。
}
// 如果都没有兼容的子Shader,Fallback则用来保底
Fallback "ExampleOtherShader"
}
材质属性
在Shader中可以定义材质属性,这些属性存储在材质资源,并且可以持久化。
使用材质属性:
- 可以通过调用材质的函数设置材质属性(比如:Material.SetFloat等)。
- 可以在Inspector中查看和编辑材质属性。
- Unity保存这些属性在材质资源中。
不使用材质属性:
- 还是可以通过材质函数访问材质属性。
- 在Inspector中将不显示这些属性。
- 改变不能够持久化。
材质属性格式如下: 1
[optional: attribute] name("display text in Inspector", type name) = default value
"attribute"可用值参见官网:https://docs.unity3d.com/2022.2/Documentation/Manual/SL-Properties.html#material-property-attributes
内建的MaterialPropertyDrawer:https://docs.unity3d.com/2022.2/Documentation/ScriptReference/MaterialPropertyDrawer.html
"type name"可用值参见官网:https://docs.unity3d.com/2022.2/Documentation/Manual/SL-Properties.html#material-property-declaration-syntax-by-type
自定义材质编辑器:
1 | public class ExampleShaderGUI : ShaderGUI |
1 | Shader "Examples/UsesCustomEditor" |
SubShader
一个Shader object中可以包含多个SubShader块,在SubShader块中,你能:
- 指定LOD;
- 使用Tags设置一些键值对;
- 添加GPU指令或着色器代码;
- 定义一个或多个Pass
- 通过PackageRequirements指定依赖的包
基础格式如下: 1
2
3
4
5
6
7SubShader
{
<optional: LOD>
<optional: tags>
<optional: commands>
<One or more Pass definitions>
}
SubShader中的Tag
Tag是定义的一些键值对,主要作用是标识出Shader的一些特性,以便Unity引擎去确定该如何以及合适使用给定的SubShader,我们也可以创建和自定义Tag,通过C#的Shader和Material类去访问这些Tag。 注意:SubShader中的Tag块和Pass中的Tag块是不同的,不能将SubShader的Tag给Pass,也不能将你Pass的Tag给SubShader。
Tag的基础格式:
1 | Tags { “[name1]” = “[value1]” “[name2]” = “[value2]”} |
RenderPipeline Tag
RenderPipeline tag用于指定是否兼容于URP和HDRP管线。可以能值:
- UniversalRenderPipeline :兼容URP;
- HighDefinitionRenderPipeline : 兼容HDRP;
- 其他值 : 不兼容URP和HDRP,主要是自定义的值,比如你新增了一个自定义的渲染你指定你自定的值;
Queue Tag
告诉Unity渲染几何对象的顺序,可能的值:
- Background, Geometry, AlphaTest, Transparent, Overlay;
- Background+1(偏移)等;
RenderType Tag
使用RenderType tag覆写Shader对象的行为。在内建渲染管线中,你能是使用shader replacement技术在运行时替换使用的SubShader。这个技术就需要RenderType tag来匹配SubShader。这在产生一些深度纹理的时候是有用的。
ForceNoShadowCasting Tag
ForceNoShadowCasting tag 不需要阴影投射pass,可能的值:
- True
- False
DisableBatching Tag
DisableBatching tag禁止将其加入到动态批处理中。这对于执行对象空间操作的着色器程序很有用。 动态批处理将所有几何体转换为世界空间,这意味着着色器程序不能再访问对象空间。 因此,依赖对象空间的着色器程序无法正确渲染。 为避免此问题,请使用此 SubShader tag来防止 Unity 应用动态批处理。可能的值:
- True
- False
- LodFading, Unity会阻止对属于LODGroup且Fade Mode值不是“None”的所有几何体进行动态批处理。 否则,Unity不会阻止动态批处理。
PreviewType Tag
PreviewType tag用于指定材质的预览对象类型,可能的值:
- Sphere, 球体
- Plane, 平面
- Skybox, 天空盒子
CanUseSpriteAtlas Tag
在使用Legacy Sprite Packer的项目中使用此SubShader tag来警告用户您的着色器依赖于原始纹理坐标,因此他们不应将其纹理打包到图集中。可能的值:
- True :兼容老的Sprite Packer, 默认值
- False: 不兼容老的Sprite Pakcer,此SubShder依赖于原始纹理坐标,不将其打包到纹理中。
SubShader中的LOD
LOD标识SubShader的LOD级别,SubShader的LOD级别不是依靠到相机的距离,而是通过Shader.maximumLOD来进行设置的。当此值改变后,Unity又会重新选择一个SubShader来使用。我们在编写带LOD的SubShader时,应该你将LOD值大的SubShader放在前面,应为Unity会选择第一个小于Shader.maximumLOD的SubShader作为激活的。
SubShader中的GPU命令
ShaderLab命令分为以下几类:
- 设置GPU渲染状态命令。
- 创建具有特定目的的Pass命令(UsePass和GrapPass)。
- 老的“固定管线风格”命令,允许你创建一个不带HLSL着色器代码的着色器程序。
可用命令如下:
Category分组命令,使用Category块去分组设置渲染状态命令,所以在这个块中的SubShader块都能继承这个些渲染状态设置。
1
2
3
4
5
6
7
8
9
10
11
12Shader "example" {
Category {
Blend One One
SubShader {
// ...
}
SubShader {
// ...
}
// ...
}
}AlphaToMask, 启用或禁用GPU的alpha-to-coverage模式。
alpha-to-coverage是指在多重采样阶段,将此片元的采样覆盖率的计算加入alpha的因素,比如在一个4x的多重采样下,4个样本计算的颜色值是(0.8, 0.8,0.8),此片元的alpha的值是0.5,那么最终的颜色值将是(0.4, 0.4, 0.4)。
1 | Shader "Examples/CommandExample" |
- Blend, 混合命令,指定混合因子
启用混合后,将禁用一些在GPU上的优化(大部分隐藏表面被移除或Early-Z),这将导致GPU的帧时间增加。 如果混合被启用,下列事情将发生:
- 如果BlendOp命令被指定则使用它指定的操作进行混合,否则将使用默认的Add进行混合。
- 如果这个混合操作时Add, Sub, RevSub, Min或Max时,GPU将片元着色器的输出值乘以源因子。
- 如果这个混合操作时Add, Sub, RevSub, Min或Max时,GPU将渲染目标中的值乘以目标因子。
- GPU对结果值执行混合操作。
混合方程为: 1
finalValue = sourceFactor * sourceValue operation destinationFactor * destinationValue
- finalValue 是GPU将写入帧缓存中的值。
- sourceFactor 定义当前片元输出时使用的因子。
- sourceValue 当前片元输出的颜色值。
- operation 混合操作类型。
- destinationFactor 定义帧缓冲中使用的因子。
- destinationValue 帧缓冲区中的值。
Blend命令格式:
| 命令格式 | 实例 | 功能说明 |
|---|---|---|
| Blend [state] | Blend Off | 禁止混合(默认值) |
| Blend [render target] [state] | Blend 1 Off | 同上一个相同,不同的是指定对应的渲染目标 |
| Blend [source factor] [destination factor] | Blend One Zero | 对默认渲染目标,设置RGBA的混合因子 |
| Blend [render target] [source factor] [destination factor] | Blend 1 One Zero | 同上一个相同,唯一不同的是指定了渲染目标 |
| Blend [source factor RGB] [destination factor RGB], [source factor alpha] [destination factor alpha] | Blend One Zero, Zero One | 分别指定了RGB和A同的混合因子 |
| Blend [render target] [source factor RGB] [destination factor RGB], [source factor alpha] [destination factor alpha] | Blend 1 One Zero, Zero One | 同上一个相同,唯一不同的是指定了特定的渲染目标0 |
Blend命令参数:
| 参数 | 值 | 功能说明 |
|---|---|---|
| rander taget | 0-7 | 渲染目标的索引 |
| state | Off | 禁用混合 |
| factor | One | 输入值是1,表示使用原或目标颜色 |
| factor | Zero | 输入值是0,表示移除原或目标值 |
| factor | SrcColor | GPU 将此输入的值乘以源颜色值 |
| factor | SrcAlpha | GPU 将此输入的值乘以源alpha值 |
| factor | DstColor | GPU 将此输入的值乘以帧缓冲区源颜色值 |
| factor | DstAlpha | GPU 将此输入的值乘以帧缓冲区源alpha值 |
| factor | OneMinusSrcColor | GPU 将此输入的值乘以(1 - 源颜色) |
| factor | OneMinusSrcAlpha | GPU 将此输入的值乘以(1 - 源alpha) |
| factor | OneMinusDstColor | GPU 将此输入的值乘以(1 - 目标颜色) |
| factor | OneMinusDstAlpha | GPU 将此输入的值乘以(1 - 目标alpha) |
- BlendOp,混合操作,指定混合时使用的操作
不是所有的混合操作在所有的设备上都支持,这依赖图像API和硬件。不同的图像API处理不支持的混合操作时是不同的:GL跳过不支持的操作,Vulkan和Meta将使用Add操作。
命令格式: 1
BlendOp <operation>
BlendOp命令参数:
| 参数 | 值 | 功能说明 |
|---|---|---|
| operation | Add | 原加目标 |
| - | Sub | 原减目标 |
| - | RevSub | 目标减原 |
| - | Min | 原和目标谁小使用谁 |
| - | Max | 原和目标谁大使用谁 |
[更多参数参见]https://docs.unity3d.com/2022.2/Documentation/Manual/SL-BlendOp.html
- ColorMask, 颜色蒙版
设置颜色通道写入蒙版,防止GPU写入渲染目标中的通道。默认情况下,GPU写入所有通道(RGBA)。对于某些效果,您可能希望不修改某些通道; 例如,您可以禁用颜色渲染来渲染无色阴影。 另一个常见的用例是完全禁用颜色写入,这样您就可以用数据填充一个缓冲区而无需写入其他缓冲区; 例如,您可能想要填充模板缓冲区 无需写入渲染目标。
命令格式:
| 命令格式 | 实例 | 功能说明 |
|---|---|---|
| 命令格式 | 实例 | 功能说明 |
| ColorMask [channels] | ColorMask RGB | 写入指定通道到渲染目标中 |
| ColorMask [channels] [target] | ColorMask RGB 2 | 同上一, 指定了渲染目标 |
- Conservative, 保守光栅化
光栅化是一种将矢量数据(三角形投影)转换为像素数据(渲染目标)通过确定哪些像素被三角形覆盖。通常,GPU通过对像素内的点进行采样,判断是否被三角形覆盖,来判断是否对像素进行光栅化;如果覆盖足够,则 GPU 确定该像素被覆盖。保守光栅化意味着GPU会光栅化被三角形部分覆盖的像素,而不管覆盖范围如何。这在需要确定性时很有用,例如在执行遮挡剔除,GPU上的碰撞检测,或可见性检测。保守的光栅化意味着GPU在三角形边缘上生成更多的片元;这导致更多的片元着色器调用,这可能导致GPU帧时间增加。
命令格式: 1
Conservative <True/False>
- Cull, 剔除操作
设置GPU应该基于多边形相对于摄像机的方向剔除哪些多边形。剔除是确定不绘制什么的过程。剔除提高了渲染效率,因为不会浪费 GPU时间来绘制在最终图像中不可见的内容。默认情况下,GPU 执行背面剔除;这意味着它不绘制背对观察者的多边形。一般来说,渲染工作量减少得越多越好;因此,只在必要时才应更改此设置。
命令格式: 1
Cull <Back/Front/Off>
- Offset, 深度偏移
设置 GPU 上的深度偏差。深度偏差,也称为深度偏移,是GPU上的一个设置,决定了GPU绘制几何体的深度。调整深度偏差以强制GPU在具有相同深度的其他几何体之上绘制几何体。这可以帮助您避免不需要的视觉效果,例如深度冲突和阴影暗斑。要为特定几何体设置深度偏差,请使用此命令或 RenderStateBlock 。要设置影响所有几何体的全局深度偏差,请使用 CommandBuffer.SetGlobalDepthBias。除了全局深度偏差之外,GPU还为特定几何体应用深度偏差。
为了减少阴影暗斑,您可以使用 light bias 设置实现类似的视觉效果;但是,这些设置的工作方式不同,并且不会更改 GPU 上的状态。有关更多信息,请参阅阴影故障排除。
命令格式:
Offset [factor], [units]
Offset命令参数:
| 参数 | 值 | 功能说明 |
|---|---|---|
| factor | 浮点数,范围-1到1 | 缩放最大 Z 斜率,也称为深度斜率,以生成每个多边形的可变深度偏移。不平行于近剪裁平面和远剪裁平面的多边形具有 Z 斜率。调整此值以避免此类多边形上出现视觉瑕疵。 |
| units | 浮点数,范围 –1 到 1。 | 缩放最小可分辨深度缓冲区值,以产生恒定的深度偏移。最小可分辨深度缓冲区值(一个 unit)因设备而异。负值意味着 GPU 将多边形绘制得更靠近摄像机。正值意味着 GPU 将多边形绘制得更远离摄像机。 |
- Stencil, 模板命令
模板缓冲区为帧缓冲区中的每个像素存储一个 8 位整数值。为给定像素执行片元着色器之前,GPU 可以将模板缓冲区中的当前值与给定参考值进行比较。这称为模板测试。如果模板测试通过,则 GPU 会执行深度测试。如果模板测试失败,则 GPU 会跳过对该像素的其余处理。这意味着可以使用模板缓冲区作为遮罩来告知 GPU 要绘制的像素以及要丢弃的像素。通常会将模板缓冲区用于特殊效果,例如门户或镜子。此外,在渲染硬阴影或者构造型实体几何 (CSG) 时,有时会使用模板缓冲区。
使用 Ref、ReadMask 和 Comp 参数可配置模板测试。使用 Ref、WriteMask、Pass、Fail 和 ZFail 参数可配置模板写入操作。
模板测试方程为: 1
(ref & readMask) comparisonFunction (stencilBufferValue & readMask)
命令格式: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18Stencil
{
Ref <ref>
ReadMask <readMask>
WriteMask <writeMask>
Comp <comparisonOperation>
Pass <passOperation>
Fail <failOperation>
ZFail <zFailOperation>
CompBack <comparisonOperationBack>
PassBack <passOperationBack>
FailBack <failOperationBack>
ZFailBack <zFailOperationBack>
CompFront <comparisonOperationFront>
PassFront <passOperationFront>
FailFront <failOperationFront>
ZFailFront <zFailOperationFront>
}
- UsePass, 使用Pass命令
UsePass 命令插入来自另一个 Shader 对象的指定通道。可以使用此命令来减少着色器源文件中的代码重复。
- GrabPass
GrabPass 是一个创建特殊类型通道的命令,该通道将帧缓冲区的内容抓取到纹理中。在后续通道中即可使用此纹理,从而执行基于图像的高级效果。此命令会显著增加 CPU 和 GPU 帧时间。除了快速原型制作之外,您通常应该避免使用此命令,并尝试通过其他方式实现您的效果。如果您确实使用了此命令,尽量减少屏幕抓取操作的次数;方法是减少您对该命令的使用,或者使用将屏幕抓取到命名纹理的签名(如果适用)。
命令格式:
| 格式 | 功能说明 |
|---|---|
| GrabPass { } | 将帧缓冲区内容抓取到一个纹理中,使您可以在同一个子着色器中的后续通道中使用该纹理。使用 _GrabTexture 名称引用该纹理。当您使用此签名时,Unity 每次渲染包含此命令的批处理时都会抓取屏幕。这意味着 Unity 可以每帧多次抓取屏幕:每批次一次。 |
| GrabPass { "ExampleTextureName" } | 将帧缓冲区内容抓取到一个纹理中,使您可以在同一帧的后续通道中跨多个子着色器访问该纹理。使用给定名称引用该纹理。当您使用此签名时,Unity 会在渲染批处理的帧中第一次抓取屏幕,该批处理包含具有给定纹理名称的此命令。 |
- ZClip, 深度裁剪
设置 GPU 的深度裁剪模式,从而确定 GPU 如何处理近平面和远平面之外的片元。将 GPU 的深度裁剪模式设置为钳位对于模板阴影渲染很有用;这意味着当几何体超出远平面时不需要特殊处理,从而减少渲染操作。但是,它可能会导致不正确的 Z 排序。
命令格式: ZClip [enabled]
命令参数:
| 参数 | 值 | 功能说明 |
|---|---|---|
| enabled | True | 将深度裁剪模式设置为裁剪。这是默认设置。 |
| False | 将深度裁剪模式设置为钳位。比近平面更近的片元正好在近平面,而比远平面更远的片元正好在远平面。 |
- ZTest, 深度测试
设置几何体是否通过深度测试的条件。深度测试可使具有 “Early-Z” 功能的 GPU 在管线早期拒绝几何体,并确保几何体的正确排序。通过改变深度测试的条件,您可以实现物体遮挡等视觉效果。
命令格式: ZTest [operation]
命令参数:
| 参数 | 值 | 功能说明 |
|---|---|---|
| operation | Less | 绘制位于现有几何体前面的几何体。不绘制位于现有几何体相同距离或后面的几何体。 |
| LEqual | 绘制位于现有几何体前面或相同距离的几何体。不绘制位于现有几何体后面的几何体。这是默认值。 | |
| ... | 其他的值,参见官网 |
- ZWrite, 深度写入
设置在渲染过程中是否更新深度缓冲区内容。通常,ZWrite 对不透明对象启用,对半透明对象禁用。禁用 ZWrite 会导致不正确的深度排序。这种情况下,您需要在 CPU 上对几何体进行排序。
命令格式: ZWrite [state]
命令参数:
| 参数 | 值 | 功能说明 |
|---|---|---|
| state | On | 启用写入深度缓冲区。 |
| Off | 禁用写入深度缓冲区。 |
SubShader中的Pass
Pass是Shader object中的基础元素,它包含了GPU状态设置指令,以及着色器程序。简单的Shader object可能包含仅单个Pass,但更复杂的Shader能包含多个Pass。通过多个Pass可以定义Shader object中不同的部分;例如,需要更改渲染状态、不同着色器程序或不同LightMode Pass标签。
注意:在SRP管线中,能通过RenderStateBlock去改变GPU的渲染器状态,不需要单独的Pass去改变状态。
在一个Pass块中,你能:
- 通过Name块指定一个Pass的名字;
- 使用Tags块去指定Tags的键值对;
- 执行GPU命令;
- 添加着色器代码;
- 通过PackageRequirements指定依赖的包
格式如下:
1 | Pass |
Pass中的Tags
Pass中,比较通用的Tag是LightMode, 此Tag可以用于所有的渲染管线。Pass中其他Tag根据渲染管线的不同而不同。 - 在内建管线,Unity预定义的Pass中使用的Tag - 在URP中,Unity预定义的Pass中使用的Tag
在SubShader和Pass块中都能使用Tags块,但是它们的工作是不同的。在SubShader中的Tags在Pass中将没有效果,反之亦然。
在内建渲染管线,如果你不设置LightMode tag, Unity渲染时将不使用灯光和阴影,这本质上就是讲LightMode设置为Always。在SRP中,你能使用SRPDefaultUnlit值来达到同样的效果。
内置管线的Pass中的Tags参见官网
Pass中的Commands
Pass中的使用的Commands和SubShader中的是相同的。
Pass中的Shader code
在 Unity 中,您通常使用 HLSL 编写着色器程序。要将 HLSL 代码添加到您的着色器资源,应将该代码放在一个着色器代码块 中。注意:Unity 还支持使用其他语言编写着色器程序,不过通常不需要或不推荐这样做。
着色器代码块的类型:
HLSL:
- HLSLPROGRAM , ENDHLSL 表示着色器代码块
- HLSLINCLUDE, ENDHLSL 表示着色器include块
CG:
- CGPROGRAM, ENDCG 表示着色器代码块
- CGINCLUDE, ENDCG 表示着色器include块
- CG一般在老版本中使用,不能在新的URP和HDRP中使用,但HLSL却能在所有的管线中使用,建议都直接使用HLSL。
示例: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37Shader "Examples/ExampleShader"
{
SubShader
{
HLSLINCLUDE
// 在此编写要共享的 HLSL 代码
ENDHLSL
Pass
{
Name "ExampleFirstPassName"
Tags { "LightMode" = "ExampleLightModeTagValue" }
// 在此编写设置渲染状态的 ShaderLab 命令
HLSLPROGRAM
// 此 HLSL 着色器程序自动包含上面的 HLSLINCLUDE 块的内容
// 在此编写 HLSL 着色器代码
ENDHLSL
}
Pass
{
Name "ExampleSecondPassName"
Tags { "LightMode" = "ExampleLightModeTagValue" }
// 在此编写设置渲染状态的 ShaderLab 命令
HLSLPROGRAM
// 此 HLSL 着色器程序自动包含上面的 HLSLINCLUDE 块的内容
// 在此编写 HLSL 着色器代码
ENDHLSL
}
}
}
HLSL着色器语言
HLSL语言有两种语法:旧版的 DirectX 9 样式语法以及更现代的 DirectX 10+ 样式语法。不同之处主要在于纹理采样函数的工作方式:
- 旧版语法使用 sampler2D、tex2D() 和类似函数。此语法适用于所有平台。
- DX10+ 语法使用 Texture2D、SamplerState 和 .Sample() 函数。由于纹理和采样器在 OpenGL 中不是不同对象,因此该语法的某些形式在 OpenGL 平台上无效。
Unity 提供了包含预处理器宏的着色器库来帮助您管理这些差异。有关更多信息,请参阅内置着色器宏。
HLSL中的预处理器指令
在内部,着色器编译有多个阶段。第一阶段是预处理,一个称为预处理器的程序为编译准备代码。预处理器指令是用于预处理器的指令。本文的这一部分包含有关使用 HLSL 预处理器指令和 Unity 独有的 HLSL 预处理器指令的特定于 Unity 的方法的信息。它不包含有关 HLSL 支持的所有预处理器指令的详尽文档,或有关在 HLSL 中使用预处理器指令的一般信息。有关该信息,请参阅 HLSL 文档:预处理器指令 (HLSL)。
HLSL中的include和include_with_pragmas指令
在 HLSL 中,#include指令是一种预处理指令。它们指示编译器将一个 HLSL 文件的内容包含在另一个文件中。它们包含的文件称为包含文件。在 Unity 中,常规#include指令的工作方式与标准 HLSL 中的相同。Unity 还提供了一个额外的、特定于 Unity 的#include_with_pragmas指令。该#include_with_pragmas指令的工作方式与常规#include指令相同,但它还允许您#pragma在包含文件中使用指令。这意味着该#include_with_pragmas指令允许您#pragma在多个文件之间共享指令。
注意:要使用#include_with_pragmas指令,您必须启用缓存着色器预处理器(Project setting->Editor)。
pragma预处理指令
在 HLSL 中,#pragma指令是一种预处理指令。它们为着色器编译器提供其他类型的预处理器指令未涵盖的附加信息。
使用 pragma 指令 您可以将#pragma指令放在 HLSL
代码中的任何位置,但通常将它们放在开头,如下所示: 1
2
3
4
5
6#pragma target 3.0
#pragma exclude_renderers vulkan
#pragma vertex vert
#pragma fragment frag
// The rest of your HLSL code goes here
限制
pragma指令的限制如下:
你能使用#pragma指令在#if指令内部,如果表达式依赖如下:
- 任意自定义的#define定义
- 下列平台关键字:SHADER_API_MOBILE, SHADER_API_DESKTOP, UNITY_NO_RGBM, UNITY_USE_NATIVE_HDR, UNITY_FRAMEBUFFER_FETCH_AVAILABLE, UNITY_NO_CUBEMAP_ARRAY
- UNITY_VERSION宏
您只能在.shader文件以及包含在#include_with_pragmas指令中的文件中使用Unity特定的#pragma指令。 Unity在您使用 #include指令包含的文件中不支持它们; 编译器会忽略它们。
您只能在使用#include指令包含的文件中使用标准HLSL #pragma指令。 Unity不支持它们在.shader文件中,或者在您使用 #include_with_pragmas指令包含的文件中;编译器会忽略它们。
支持的pragma预处理指令列表 在一个常规的包含文件中,unity支持所有标准HLSL中的指令。更多HLSL的指令参见HLSL文档。 另外,Unity支持以下Unity特定的#pragma指令:
表面着色器:
- #pragma surface [surface function] [lighting model] [optional parameters], 表面着色器
着色器阶段:
- #pragma vertex [name] 指定顶点着色器函数
- #pragma hull [name] 指定曲面细分着色器的hull函数
- #pragma domain [name]指定曲面细分着色器的domain函数
- #pragma geometry [name] 指定几何着色器函数
- #pragma fragment [name] 指定片元着色器函数
着色器变体和关键字:
- #pragma multi_compile [keywords] 声明关键字的集合。编译器包含构建中的所有关键字。您可以使用诸如_local设置附加选项的后缀。
- #pragma shader_feature [keywords] 声明关键字的集合。编译器会从构建中排除未使用的关键字。您可以使用诸如_local设置附加选项的后缀。
- #pragma hardware_tier_variants [values] 仅内置渲染管道:为给定的图形 API 编译时为图形层添加关键字。
- #pragma skip_variants [list of keywords] 剥离指定的关键字。
GPU要求和着色器模型支持:
- #pragma target [value] 此着色器程序兼容的最小着色器模型。将 [value] 替换为有效值。
- #pragma require [value] 不要为给定的图形 API 编译此着色器程序。将 [value' 替换为以空格分隔的有效值列表。
图形API:
- #pragma only_renderers [value] 仅为给定的图形API编译此着色器程序。将[values]替换为以空格分隔的有效值列表。
- #pragma exclude_renderers [value] 不要为给定的图形 API 编译此着色器程序。将 [value] 替换为以空格分隔的有效值列表。
其他pragma指令:
- #pragma instancing_options [options] 使用给定选项在此着色器中启用GPU实例化。有关详细信息,请参阅GPU实例化
- #pragma once 将此指令放在一个文件中,以确保编译器在着色器程序中只包含一次该文件。注意: Unity 仅在启用缓存着色器预处理器时支持此指令。
- #pragma enable_d3d11_debug_symbols 为支持的图形API生成着色器调试符号,并禁用所有图形API的优化。使用它在外部工具中调试着色器代码。Unity 为 Vulkan、DirectX 11 和 12 以及支持的控制台平台生成调试符号。
- #pragma skip_optimizations [value] 强制关闭给定图形API的优化。将 [values] 替换为以空格分隔的有效值列表。
- #pragma hlslcc_bytecode_disassembly 将反汇编的 HLSLcc 字节码嵌入到翻译后的着色器中。
- #pragma disable_fastmath 启用涉及NaN处理的精确IEEE 754规则。这目前仅影响 Metal 平台。
- #pragma editor_sync_compilation 强制同步编译。这仅影响 Unity 编辑器。
- #pragma enable_cbuffer 使用HLSLSupport中的 CBUFFER_START(name) 和 CBUFFER_END 宏时发出 cbuffer(name),即使当前平台不支持常量缓冲区。
在HLSL中Shader Model目标和GPU特性
您可以使用#pragma指令来指示一个着色器需要某些GPU功能。在运行时,Unity使用此信息来确定着色器程序是否与当前硬件兼容。您可以使用#pragma require指令指定单个 GPU 功能,或使用指令#pragma target指定着色器模型。着色器模型是一组GPU功能的简写;在内部,它与#pragma require具有相同功能列表的指令相同。正确描述着色器所需的GPU功能非常重要。如果您的着色器使用了未包含在要求列表中的功能,这可能会导致编译时错误,或者导致设备在运行时无法支持着色器。
默认情况下,Unity使用编译着色器#pragma require derivatives,对应于#pragma target 2.5.
着色器阶段的特殊要求 如果您的着色器定义了某些着色器阶段,Unity 会自动将项目添加到需求列表中。
- 如果着色器定义了几何阶段(使用#pragma geometry),Unity 会自动添加geometry到需求列表中。
- 如果着色器定义了曲面细分阶段(使用#pragma hull或#pragma domain),Unity 会自动添加tessellation到需求列表中。
如果需求列表(或等效的目标值)尚未包含这些值,Unity 在编译着色器时会显示一条警告消息,表明它已添加这些需求。为避免看到此警告消息,请在代码中显式添加要求或使用适当的目标值。
指定 GPU 功能或着色器模型
要指定所需的功能,请使用该#pragma require指令,后跟以空格分隔的值列表。例如:
1 | #pragma require integers mrt8 |
您还可以使用该#pragma require指令后跟一个冒号和一个以空格分隔的着色器关键字列表。这意味着该要求仅适用于在启用任何给定关键字时使用的变体。例如:
1 | #pragma require integers mrt8 : EXAMPLE_KEYWORD OTHER_EXAMPLE_KEYWORD |
您可以使用多#pragma require行。在此示例中,着色器integers在所有情况下都需要,并且mrt8如果启用了 EXAMPLE_KEYWORD。
1 | #pragma require integers |
要指定着色器模型,请使用#pragma target指令。例如:
1 | #pragma target 4.0 |
您还可以使用该#pragma target指令后跟以空格分隔的着色器关键字列表。这意味着该要求仅适用于在启用任何给定关键字时使用的变体。例如:
1 | #pragma target 4.0 EXAMPLE_KEYWORD OTHER_EXAMPLE_KEYWORD |
'#pragma target' 值列表 '#pragma require' 值列表
声明和使用着色器关键字
在您的HLSL代码中,使用#pragma指令来声明着色器关键字,并使用#if指令来指示着色器代码的一部分取决于着色器关键字的状态。 您可以在常规图形着色器(包括表面着色器)中使用着色器关键字)和计算着色器。
声明着色器关键字 要声明着色器关键字,请在 HLSL 代码中使用以下 #pragma 指令之一:
- #pragma multi_compile 声明一组关键字。默认情况下,这些关键字具有全局范围并影响所有着色器阶段。构建过程包括该集合中的所有关键字。
- #pragma shader_feature 声明一组关键字,并指示编译器编译丢弃没有启用的关键字的变体。默认情况下,这些关键字具有全局范围并影响所有着色器阶段。构建过程包括该集合中在构建时使用的关键字。
注意:如果您将着色器添加到图形设置窗口中的 Always Included Shaders列表中,Unity会在构建中包含来自所有集合的所有关键字,即使它们是用声明的#pragma shader_feature。
您还可以为这些指令添加后缀来修改它们的行为:
- 添加_local表示一组关键字具有局部作用域,不能被全局关键字覆盖;否则,关键字具有全局范围,并且可以被全局关键字覆盖。您可以将此后缀添加到#pragma multi_compile、 或#pragma shader_feature指令后面;例如,#pragma multi_compile_local和#pragma shader_feature_local是有效的。
- 添加_vertex, _fragment, _hull, _domain, _geometry, 或_raytracing表示一组关键字仅影响给定的着色器阶段,这可以减少不需要的着色器变体的数量。您可以将这些后缀添加到指令#pragma multi_compile或#pragma shader_feature指令中,无论是独立的还是在_local修饰符之后;例如,#pragma multi_compile_vertex并且#pragma shader_feature_local_fragment是有效的。
此外,还有一些#pragma multi_compile添加预定义关键字集的“快捷方式”变体。有关这些的更多信息,请参阅multi_compile 快捷方式。
声明一组关键字
您在集合中声明关键字。一个集合包含互斥的关键字。要声明一组关键字,请使用#pragma
multi_compileor#pragma_shader_feature指令,后跟以空格分隔的关键字列表。此示例演示如何声明一组四个关键字:
1
#pragma multi_compile QUALITY_LOW QUALITY_MEDIUM QUALITY_HIGH QUALITY_ULTRA
当您使用#pragma shader_feature声明一组关键字时,Unity
还会编译一个变体,其中没有定义该组中的任何关键字。这允许您在不使用附加关键字的情况下定义行为。
减少关键字的数量在几个方面是有益的:它可以减少 Unity
编译的变体总数,从而提高构建时间和运行时性能;它减少了着色器使用的关键字总数,从而防止它达到着色器关键字限制;并且它使得从
C#
脚本管理关键字状态变得更简单,因为启用和禁用的关键字更少。这个例子演示了如何声明一个只包含一个关键字的集合:
1
#pragma shader_feature EXAMPLE_ON
1
#pragma multi_compile __ EXAMPLE_ON
限制
声明关键字集的方式有一些限制:
- 您不能在同一个集合中多次包含相同的关键字;但是,您可以在不同的集合中声明相同的关键字。
- 您不能在着色器程序中多次声明同一组关键字。
- 着色器可以使用的关键字数量是有限制的。着色器源文件中声明的每个关键字及其依赖项都计入此限制。
使用着色器关键字
要编译仅在启用给定着色器关键字时使用的代码,请使用#if指令,如下所示:
1
2
3
4
5
6
7// 声明关键字集
#pragma multi_compile QUALITY_LOW QUALITY_MEDIUM QUALITY_HIGH QUALITY_ULTRA
#if QUALITY_ULTRA
// 此处的代码针对启用关键字 QUALITY_ULTRA 时使用的变体进行编译
#endif
multi_compile 快捷方式
Unity为声明着色器关键字提供了几种“快捷方式”表示法。以下快捷键与内置渲染管线中的光照、阴影和光照贴图相关:
- multi_compile_fwdbase添加这组关键字:DIRECTIONAL LIGHTMAP_ON DIRLIGHTMAP_COMBINED DYNAMICLIGHTMAP_ON SHADOWS_SCREEN SHADOWS_SHADOWMASK LIGHTMAP_SHADOW_MIXING LIGHTPROBE_SH。PassType.ForwardBase需要这些变体。
- multi_compile_fwdbasealpha添加这组关键字:DIRECTIONAL LIGHTMAP_ON DIRLIGHTMAP_COMBINED DYNAMICLIGHTMAP_ON LIGHTMAP_SHADOW_MIXING VERTEXLIGHT_ON LIGHTPROBE_SH。PassType.ForwardBase需要这些变体。
- multi_compile_fwdadd添加这组关键字:POINT DIRECTIONAL SPOT POINT_COOKIE DIRECTIONAL_COOKIE。PassType.ForwardAdd需要这些变体。
- multi_compile_fwdadd_fullshadows添加这组关键字:POINT DIRECTIONAL SPOT POINT_COOKIE DIRECTIONAL_COOKIE SHADOWS_DEPTH SHADOWS_SCREEN SHADOWS_CUBE SHADOWS_SOFT SHADOWS_SHADOWMASK LIGHTMAP_SHADOW_MIXING。这与 相同multi_compile_fwdadd,但这增加了灯光具有实时阴影的能力。
- multi_compile_lightpass添加这组关键字:POINT DIRECTIONAL SPOT POINT_COOKIE DIRECTIONAL_COOKIE SHADOWS_DEPTH SHADOWS_SCREEN SHADOWS_CUBE SHADOWS_SOFT SHADOWS_SHADOWMASK LIGHTMAP_SHADOW_MIXING。这实际上是与实时光和阴影相关的所有功能的全能快捷方式,除了 Light Probes。
- multi_compile_shadowcaster添加这组关键字:SHADOWS_DEPTH SHADOWS_CUBE。PassType.ShadowCaster需要这些变体。
- multi_compile_shadowcollector添加这组关键字:SHADOWS_SPLIT_SPHERES SHADOWS_SINGLE_CASCADE。它还编译没有任何这些关键字的变体。屏幕空间阴影需要这些变体。
- multi_compile_prepassfinal添加这组关键字:LIGHTMAP_ON DIRLIGHTMAP_COMBINED DYNAMICLIGHTMAP_ON UNITY_HDR_ON SHADOWS_SHADOWMASK LIGHTPROBE_SH。它还编译没有任何这些关键字的变体。PassType.LightPrePassFinal和PassType.Deferred需要这些变体。
以下快捷方式与其他设置相关:
- multi_compile_particles添加与内置粒子系统相关的关键字:SOFTPARTICLES_ON。它还编译没有这个关键字的变体。有关详细信息,请参阅内置粒子系统。
- multi_compile_fog添加了这组与雾相关的关键字:FOG_LINEAR、FOG_EXP、FOG_EXP2。它还编译没有任何这些关键字的变体。您可以在图形设置窗口中控制此行为。
- multi_compile_instancing添加与实例化相关的关键字。如果着色器使用程序实例化,它会添加这组关键字:INSTANCING_ON PROCEDURAL_ON。否则,它会添加此关键字:INSTANCING_ON。它还编译没有任何这些关键字的变体。您可以在图形设置窗口中控制此行为。
这些快捷方式中的大多数都包含多个关键字。如果您知道项目不需要它们,您可以使用#pragma
skip_variants删除其中的一些。例如: 1
2# pragma multi_compile_fwdadd
# pragma skip_variants POINT POINT_COOKIE
着色器语义
编写 HLSL 着色器程序时, 输入和输出变量需要通过语义来表明 其“意图”。这是HLSL着色器语言中的标准概念;请参阅MSDN上的语义(Semantics)文档以了解更多详细信息。
顶点着色器输入语义
主顶点着色器函数(由 #pragma vertex 指令表示)需要在所有输入参数上都有语义。 这些对应于各个网格数据元素,如顶点位置、法线网格和纹理坐标
常用语义:
| 语义 | 数据类型 | 功能说明 |
|---|---|---|
| POSITION | float3 或float4 | 顶点位置 |
| NORMAL | float3 | 顶点法线 |
| BINORMAL | float4 | 顶点副法线 |
| TEXCOORD[n] | float2, float3或float4 | UV坐标 |
| TANGENT | float4 | 顶点切线 |
| COLOR | float4 | 顶点颜色 |
当网格数据包含的组件少于顶点着色器输入所需的组件时,其余部分用零填充,但.w 默认为1。例如,网格纹理坐标通常是只有 x 和 y 组件的 2D 向量。如果顶点着色器声明一个带有TEXCOORD0语义的float4的输入,则顶点着色器将包含(x,y,0,1)。
顶点着色器输出和片段着色器输入语义
顶点着色器需要输出一个顶点的最终裁剪空间位置,以便 GPU 知道在屏幕上的哪个位置对它进行光栅化,以及在什么深度。这个输出需要有SV_POSITION语义,并且是一个float4类型。
顶点着色器产生的任何其他输出(“插值器”或“变量”)都是您特定的着色器需要的。顶点着色器输出的值将在渲染三角形的面上进行插值,每个像素的值将作为输入传递给片段着色器。
许多现代 GPU 并不真正关心这些变量的语义。然而,一些旧系统(尤其是 Direct3D 9 上的着色器模型 2 GPU)确实有关于语义的特殊规则:
- TEXCOORD0等TEXCOORD1用于指示任意高精度数据,例如纹理坐标和位置。
- COLOR0顶点输出和COLOR1片段输入的语义适用于低精度、0-1 范围的数据(如简单的颜色值)。
为了获得最佳跨平台支持,请将顶点输出和片段输入标记为TEXCOORDn语义。
常用语义:
| 语义 | 数据类型 | 功能说明 |
|---|---|---|
| SV_POSITION | float3 或float4 | 顶点位置 |
| COLOR | float4 | 输出的顶点颜色 |
插值器计数限制:
总共可以使用多少个插值器变量来将信息从顶点传递到片段着色器是有限制的。限制取决于平台和 GPU,一般准则是:
- 最多 8 个插值器:OpenGL ES 2.0 (Android)、Direct3D 11 9.x 级别(Windows Phone)和 Direct3D 9 着色器模型 2.0(旧 PC)。由于插值器的数量是有限的,但每个插值器可以是一个 4 分量向量,一些着色器将事物打包在一起以保持在限制范围内。例如,可以在一个float4变量中传递两个纹理坐标(.xy 代表一个坐标,.zw 代表第二个坐标)。
- 最多 10 个插值器:Direct3D 9 着色器模型 3.0 ( #pragma target 3.0)。
- 最多 16 个插值器:OpenGL ES 3.0 (Android)、Metal (iOS)。
- 最多 32 个插值器:Direct3D 10 着色器模型 4.0 ( #pragma target 4.0)。
无论您的特定目标硬件如何,出于性能原因,使用尽可能少的插值器通常是一个好主意。
片段着色器输出语义
大多数情况下,片段(像素)着色器输出颜色,并具有
SV_Target语义。上面示例中的片段着色器正是这样做的: 1
fixed4 frag (v2f i) : SV_Target
常用语义:
| 语义 | 数据类型 | 功能说明 |
|---|---|---|
| SV_Target[n] | fixed4 | SV_Target1, SV_Target2, 等:这些是着色器写入的附加颜色。这在一次渲染到多个渲染目时使用(称为多渲染目标渲染技术,或 MRT)。SV_Target0是一样的SV_Target。 |
| SV_Depth | float4 | 通常片段着色器不会覆盖 Z 缓冲区值,并且使用来自正三角形的默认值光栅化. 但是,对于某些效果,输出每个像素的自定义 Z 缓冲区深度值很有用。 |
注意,在许多 GPU 上,这会关闭一些深度缓冲区 优化,所以不要在没有充分理由的情况下覆盖 Z 缓冲区值。所产生的成本因SV_DepthGPU 架构而异,但总体而言,它与 alpha 测试的成本非常相似(使用 HLSL 中的内置clip()函数)。
其他特殊语义
| 语义 | 数据类型 | 功能说明 |
|---|---|---|
| VPOS | UNITY_VPOS_TYPE | 片段着色器可以接收被渲染为特殊VPOS语义的像素位置。此功能仅从着色器模型 3.0 开始存在,因此着色器需要具有#pragma target 3.0编译指令。在不同的平台上,屏幕空间位置输入的底层类型会有所不同,因此为了获得最大的可移植性,请使用它的UNITY_VPOS_TYPE类型(在大多数平台上它将是float4,在Direct3D 9上为 float2)。此外,使用像素位置语义使得裁剪空间位置 (SV_POSITION) 和 VPOS 很难在相同的在顶点到片段结构中。所以顶点着色器应该将裁剪空间位置作为一个单独的“out”变量输出。 |
| VFACE | float | 片段着色器可以接收一个变量,该变量指示渲染的表面是否面向相机,或背对相机。这在渲染应该从两侧可见的几何图形时很有用——通常用于树叶和类似的薄物体。正值为三角形正面,负值为三角形的背面。此功能仅从着色器模型 3.0 开始存在,因此着色器需要具有#pragma target 3.0编译指令。 |
| SV_VertexID | uint | 顶点着色器可以接收具有“顶点编号”作为无符号整数的变量。当您想从纹理或ComputeBuffers获取额外的每个顶点数据时,这非常有用。此功能仅存在于 DX10(着色器模型 4.0)和 GLCore / OpenGL ES 3 中,因此着色器需要具有#pragma target 3.5编译指令。 |
在 Cg/HLSL 中访问着色器属性
ShaderLab 中的属性类型以如下方式映射到 Cg/HLSL 变量类型:
- Color 和 Vector 属性映射到 float4、half4 或 fixed4 变量。
- Range 和 Float 属性映射到 float、half 或 fixed 变量。
- 对于普通 (2D) 纹理,Texture 属性映射到 sampler2D 变量;立方体贴图 (Cubemap) 映射到 samplerCUBE;3D纹理映射到sampler3D。
如何向着色器提供属性值
在下列位置中查找着色器属性值并提供给着色器:
- MaterialPropertyBlock 中设置的每渲染器值。这通常是“每实例”数据(例如,全部共享相同材质的许多对象的自定义着色颜色)。
- 在渲染的对象上使用的材质中设置的值。
- 全局着色器属性,通过 Unity 渲染代码自身设置(请参阅内置着色器变量),或通过您自己的脚本来设置(例如 Shader.SetGlobalTexture)。
优先顺序如上所述:每实例数据覆盖所有内容;然后使用材质数据;最后,如果这两个地方不存在着色器属性,则使用全局属性值。最终,如果在任何地方都没有定义着色器属性值,则将提供“默认值”(浮点数的默认值为零,颜色的默认值为黑色,纹理的默认值为空的白色纹理)。
序列化和运行时材质属性
材质可以同时包含序列化的属性值和运行时设置的属性值。
序列化的数据是在着色器的 Properties 代码块中定义的所有属性。通常,这些是需要存储在材质中的值,并且可由用户在材质检视面板中进行调整。
材质也可以具有着色器使用的一些属性,但不在着色器的 Properties 代码块中声明。通常,这适用于在运行时从脚本代码(例如,通过 Material.SetColor)设置的属性。请注意,矩阵和数组只能作为非序列化的运行时属性存在(因为无法在 Properties 代码块中定义它们)。
特殊纹理属性
对于设置为着色器/材质属性的每个纹理,Unity 还会在其他矢量属性中设置一些额外信息。
纹理平铺和偏移
材质通常具有其纹理属性的 Tiling 和 Offset 字段。此信息将传递到着色器中的 float4 {TextureName}_ST 属性:
- x 包含 X 平铺值
- y 包含 Y 平铺值
- z 包含 X 偏移值
- w 包含 Y 偏移值
例如,如果着色器包含名为 _MainTex 的纹理,则平铺信息将位于 _MainTex_ST 矢量中。
纹理大小
{TextureName}_TexelSize - float4 属性包含纹理大小信息:
- x 包含 1.0/宽度
- y 包含 1.0/高度
- z 包含宽度
- w 包含高度
纹理 HDR 参数 {TextureName}_HDR - 一个 float4 属性,其中包含有关如何根据所使用的颜色空间解码潜在 HDR(例如 RGBM 编码)纹理的信息。请参阅 UnityCG.cginc 着色器 include 文件中的 DecodeHDR 函数。
颜色空间和颜色/矢量着色器数据
使用线性颜色空间时,所有材质颜色属性均以 sRGB 颜色提供,但在传递到着色器时会转换为线性值。
例如,如果 Properties 着色器代码块包含名为“MyColor“的 Color 属性,则相应的”MyColor”HLSL 变量将获得线性颜色值。
对于标记为 Float 或 Vector 类型的属性,默认情况下不进行颜色空间转换;而是假设它们包含非颜色数据。可为浮点/矢量属性添加 [Gamma] 特性,以表示它们是以 sRGB 空间指定,就像颜色一样
内置宏
Unity在编译着色器程序时会定义几个预处理器宏。
内置着色器 helper 函数
Unity 具有许多内置实用函数,旨在使编写着色器更简单,更轻松。
内置着色器变量
Unity 的内置文件包含着色器的全局变量:当前对象的变换矩阵、光源参数、当前时间等等。就像任何其他变量一样,可在着色器程序中使用这些变量,但如果已经包含相关的 include 文件,则不必声明这些变量。参见官网
着色器数据类型和精度
Unity 中的标准着色器语言为 HLSL,支持一般 HLSL 数据类型。但是,Unity 对 HLSL 类型有一些补充,特别是为了在移动平台上提供更好的支持。
基本数据类型
着色器中的大多数计算是对浮点数(在 C# 等常规编程语言中为 float)进行的。浮点类型有几种变体:float、half 和 fixed(以及它们的矢量/矩阵变体,比如 half3 和 float4x4)。这些类型的精度不同(因此性能或功耗也不同):
高精度:float 最高精度浮点值;一般是 32 位(就像常规编程语言中的 float)。
完整的 float 精度通常用于世界空间位置、纹理坐标或涉及复杂函数(如三角函数或幂/取幂)的标量计算。
中等精度:half 中等精度浮点值;通常为 16 位(范围为 –60000 至 +60000,精度约为 3 位小数)。
半精度对于短矢量、方向、对象空间位置、高动态范围颜色非常有用。
低精度:fixed 最低精度的定点值。通常是 11 位,范围从 –2.0 到 +2.0,精度为 1/256。
固定精度对于常规颜色(通常存储在常规纹理中)以及对它们执行简单运算非常有用。
整数数据类型 整数(int 数据类型)通常用作循环计数器或数组索引。为此,它们通常可以在各种平台上正常工作。
根据平台的不同,GPU 可能不支持整数类型。例如,Direct3D 9 和 OpenGL ES 2.0 GPU 仅对浮点数据进行运算,并且可以使用相当复杂的浮点数学指令来模拟简单的整数表达式(涉及位运算或逻辑运算)。
Direct3D 11、OpenGL ES 3、Metal 和其他现代平台都对整数数据类型有适当的支持,因此使用位移位和位屏蔽可以按预期工作。
复合矢量/矩阵类型
HLSL 具有从基本类型创建的内置矢量和矩阵类型。例如,float3 是一个 3D 矢量,具有分量 .x、.y 和 .z,而 half4 是一个中等精度 4D 矢量,具有分量 .x、.y、.z 和 .w。或者,可使用 .r、.g、.b 和 .a 分量来对矢量编制索引,这在处理颜色时很有用。
矩阵类型以类似的方式构建;例如 float4x4 是一个 4x4 变换矩阵。请注意,某些平台仅支持方形矩阵,最主要的是 OpenGL ES 2.0。
纹理/采样器类型
通常按照如下方式在 HLSL 代码中声明纹理: 1
2sampler2D _MainTex;
samplerCUBE _Cubemap;1
2sampler2D_half _MainTex;
samplerCUBE_half _Cubemap;1
2sampler2D_float _MainTex;
samplerCUBE_float _Cubemap;
精度、硬件支持和性能
使用 float/half/fixed 数据类型的一个难题是:PC GPU 始终为高精度。也就是说,对于所有 PC (Windows/Mac/Linux) GPU,在着色器中编写 float、half 还是 fixed 数据类型都无关紧要。这些 GPU 将始终以 32 位浮点精度来计算所有数据。
仅当目标平台是移动端 GPU 时,half 和 fixed 类型才变得重要,在这种情况下,这些类型主要面临功耗(有时候是性能)约束。请记住,要确认是否遇到精度/数值问题,必须在移动设备上测试着色器。
即使在移动端 GPU 上,不同的精度支持也会因 GPU 产品系列而异。
大多数现代移动端 GPU 实际上只支持 32 位数字(用于 float 类型)或 16 位数字(用于 half 和 fixed 类型)。一些较旧的 GPU 对顶点着色器和片元着色器计算具有不同的精度。
使用较低的精度通常可以更快,这可能是由于改进的 GPU 寄存器分配,或是由于某些低精度数学运算的特殊“快速路径”执行单元。即使没有原始性能优势,使用较低的精度通常也会降低 GPU 的功耗,从而延长电池续航时间。
一般的经验法则是全部都从半精度开始(但位置和纹理坐标除外)。仅当半精度对于计算的某些部分不足时,才增加精度。
支持无穷大、非数字和其他特殊浮点值 对特殊浮点值的支持可能会有所不同,具体取决于运行的 GPU 产品系列(主要是移动端)。
支持 Direct3D 10 的所有 PC GPU 都支持非常明确的 IEEE 754 浮点标准。这意味着,在 CPU 上,浮点数的行为与常规编程语言完全相同。
移动端 GPU 的支持程度可能稍有不同。在某些移动端 GPU 中,将零除以零可能会导致 NaN(“非数字”);在其他移动端 GPU 上,它可能会导致无穷大、零或任何其他不明值。务必在目标设备上测试着色器以检查着色器是否受支持。
使用采样器状态
耦合的纹理和采样器
大多数时候,在着色器中采样纹理时,纹理采样状态应该来自纹理设置——本质上,纹理和采样器是耦合在一起的。这是使用
DX9 样式着色器语法时的默认行为: 1
2
3sampler2D _MainTex;
// ...
half4 color = tex2D(_MainTex, uv);
大部分情况下,这是您想要的结果,而且在较旧的图形 API (OpenGL ES) 中,这是唯一受支持的选项。
单独的纹理和采样器
许多图形 API 和 GPU 允许使用比纹理更少的采样器,并且耦合的纹理+采样器语法可能不允许编写更复杂的着色器。例如,Direct3D 11 允许在单个着色器中使用多达 128 个纹理,但最多只能使用 16 个采样器。
Unity 允许使用 DX11 风格的 HLSL 语法来声明纹理和采样器,但需要通过一个特殊的命名约定来让它们匹配:名称为“sampler”+TextureName 格式的采样器将从该纹理中获取采样状态。
以上部分中的着色器代码片段可以用 DX11 风格的 HLSL
语法重写,并且也会执行相同的操作: 1
2
3
4Texture2D _MainTex;
SamplerState sampler_MainTex; //"sampler"+"_MainTex"
// ...
half4 color = _MainTex.Sample(sampler_MainTex, uv);1
2
3
4
5
6
7
8exture2D _MainTex;
Texture2D _SecondTex;
Texture2D _ThirdTex;
SamplerState sampler_MainTex; //"sampler"+"_MainTex"
// ...
half4 color = _MainTex.Sample(sampler_MainTex, uv);
color += _SecondTex.Sample(sampler_MainTex, uv);
color += _ThirdTex.Sample(sampler_MainTex, uv);
Unity
提供了一些着色器宏帮助您使用这种“单独采样器”方法来声明和采样纹理,请参阅内置宏。以上示例可以采用所述的宏重写为下列形式:
1
2
3
4
5
6
7UNITY_DECLARE_TEX2D(_MainTex);
UNITY_DECLARE_TEX2D_NOSAMPLER(_SecondTex);
UNITY_DECLARE_TEX2D_NOSAMPLER(_ThirdTex);
// ...
half4 color = UNITY_SAMPLE_TEX2D(_MainTex, uv);
color += UNITY_SAMPLE_TEX2D_SAMPLER(_SecondTex, _MainTex, uv);
color += UNITY_SAMPLE_TEX2D_SAMPLER(_ThirdTex, _MainTex, uv);
内联采样器状态
除了能识别名为“sampler”+TextureName 的 HLSL SamplerState 对象,Unity
还能识别采样器名称中的某些其他模式。这对于直接在着色器中声明简单硬编码采样状态很有用。例如:
1
2
3
4Texture2D _MainTex;
SamplerState my_point_clamp_sampler;
// ...
half4 color = _MainTex.Sample(my_point_clamp_sampler, uv);
- *“Point”、“Linear”或“Trilinear”(必需)设置纹理过滤模式。
- *“Clamp”、“Repeat”、“Mirror”或“MirrorOnce”(必需)设置纹理包裹模式。可根据每个轴 (UVW) 来指定包裹模式,例如"ClampU_RepeatV"。
- *“Compare”(可选)设置用于深度比较的采样器;与 HLSL SamplerComparisonState 类型和 SampleCmp/SampleCmpLevelZero 函数配合使用。
就像单独的纹理 + 采样器语法一样,某些平台不支持内联采样器状态。目前它们在 Direct3D 11/12 和 Metal 上实现。请注意,大多数移动 GPU/API 不支持“MirrorOnce”纹理环绕模式,并且在不支持时将回退到镜像模式。
着色器加载
默认情况下,Unity 的运行时着色器加载行为如下:
1.当 Unity 加载场景或使用在运行时加载资源功能加载内容时,它会将所有需要的 Shader 对象加载到 CPU 内存。 2.Unity 第一次需要使用着色器变体渲染几何体时,它将该变体的数据传递给图形驱动程序。图形驱动程序在 GPU 上创建该变体的表示,并执行平台所需的任何其他工作。
这种行为的好处是着色器变体没有前期的 GPU 内存使用或加载时间。缺点是第一次使用变体时可能会出现明显的停顿,因为图形驱动程序必须在 GPU 上创建着色器程序并执行任何额外的工作。
预热着色器变体
为避免在性能开销大时出现明显的停顿,Unity 可以要求图形驱动程序在首次需要着色器变体之前创建它们的 GPU 表示形式。这称为预热。 警告:在选择如何执行预热之前,请查看有关图形 API 支持的说明。在 DX12、Vulkan 和 Metal 等现代图形 API 上,只有实验性的 ShaderWarmup API 完全支持,因为它允许您指定顶点格式。
您可以按照以下方式执行预热:
- 使用实验性 ShaderWarmup API 预热给定的 Shader 对象或着色器变体集合。
- 在应用程序启动时预热着色器变体集合,方法是将它们添加到 Preloaded shaders section of the Graphics Settings 窗口。
- 使用 ShaderVariantCollection.WarmUp API 预热着色器变体集合。
- 使用 Shader.WarmupAllShaders API 预热当前内存中的所有 Shader 对象的所有变体。
用于着色器加载的性能分析器标记
性能分析器标记 Shader.Parse 用于表示 Unity 将创建的着色器变量数据表示发送到 GPU。性能分析器标记 CreateGPUProgram 用于表示将着色器程序上传到 GPU 并等待 GPU 执行任何所需工作。
平台差异
在某些情况下,不同图形 API 之间的图形渲染行为方式存在差异。大多数情况下,Unity 编辑器会隐藏这些差异,但在某些情况下,编辑器无法为您执行此操作。下面列出了这些情况以及发生这些情况时需要采取的操作。
渲染纹理坐标
垂直纹理坐标约定在两种类型的平台之间有所不同,分别是 Direct3D 类和 OpenGL 类平台。
- Direct3D 类:顶部坐标为 0 并向下增加。此类型适用于 Direct3D、Metal 和游戏主机。
- OpenGL 类:底部坐标为 0 并向上增加。此类适用于 OpenGL 和 OpenGL ES。
除了渲染到渲染纹理的情况下,这种差异不会对您的项目产生任何影响。在 Direct3D 类平台上渲染到纹理时,Unity 会在内部上下翻转渲染。这样就会使坐标约定在平台之间匹配,并以 OpenGL 类平台约定作为标准。
在着色器中,有两种常见情况需要您采取操作确保不同的坐标约定不会在项目中产生问题,这两种情况就是图像效果和 UV 空间中的渲染。
图像效果
使用图像效果(OnRenderImage)和抗锯齿时,系统不会翻转为图像效果生成的源纹理来匹配OpenGL类平台约定。在这种情况下,Unity渲染到屏幕以获得抗锯齿效果,然后将渲染解析为渲染纹理,以便通过图像效果进行进一步处理。
如果您的图像效果是一次处理一个渲染纹理的简单图像效果,则Graphics.Blit会处理不一致的坐标。但是,如果您在图像效果中一起处理多个渲染纹理,则在Direct3D类平台中以及在您使用抗锯齿时,渲染纹理很可能以不同的垂直方向出现。要标准化坐标,必须在顶点着色器中手动上下“翻转”屏幕纹理,使其与OpenGL类坐标标准匹配。
以下代码示例演示了如何执行此操作: 1
2
3
4
5
6
7
8// 翻转纹理的采样:
// 主纹理的
// 纹理像素大小将具有负 Y。
# if UNITY_UV_STARTS_AT_TOP
if (_MainTex_TexelSize.y < 0)
uv.y = 1-uv.y;
# endif
在UV空间中渲染
在纹理坐标 (UV) 空间中渲染特殊效果或工具时,您可能需要调整着色器,以便在 Direct3D 类和 OpenGL 类系统之间进行一致渲染。您还可能需要在渲染到屏幕和渲染到纹理之间进行渲染调整。为进行此类调整,应上下翻转 Direct3D 类投影,使其坐标与 OpenGL 类投影坐标相匹配。
内置变量 ProjectionParams.x 包含值 +1 或 –1。-1 表示投影已上下翻转以匹配 OpenGL 类投影坐标,而 +1 表示尚未翻转。 您可以在着色器中检查此值,然后执行不同的操作。下面的示例将检查是否已翻转投影,如果已翻转,则再次进行翻转,然后返回 UV 坐标以便匹配。
1 | float4 vert(float2 uv : TEXCOORD0) : SV_POSITION |
裁剪空间坐标
与纹理坐标类似,裁剪空间坐标(也称为投影后空间坐标)在 Direct3D 类和 OpenGL 类平台之间有所不同:
- Direct3D 类:裁剪空间深度从近平面的 +1.0 到远平面的 0.0。此类型适用于 Direct3D、Metal 和游戏主机。
- OpenGL 类:裁剪空间深度从近平面的 –1.0 到远平面的 +1.0。此类适用于 OpenGL 和 OpenGL ES。
在着色器代码内,可使用内置宏 UNITY_NEAR_CLIP_VALUE 来获取基于平台的近平面值。 在脚本代码内,使用 GL.GetGPUProjectionMatrix 将 Unity 的坐标系(遵循 OpenGL 类约定)转换为 Direct3D 类坐标(如果这是平台所期望的)。
着色器计算的精度
要避免精度问题,请确保在目标平台上测试着色器。移动设备和 PC 中的 GPU 在处理浮点类型方面有所不同。PC GPU 将所有浮点类型(浮点精度、半精度和固定精度)视为相同;PC GPU 使用完整 32 位精度进行所有计算,而许多移动设备 GPU 并不是这样做。
着色器中的 const 声明
const 的使用在 Microsoft HSL(请参阅 msdn.microsoft.com)和 OpenGL 的 GLSL(请参阅 Wikipedia)着色器语言之间有所不同。
- Microsoft 的 HLSL const 与 C# 和 C++ 中的含义大致相同:声明的变量在其作用域内是只读的,但可按任何方式初始化。
- OpenGL 的 GLSL const 表示变量实际上是编译时常量,因此必须使用编译时约束(文字值或其他对于 const 的计算)进行初始化。
最好是遵循 OpenGL 的 GLSL 语义,并且只有当变量真正不变时才将变量声明为 const。避免使用其他一些可变值初始化 const 变量(例如,作为函数中的局部变量)。这一原则也适用于 Microsoft 的 HLSL,因此以这种方式使用 const 可以避免在某些平台上混淆错误。
着色器使用的语义
要让着色器在所有平台上运行,一些着色器值应该使用以下语义:
- 顶点着色器输出(裁剪空间)位置:SV_POSITION。有时,着色器使用 POSITION 语义来使着色器在所有平台上运行。请注意,这不适用于 Sony PS4 或有曲面细分的情况。
- 片元着色器输出颜色:SV_Target。有时,着色器使用COLOR或COLOR0来使着色器在所有平台上运行。请注意,这不适用于 Sony PS4。
将网格渲染为点时,从顶点着色器输出 PSIZE 语义(例如,将其设置为 1)。某些平台(如 OpenGL ES 或 Metal)在未从着色器写入点大小时会将点大小视为“未定义”。
Direct3D着色器编译器语法
Direct3D 平台使用 Microsoft 的 HLSL 着色器编译器。对于各种细微的着色器错误,HLSL 编译器比其他编译器更严格。例如,它不接受未正确初始化的函数输出值。
使用此编译器时,您可能遇到的最常见情况是:
- 部分初始化的值。例如,函数返回 float4,但代码只设置它的.xyz 值。如果只需要三个值,请设置所有值或更改为 float3。
- 在顶点着色器中使用 tex2D。这是无效的,因为顶点着色器中不存在 UV 导数。这种情况下,您需要采样显式 Mip 级别;例如,使用 tex2Dlod (tex, float4(uv,0,0))。此外,还需要添加 #pragma target 3.0,因为 tex2Dlod 是着色器模型 3.0 的功能。
使用着色器帧缓冲提取
一些 GPU(最明显的是 iOS 上基于 PowerVR 的 GPU)允许您通过提供当前片元颜色作为片元着色器的输入来进行某种可编程混合(请参阅 khronos.org 上的 EXT_shader_framebuffer_fetch)。
可在 Unity 中编写使用帧缓冲提取功能的着色器。要执行此操作,请在使用 HLSL(Microsoft 的着色语言,请参阅 msdn.microsoft.com)或 Cg(Nvidia 的着色语言,请参阅 nvidia.co.uk)编写片元着色器时使用 inout 颜色参数。
以下示例采用的是 Cg 语言。 1
2
3
4
5
6
7
8
9
10
11
12CGPROGRAM
// 只为可能支持该功能的平台(目前是 gles、gles3 和 metal)
// 编译着色器
# pragma only_renderers framebufferfetch
void frag (v2f i, inout half4 ocol : SV_Target)
{
// ocol 可以被读取(当前帧缓冲区颜色)
// 并且可以被写入(将颜色更改为该颜色)
// ...
}
ENDCG
着色器中的深度 (Z) 方向
深度 (Z) 方向在不同的着色器平台上不同。
DirectX 11, DirectX 12, Metal: 反转方向
- 深度 (Z) 缓冲区在近平面处为 1.0,在远平面处减小到 0.0。
- 裁剪空间范围是 [near,0](表示近平面处的近平面距离,在远平面处减小到 0.0)。
其他平台:传统方向
- 深度 (Z) 缓冲区值在近平面处为 0.0,在远平面处为 1.0。
- 裁剪空间取决于具体平台:
- 在 Direct3D 类平台上,范围是 [0,far](表示在近平面处为 0.0,在远平面处增加到远平面距离)。
- 在 OpenGL 类平台上,范围是 [-near,far](表示在近平面处为负的近平面距离,在远平面处增加到远平面距离)。
请注意,使反转方向深度 (Z) 与浮点深度缓冲区相结合,可显著提高相对于传统方向的深度缓冲区精度。这样做的优点是降低 Z 坐标的冲突并改善阴影,特别是在使用小的近平面和大的远平面时。
因此,在使用深度 (Z) 发生反转的平台上的着色器时:
- 定义了 UNITY_REVERSED_Z。
- _CameraDepth 纹理的纹理范围是 1(近平面)到 0(远平面)。
- 裁剪空间范围是“near”(近平面)到 0(远平面)。
但是,以下宏和函数会自动计算出深度 (Z) 方向的任何差异: - Linear01Depth(float z) - LinearEyeDepth(float z) - UNITY_CALC_FOG_FACTOR(coord)
提取深度缓冲区
如果要手动提取深度 (Z)
缓冲区值,则可能需要检查缓冲区方向。以下是执行此操作的示例:
1
2
3
4float z = tex2D(_CameraDepthTexture, uv);
# if defined(UNITY_REVERSED_Z)
z = 1.0f - z;
# endif
使用裁剪空间
如果要手动使用裁剪空间 (Z) 深度,则可能还需要使用以下宏来抽象化平台差异: float clipSpaceRange01 = UNITY_Z_0_FAR_FROM_CLIPSPACE(rawClipSpace);
注意:此宏不会改变 OpenGL 或 OpenGL ES 平台上的裁剪空间,因此在这些平台上,此宏返回“-near”1(近平面)到 far(远平面)之间的值。
投影矩阵
如果处于深度 (Z) 发生反转的平台上,则 GL.GetGPUProjectionMatrix()
返回一个还原了 z 的矩阵。
但是,如果要手动从投影矩阵中进行合成(例如,对于自定义阴影或深度渲染),您需要通过脚本按需自行还原深度
(Z) 方向。 以下是执行此操作的示例: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var shadowProjection = Matrix4x4.Ortho(...); //阴影摄像机投影矩阵
var shadowViewMat = ... //阴影摄像机视图矩阵
var shadowSpaceMatrix = ... //从裁剪空间到阴影贴图纹理空间
//当引擎通过摄像机投影计算设备投影矩阵时,
//"m_shadowCamera.projectionMatrix"被隐式反转
m_shadowCamera.projectionMatrix = shadowProjection;
//"shadowProjection"在连接到"m_shadowMatrix"之前被手动翻转,
//因为它被视为着色器的其他矩阵。
if(SystemInfo.usesReversedZBuffer)
{
shadowProjection[2, 0] = -shadowProjection[2, 0];
shadowProjection[2, 1] = -shadowProjection[2, 1];
shadowProjection[2, 2] = -shadowProjection[2, 2];
shadowProjection[2, 3] = -shadowProjection[2, 3];
}
m_shadowMatrix = shadowSpaceMatrix * shadowProjection * shadowViewMat;
深度 (Z) 偏差
Unity自动处理深度(Z)偏差,以确保其与Unity的深度(Z)方向匹配。但是,如果要使用本机代码渲染插件,则需要在C或C++代码中消除(反转)深度(Z)偏差。
深度 (Z) 方向检查工具
- 使用SystemInfo.usesReversedZBuffer可确认所在平台是否使用反转深度(Z)。
性能分析与调试
优化着色器运行时性能
不同的平台具有截然不同的性能;与低端移动端 GPU 相比,高端 PC GPU 在图形和着色器方面的处理能力要高得多。即使在单一平台上也是如此;快速的 GPU 比慢速的集成 GPU 快几十倍。 移动平台和低端 PC 上的 GPU 性能可能远低于您的开发机器上的性能。 建议您手动优化着色器以减少计算和纹理读取,以便在低端 GPU 机器上获得良好的性能。
仅执行所需的计算
着色器代码需要执行的计算和处理越多,它对游戏性能的影响就越大。例如,支持每种材质的颜色可以使着色器更加灵活,但如果始终将该颜色设置为白色,则会对屏幕上渲染的每个顶点或像素执行无用的计算。 计算的频率也会影响游戏的性能。通常,与顶点数(顶点着色器执行次数)相比,渲染的像素数会更多(因此像素着色器执行次数也更多),而渲染的顶点数比渲染的对象更多。在可能的情况下,可将计算从像素着色器代码移动到顶点着色器代码中,或者将它们完全移出着色器并在脚本中设置值。
计算的精度
用 Cg/HLSL 编写着色器时,有三种基本数字类型:float、half 和 fixed。好的性能总是应该尽可能的使用更低的精度。这在低端设备上特别重要。好的经验法则是:
- 对于世界空间位置和纹理坐标,请使用 float 精度。
- 对于所有其他情况(矢量、HDR 颜色等),请首先尝试half精度。仅在必要的情况下再提高精度。
- 要对纹理数据进行非常简单的运算,请使用fixed精度。
实际上,具体应该使用哪种数字类型取决于平台和GPU。一般来说: - 所有新款的桌面端GPU将始终以完整float精度进行所有计算,因此float/half/fixed最终产生完全相同的结果。这可能会使测试变得困难,因为更难以确定half/fixed精度是否真正够用,因此请始终在目标设备上测试着色器以获得准确的结果。 - 移动端GPU实际支持half精度。这种精度通常速度更快,并且使用更少的性能来执行计算。 - Fixed精度通常仅对于较旧的移动端GPU有用。大部分新款GPU(可运行 OpenGL ES 3 或 Metal的GPU)在内部以相同方式来处理fixed和half精度。
复杂的数学计算
复杂的数学函数(例如 pow、exp、log、cos、sin、tan)非常耗费资源,因此请尽可能避免在低端硬件上使用它们。 如果适用,请考虑使用查找纹理作为复杂数学计算的替代方法。 避免编写自己的运算(如 normalize、dot、inversesqrt)。Unity 的内置选项确保驱动程序可以生成好得多的代码。请记住,Alpha 测试 (discard) 运算通常会使片元着色器变慢。
Alpha测试
固定函数 AlphaTest(或者其可编程的等效函数 clip())在不同平台上具有不同的性能特征:
- 通常,在使用该函数来移除大多数平台上的完全透明像素时,可获得少量优势。
- 但是,在iOS和某些Android设备的PowerVR GPU上,Alpha测试是资源密集型任务。不要试图在这些平台上使用这种测试进行性能优化,因为它会导致游戏运行速度比平常慢。
颜色遮罩(Color Mask)
在某些平台(主要是 iOS 和 Android 设备的移动端 GPU)上,使用 ColorMask 省略一些通道(例如 ColorMask RGB)可能是资源密集型的操作,所以除非绝对需要,否则请不要使用。